 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActionEngine: From Reactive to Programmatic GUI Agents via State Machine Memory
Feb 24, 2026Existing Graphical User Interface (GUI) agents operate through step-by-step calls to vision language models--taking a screenshot, reasoning about the next action, executing it, then repeating on the new page--resulting in high costs and latency that scale with the number of reasoning steps, and limited accuracy due to no persistent memory of previously visited pages. We propose ActionEngine, a training-free framework that transitions from reactive execution to programmatic planning through a novel two-agent architecture: a Crawling Agent that constructs an updatable state-machine memory of the GUIs through offline exploration, and an Execution Agent that leverages this memory to synthesize complete, executable Python programs for online task execution. To ensure robustness against evolving interfaces, execution failures trigger a vision-based re-grounding fallback that repairs the failed action and updates the memory. This design drastically improves both efficiency and accuracy: on Reddit tasks from the WebArena benchmark, our agent achieves 95% task success with on average a single LLM call, compared to 66% for the strongest vision-only baseline, while reducing cost by 11.8x and end-to-end latency by 2x. Together, these components yield scalable and reliable GUI interaction by combining global programmatic planning, crawler-validated action templates, and node-level execution with localized validation and repair.
HoneyBee: Efficient Role-based Access Control for Vector Databases via Dynamic Partitioning
May 02, 2025



As vector databases gain traction in enterprise applications, robust access control has become critical to safeguard sensitive data. Access control in these systems is often implemented through hybrid vector queries, which combine nearest neighbor search on vector data with relational predicates based on user permissions. However, existing approaches face significant trade-offs: creating dedicated indexes for each user minimizes query latency but introduces excessive storage redundancy, while building a single index and applying access control after vector search reduces storage overhead but suffers from poor recall and increased query latency. This paper introduces HoneyBee, a dynamic partitioning framework that bridges the gap between these approaches by leveraging the structure of Role-Based Access Control (RBAC) policies. RBAC, widely adopted in enterprise settings, groups users into roles and assigns permissions to those roles, creating a natural "thin waist" in the permission structure that is ideal for partitioning decisions. Specifically, HoneyBee produces overlapping partitions where vectors can be strategically replicated across different partitions to reduce query latency while controlling storage overhead. By introducing analytical models for the performance and recall of the vector search, HoneyBee formulates the partitioning strategy as a constrained optimization problem to dynamically balance storage, query efficiency, and recall. Evaluations on RBAC workloads demonstrate that HoneyBee reduces storage redundancy compared to role partitioning and achieves up to 6x faster query speeds than row-level security (RLS) with only 1.4x storage increase, offering a practical middle ground for secure and efficient vector search.
A Socratic RAG Approach to Connect Natural Language Queries on Research Topics with Knowledge Organization Systems
Feb 20, 2025In this paper, we propose a Retrieval Augmented Generation (RAG) agent that maps natural language queries about research topics to precise, machine-interpretable semantic entities. Our approach combines RAG with Socratic dialogue to align a user's intuitive understanding of research topics with established Knowledge Organization Systems (KOSs). The proposed approach will effectively bridge "little semantics" (domain-specific KOS structures) with "big semantics" (broad bibliometric repositories), making complex academic taxonomies more accessible. Such agents have the potential for broad use. We illustrate with a sample application called CollabNext, which is a person-centric knowledge graph connecting people, organizations, and research topics. We further describe how the application design has an intentional focus on HBCUs and emerging researchers to raise visibility of people historically rendered invisible in the current science system.
SketchQL Demonstration: Zero-shot Video Moment Querying with Sketches
May 28, 2024
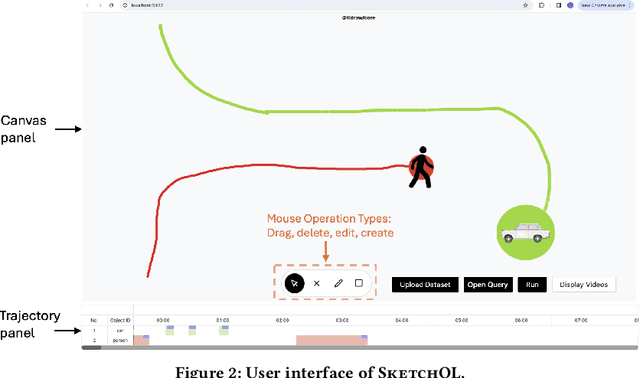
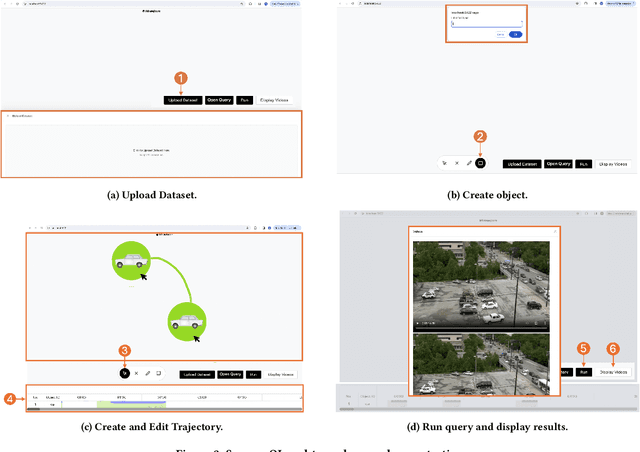
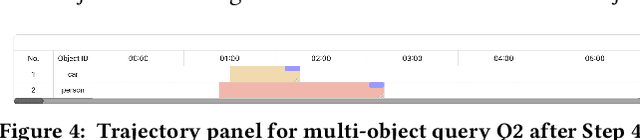
In this paper, we will present SketchQL, a video database management system (VDBMS) for retrieving video moments with a sketch-based query interface. This novel interface allows users to specify object trajectory events with simple mouse drag-and-drop operations. Users can use trajectories of single objects as building blocks to compose complex events. Using a pre-trained model that encodes trajectory similarity, SketchQL achieves zero-shot video moments retrieval by performing similarity searches over the video to identify clips that are the most similar to the visual query. In this demonstration, we introduce the graphic user interface of SketchQL and detail its functionalities and interaction mechanisms. We also demonstrate the end-to-end usage of SketchQL from query composition to video moments retrieval using real-world scenarios.
Dynamic Data Layout Optimization with Worst-case Guarantees
May 08, 2024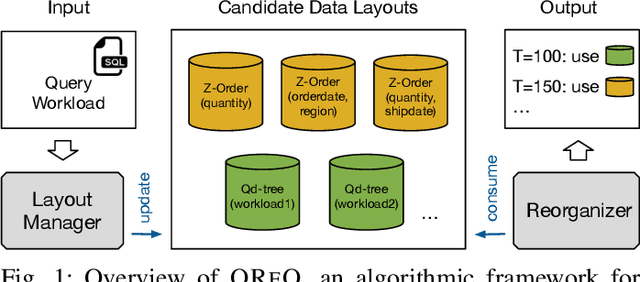
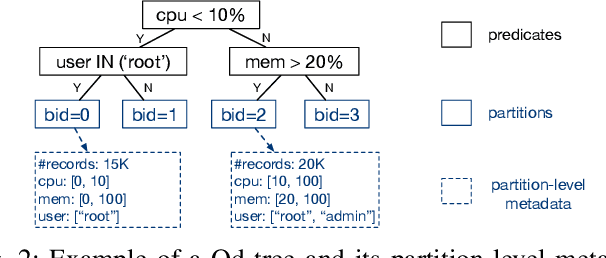
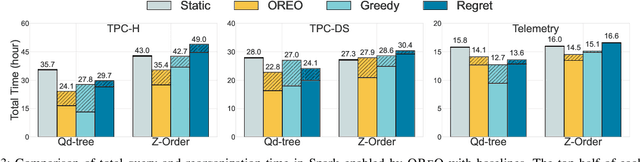
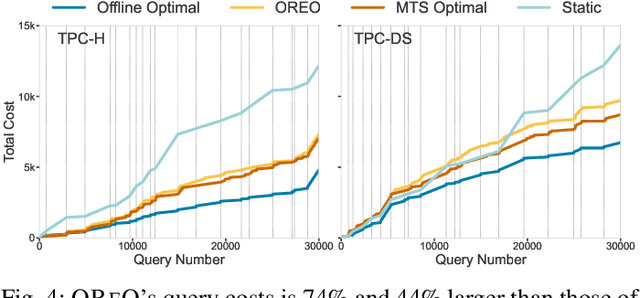
Many data analytics systems store and process large datasets in partitions containing millions of rows. By mapping rows to partitions in an optimized way, it is possible to improve query performance by skipping over large numbers of irrelevant partitions during query processing. This mapping is referred to as a data layout. Recent works have shown that customizing the data layout to the anticipated query workload greatly improves query performance, but the performance benefits may disappear if the workload changes. Reorganizing data layouts to accommodate workload drift can resolve this issue, but reorganization costs could exceed query savings if not done carefully. In this paper, we present an algorithmic framework OReO that makes online reorganization decisions to balance the benefits of improved query performance with the costs of reorganization. Our framework extends results from Metrical Task Systems to provide a tight bound on the worst-case performance guarantee for online reorganization, without prior knowledge of the query workload. Through evaluation on real-world datasets and query workloads, our experiments demonstrate that online reorganization with OReO can lead to an up to 32% improvement in combined query and reorganization time compared to using a single, optimized data layout for the entire workload.
Falcon: Fair Active Learning using Multi-armed Bandits
Jan 24, 2024



Biased data can lead to unfair machine learning models, highlighting the importance of embedding fairness at the beginning of data analysis, particularly during dataset curation and labeling. In response, we propose Falcon, a scalable fair active learning framework. Falcon adopts a data-centric approach that improves machine learning model fairness via strategic sample selection. Given a user-specified group fairness measure, Falcon identifies samples from "target groups" (e.g., (attribute=female, label=positive)) that are the most informative for improving fairness. However, a challenge arises since these target groups are defined using ground truth labels that are not available during sample selection. To handle this, we propose a novel trial-and-error method, where we postpone using a sample if the predicted label is different from the expected one and falls outside the target group. We also observe the trade-off that selecting more informative samples results in higher likelihood of postponing due to undesired label prediction, and the optimal balance varies per dataset. We capture the trade-off between informativeness and postpone rate as policies and propose to automatically select the best policy using adversarial multi-armed bandit methods, given their computational efficiency and theoretical guarantees. Experiments show that Falcon significantly outperforms existing fair active learning approaches in terms of fairness and accuracy and is more efficient. In particular, only Falcon supports a proper trade-off between accuracy and fairness where its maximum fairness score is 1.8-4.5x higher than the second-best results.
Computing in the Era of Large Generative Models: From Cloud-Native to AI-Native
Jan 17, 2024

In this paper, we investigate the intersection of large generative AI models and cloud-native computing architectures. Recent large models such as ChatGPT, while revolutionary in their capabilities, face challenges like escalating costs and demand for high-end GPUs. Drawing analogies between large-model-as-a-service (LMaaS) and cloud database-as-a-service (DBaaS), we describe an AI-native computing paradigm that harnesses the power of both cloud-native technologies (e.g., multi-tenancy and serverless computing) and advanced machine learning runtime (e.g., batched LoRA inference). These joint efforts aim to optimize costs-of-goods-sold (COGS) and improve resource accessibility. The journey of merging these two domains is just at the beginning and we hope to stimulate future research and development in this area.
DiffPrep: Differentiable Data Preprocessing Pipeline Search for Learning over Tabular Data
Aug 20, 2023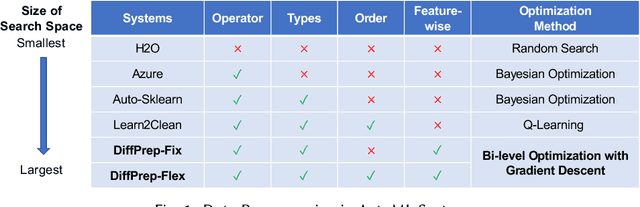
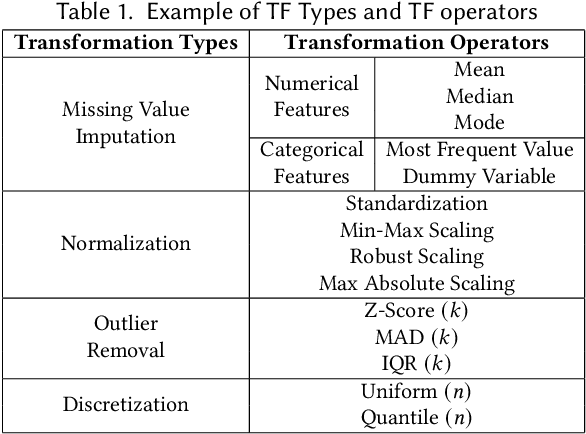


Data preprocessing is a crucial step in the machine learning process that transforms raw data into a more usable format for downstream ML models. However, it can be costly and time-consuming, often requiring the expertise of domain experts. Existing automated machine learning (AutoML) frameworks claim to automate data preprocessing. However, they often use a restricted search space of data preprocessing pipelines which limits the potential performance gains, and they are often too slow as they require training the ML model multiple times. In this paper, we propose DiffPrep, a method that can automatically and efficiently search for a data preprocessing pipeline for a given tabular dataset and a differentiable ML model such that the performance of the ML model is maximized. We formalize the problem of data preprocessing pipeline search as a bi-level optimization problem. To solve this problem efficiently, we transform and relax the discrete, non-differential search space into a continuous and differentiable one, which allows us to perform the pipeline search using gradient descent with training the ML model only once. Our experiments show that DiffPrep achieves the best test accuracy on 15 out of the 18 real-world datasets evaluated and improves the model's test accuracy by up to 6.6 percentage points.
* Published at SIGMOD 2023
Rethinking Similarity Search: Embracing Smarter Mechanisms over Smarter Data
Aug 02, 2023



In this vision paper, we propose a shift in perspective for improving the effectiveness of similarity search. Rather than focusing solely on enhancing the data quality, particularly machine learning-generated embeddings, we advocate for a more comprehensive approach that also enhances the underpinning search mechanisms. We highlight three novel avenues that call for a redefinition of the similarity search problem: exploiting implicit data structures and distributions, engaging users in an iterative feedback loop, and moving beyond a single query vector. These novel pathways have gained relevance in emerging applications such as large-scale language models, video clip retrieval, and data labeling. We discuss the corresponding research challenges posed by these new problem areas and share insights from our preliminary discoveries.
DynaQuant: Compressing Deep Learning Training Checkpoints via Dynamic Quantization
Jun 20, 2023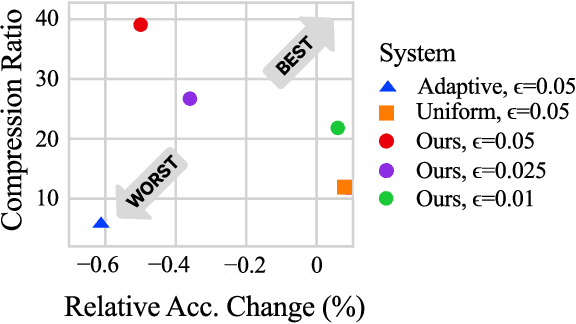

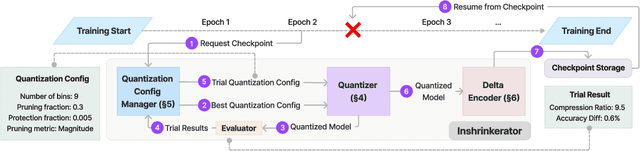
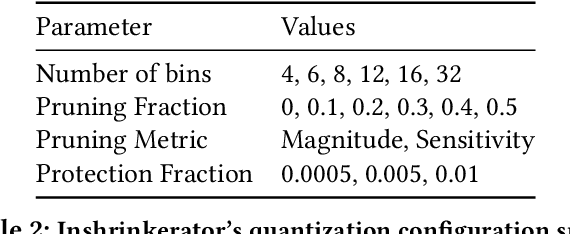
With the increase in the scale of Deep Learning (DL) training workloads in terms of compute resources and time consumption, the likelihood of encountering in-training failures rises substantially, leading to lost work and resource wastage. Such failures are typically offset by a checkpointing mechanism, which comes at the cost of storage and network bandwidth overhead. State-of-the-art approaches involve lossy model compression mechanisms, which induce a tradeoff between the resulting model quality (accuracy) and compression ratio. Delta compression is then also used to further reduce the overhead by only storing the difference between consecutive checkpoints. We make a key enabling observation that the sensitivity of model weights to compression varies during training, and different weights benefit from different quantization levels (ranging from retaining full precision to pruning). We propose (1) a non-uniform quantization scheme that leverages this variation, (2) an efficient search mechanism to dynamically adjust to the best quantization configurations, and (3) a quantization-aware delta compression mechanism that rearranges weights to minimize checkpoint differences, thereby maximizing compression. We instantiate these contributions in DynaQuant - a framework for DL workload checkpoint compression. Our experiments show that DynaQuant consistently achieves better tradeoff between accuracy and compression ratios compared to prior works, enabling a compression ratio up to 39x and withstanding up to 10 restores with negligible accuracy impact for fault-tolerant training. DynaQuant achieves at least an order of magnitude reduction in checkpoint storage overhead for training failure recovery as well as transfer learning use cases without any loss of accuracy