 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSketchQL Demonstration: Zero-shot Video Moment Querying with Sketches
May 28, 2024
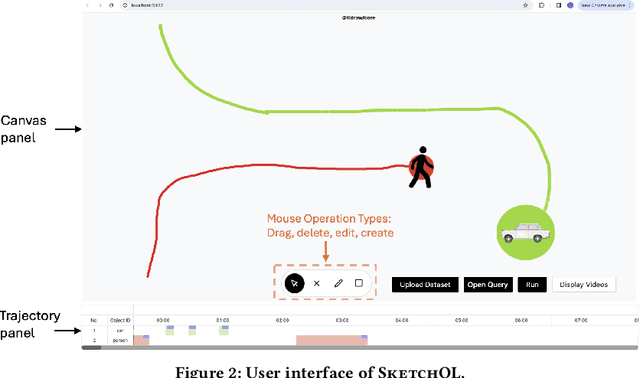
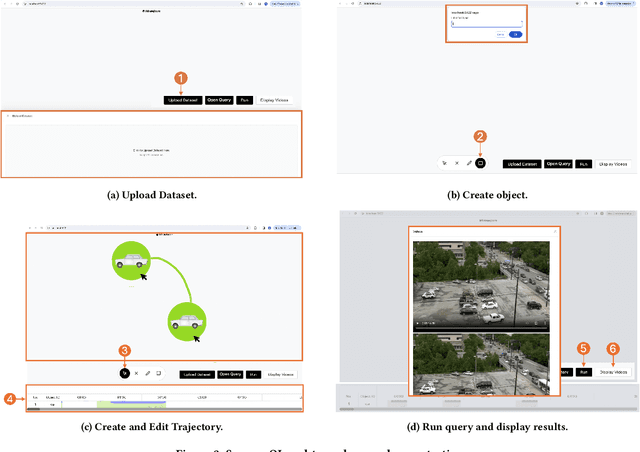
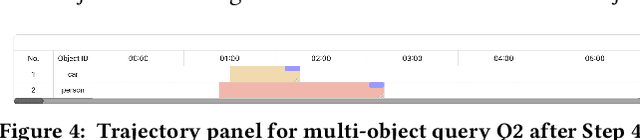
In this paper, we will present SketchQL, a video database management system (VDBMS) for retrieving video moments with a sketch-based query interface. This novel interface allows users to specify object trajectory events with simple mouse drag-and-drop operations. Users can use trajectories of single objects as building blocks to compose complex events. Using a pre-trained model that encodes trajectory similarity, SketchQL achieves zero-shot video moments retrieval by performing similarity searches over the video to identify clips that are the most similar to the visual query. In this demonstration, we introduce the graphic user interface of SketchQL and detail its functionalities and interaction mechanisms. We also demonstrate the end-to-end usage of SketchQL from query composition to video moments retrieval using real-world scenarios.
Hydro: Adaptive Query Processing of ML Queries
Mar 22, 2024Query optimization in relational database management systems (DBMSs) is critical for fast query processing. The query optimizer relies on precise selectivity and cost estimates to effectively optimize queries prior to execution. While this strategy is effective for relational DBMSs, it is not sufficient for DBMSs tailored for processing machine learning (ML) queries. In ML-centric DBMSs, query optimization is challenging for two reasons. First, the performance bottleneck of the queries shifts to user-defined functions (UDFs) that often wrap around deep learning models, making it difficult to accurately estimate UDF statistics without profiling the query. This leads to inaccurate statistics and sub-optimal query plans. Second, the optimal query plan for ML queries is data-dependent, necessitating DBMSs to adapt the query plan on the fly during execution. So, a static query plan is not sufficient for such queries. In this paper, we present Hydro, an ML-centric DBMS that utilizes adaptive query processing (AQP) for efficiently processing ML queries. Hydro is designed to quickly evaluate UDF-based query predicates by ensuring optimal predicate evaluation order and improving the scalability of UDF execution. By integrating AQP, Hydro continuously monitors UDF statistics, routes data to predicates in an optimal order, and dynamically allocates resources for evaluating predicates. We demonstrate Hydro's efficacy through four illustrative use cases, delivering up to 11.52x speedup over a baseline system.
Zeus: Efficiently Localizing Actions in Videos using Reinforcement Learning
Apr 19, 2021
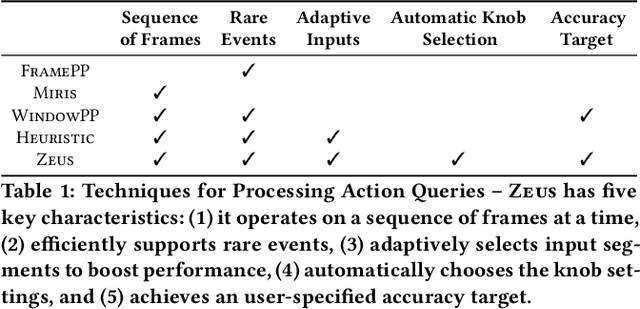
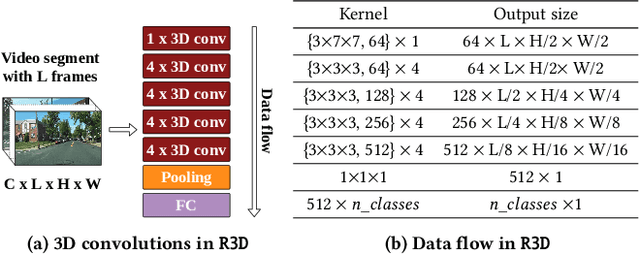
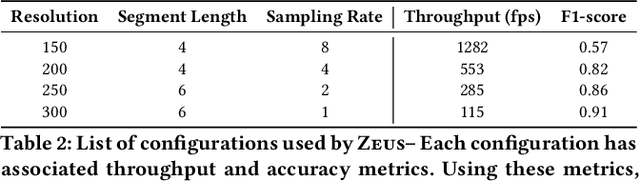
Detection and localization of actions in videos is an important problem in practice. A traffic analyst might be interested in studying the patterns in which vehicles move at a given intersection. State-of-the-art video analytics systems are unable to efficiently and effectively answer such action queries. The reasons are threefold. First, action detection and localization tasks require computationally expensive deep neural networks. Second, actions are often rare events. Third, actions are spread across a sequence of frames. It is important to take the entire sequence of frames into context for effectively answering the query. It is critical to quickly skim through the irrelevant parts of the video to answer the action query efficiently. In this paper, we present Zeus, a video analytics system tailored for answering action queries. We propose a novel technique for efficiently answering these queries using a deep reinforcement learning agent. Zeus trains an agent that learns to adaptively modify the input video segments to an action classification network. The agent alters the input segments along three dimensions -- sampling rate, segment length, and resolution. Besides efficiency, Zeus is capable of answering the query at a user-specified target accuracy using a query optimizer that trains the agent based on an accuracy-aware reward function. Our evaluation of Zeus on a novel action localization dataset shows that it outperforms the state-of-the-art frame- and window-based techniques by up to 1.4x and 3x, respectively. Furthermore, unlike the frame-based technique, it satisfies the user-specified target accuracy across all the queries, at up to 2x higher accuracy, than frame-based methods.
ODIN: Automated Drift Detection and Recovery in Video Analytics
Sep 09, 2020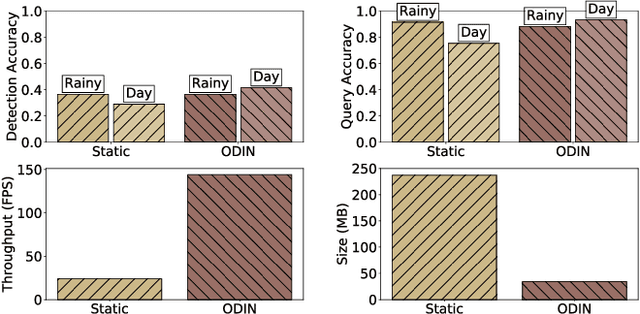

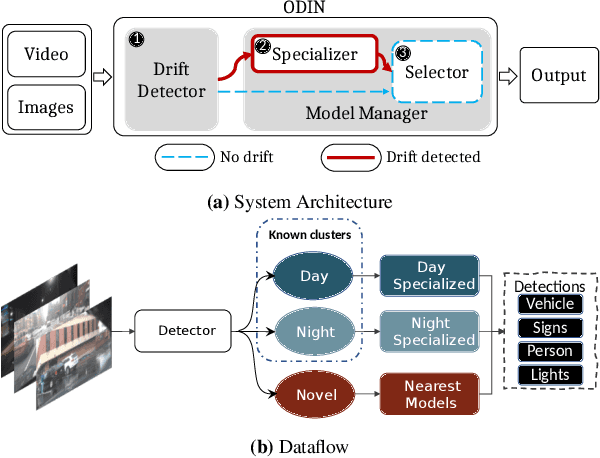
Recent advances in computer vision have led to a resurgence of interest in visual data analytics. Researchers are developing systems for effectively and efficiently analyzing visual data at scale. A significant challenge that these systems encounter lies in the drift in real-world visual data. For instance, a model for self-driving vehicles that is not trained on images containing snow does not work well when it encounters them in practice. This drift phenomenon limits the accuracy of models employed for visual data analytics. In this paper, we present a visual data analytics system, called ODIN, that automatically detects and recovers from drift. ODIN uses adversarial autoencoders to learn the distribution of high-dimensional images. We present an unsupervised algorithm for detecting drift by comparing the distributions of the given data against that of previously seen data. When ODIN detects drift, it invokes a drift recovery algorithm to deploy specialized models tailored towards the novel data points. These specialized models outperform their non-specialized counterpart on accuracy, performance, and memory footprint. Lastly, we present a model selection algorithm for picking an ensemble of best-fit specialized models to process a given input. We evaluate the efficacy and efficiency of ODIN on high-resolution dashboard camera videos captured under diverse environments from the Berkeley DeepDrive dataset. We demonstrate that ODIN's models deliver 6x higher throughput, 2x higher accuracy, and 6x smaller memory footprint compared to a baseline system without automated drift detection and recovery.