 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZeus: Efficiently Localizing Actions in Videos using Reinforcement Learning
Apr 19, 2021
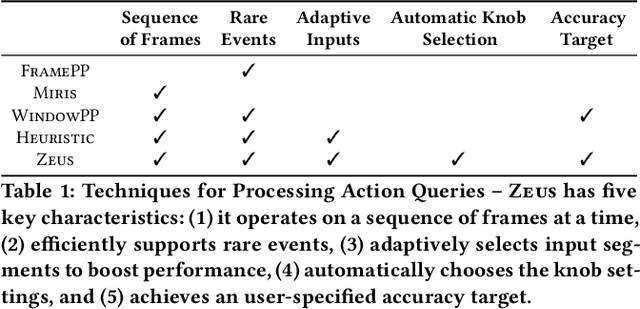
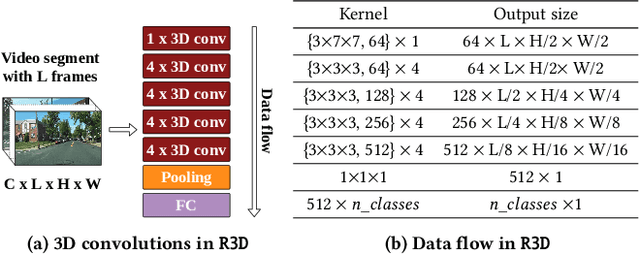
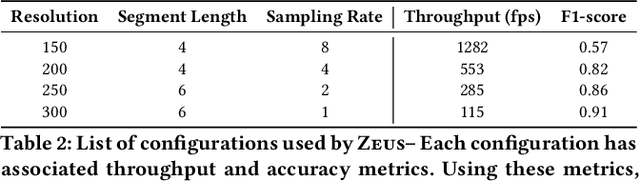
Detection and localization of actions in videos is an important problem in practice. A traffic analyst might be interested in studying the patterns in which vehicles move at a given intersection. State-of-the-art video analytics systems are unable to efficiently and effectively answer such action queries. The reasons are threefold. First, action detection and localization tasks require computationally expensive deep neural networks. Second, actions are often rare events. Third, actions are spread across a sequence of frames. It is important to take the entire sequence of frames into context for effectively answering the query. It is critical to quickly skim through the irrelevant parts of the video to answer the action query efficiently. In this paper, we present Zeus, a video analytics system tailored for answering action queries. We propose a novel technique for efficiently answering these queries using a deep reinforcement learning agent. Zeus trains an agent that learns to adaptively modify the input video segments to an action classification network. The agent alters the input segments along three dimensions -- sampling rate, segment length, and resolution. Besides efficiency, Zeus is capable of answering the query at a user-specified target accuracy using a query optimizer that trains the agent based on an accuracy-aware reward function. Our evaluation of Zeus on a novel action localization dataset shows that it outperforms the state-of-the-art frame- and window-based techniques by up to 1.4x and 3x, respectively. Furthermore, unlike the frame-based technique, it satisfies the user-specified target accuracy across all the queries, at up to 2x higher accuracy, than frame-based methods.