 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHydro: Adaptive Query Processing of ML Queries
Mar 22, 2024Query optimization in relational database management systems (DBMSs) is critical for fast query processing. The query optimizer relies on precise selectivity and cost estimates to effectively optimize queries prior to execution. While this strategy is effective for relational DBMSs, it is not sufficient for DBMSs tailored for processing machine learning (ML) queries. In ML-centric DBMSs, query optimization is challenging for two reasons. First, the performance bottleneck of the queries shifts to user-defined functions (UDFs) that often wrap around deep learning models, making it difficult to accurately estimate UDF statistics without profiling the query. This leads to inaccurate statistics and sub-optimal query plans. Second, the optimal query plan for ML queries is data-dependent, necessitating DBMSs to adapt the query plan on the fly during execution. So, a static query plan is not sufficient for such queries. In this paper, we present Hydro, an ML-centric DBMS that utilizes adaptive query processing (AQP) for efficiently processing ML queries. Hydro is designed to quickly evaluate UDF-based query predicates by ensuring optimal predicate evaluation order and improving the scalability of UDF execution. By integrating AQP, Hydro continuously monitors UDF statistics, routes data to predicates in an optimal order, and dynamically allocates resources for evaluating predicates. We demonstrate Hydro's efficacy through four illustrative use cases, delivering up to 11.52x speedup over a baseline system.
VEGETA: Vertically-Integrated Extensions for Sparse/Dense GEMM Tile Acceleration on CPUs
Feb 23, 2023



Deep Learning (DL) acceleration support in CPUs has recently gained a lot of traction, with several companies (Arm, Intel, IBM) announcing products with specialized matrix engines accessible via GEMM instructions. CPUs are pervasive and need to handle diverse requirements across DL workloads running in edge/HPC/cloud platforms. Therefore, as DL workloads embrace sparsity to reduce the computations and memory size of models, it is also imperative for CPUs to add support for sparsity to avoid under-utilization of the dense matrix engine and inefficient usage of the caches and registers. This work presents VEGETA, a set of ISA and microarchitecture extensions over dense matrix engines to support flexible structured sparsity for CPUs, enabling programmable support for diverse DL models with varying degrees of sparsity. Compared to the state-of-the-art (SOTA) dense matrix engine in CPUs, a VEGETA engine provides 1.09x, 2.20x, 3.74x, and 3.28x speed-ups when running 4:4 (dense), 2:4, 1:4, and unstructured (95%) sparse DNN layers.
RASA: Efficient Register-Aware Systolic Array Matrix Engine for CPU
Oct 05, 2021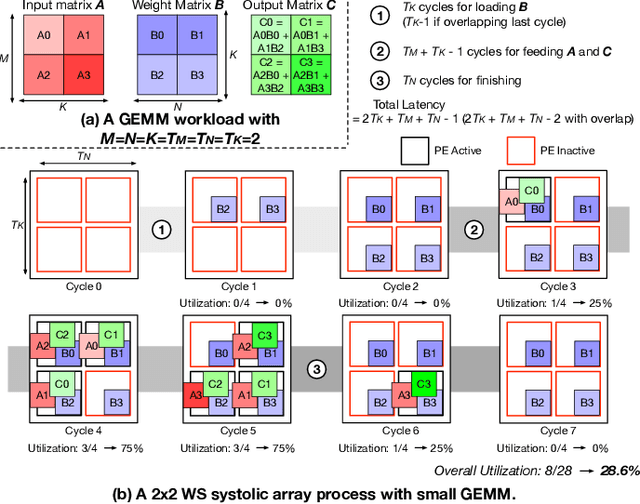
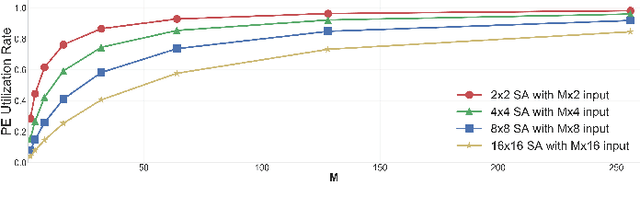
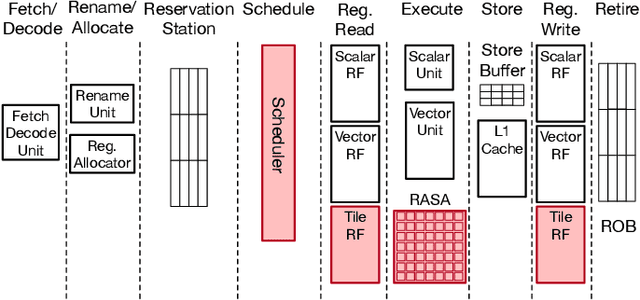
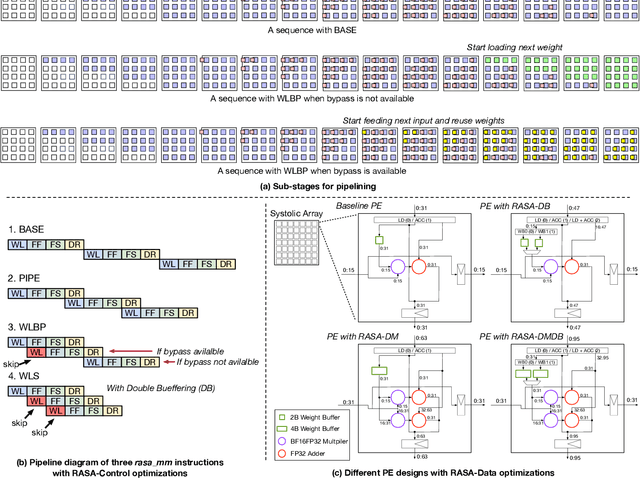
As AI-based applications become pervasive, CPU vendors are starting to incorporate matrix engines within the datapath to boost efficiency. Systolic arrays have been the premier architectural choice as matrix engines in offload accelerators. However, we demonstrate that incorporating them inside CPUs can introduce under-utilization and stalls due to limited register storage to amortize the fill and drain times of the array. To address this, we propose RASA, Register-Aware Systolic Array. We develop techniques to divide an execution stage into several sub-stages and overlap instructions to hide overheads and run them concurrently. RASA-based designs improve performance significantly with negligible area and power overhead.
Context-Aware Task Handling in Resource-Constrained Robots with Virtualization
Apr 09, 2021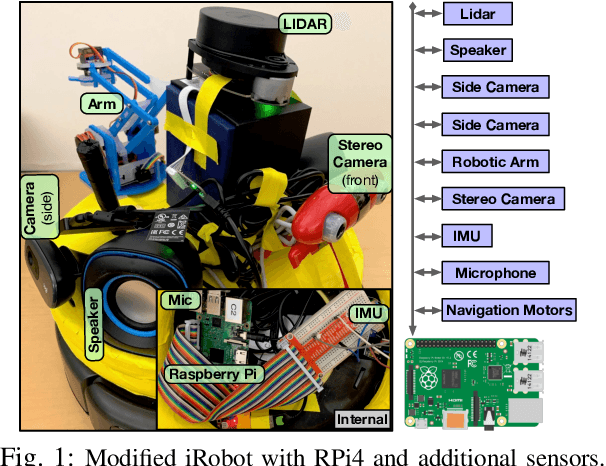
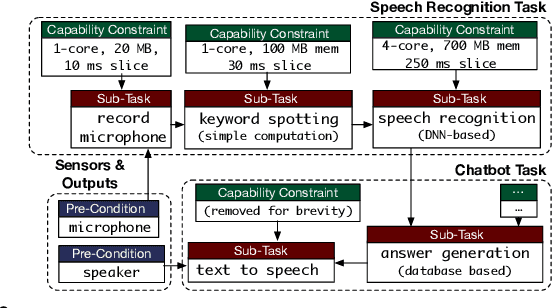

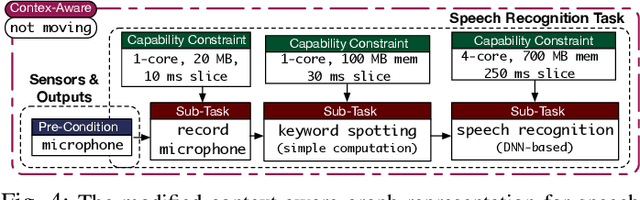
Intelligent mobile robots are critical in several scenarios. However, as their computational resources are limited, mobile robots struggle to handle several tasks concurrently and yet guaranteeing real-timeliness. To address this challenge and improve the real-timeliness of critical tasks under resource constraints, we propose a fast context-aware task handling technique. To effectively handling tasks in real-time, our proposed context-aware technique comprises of three main ingredients: (i) a dynamic time-sharing mechanism, coupled with (ii) an event-driven task scheduling using reactive programming paradigm to mindfully use the limited resources; and, (iii) a lightweight virtualized execution to easily integrate functionalities and their dependencies. We showcase our technique on a Raspberry-Pi-based robot with a variety of tasks such as Simultaneous localization and mapping (SLAM), sign detection, and speech recognition with a 42% speedup in total execution time compared to the common Linux scheduler.
Reducing Inference Latency with Concurrent Architectures for Image Recognition
Nov 13, 2020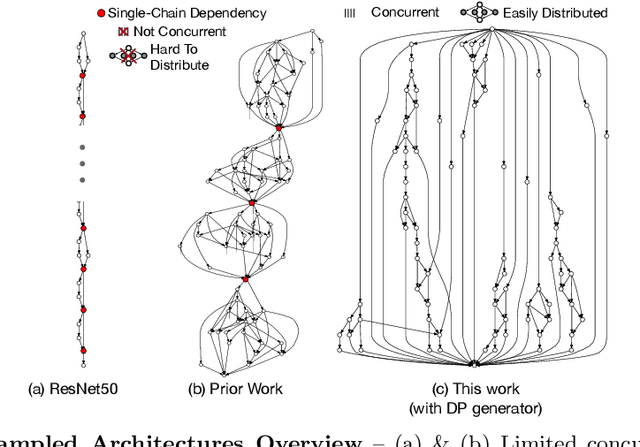

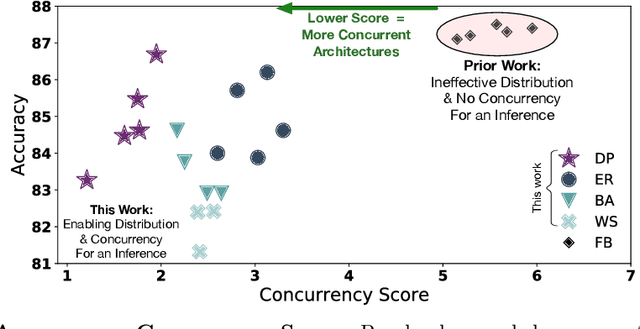
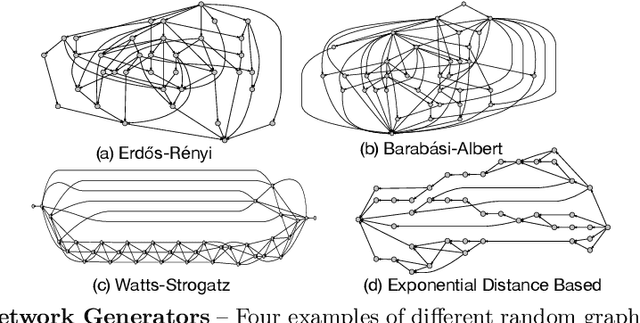
Satisfying the high computation demand of modern deep learning architectures is challenging for achieving low inference latency. The current approaches in decreasing latency only increase parallelism within a layer. This is because architectures typically capture a single-chain dependency pattern that prevents efficient distribution with a higher concurrency (i.e., simultaneous execution of one inference among devices). Such single-chain dependencies are so widespread that even implicitly biases recent neural architecture search (NAS) studies. In this visionary paper, we draw attention to an entirely new space of NAS that relaxes the single-chain dependency to provide higher concurrency and distribution opportunities. To quantitatively compare these architectures, we propose a score that encapsulates crucial metrics such as communication, concurrency, and load balancing. Additionally, we propose a new generator and transformation block that consistently deliver superior architectures compared to current state-of-the-art methods. Finally, our preliminary results show that these new architectures reduce the inference latency and deserve more attention.
Edge-Tailored Perception: Fast Inferencing in-the-Edge with Efficient Model Distribution
Mar 13, 2020
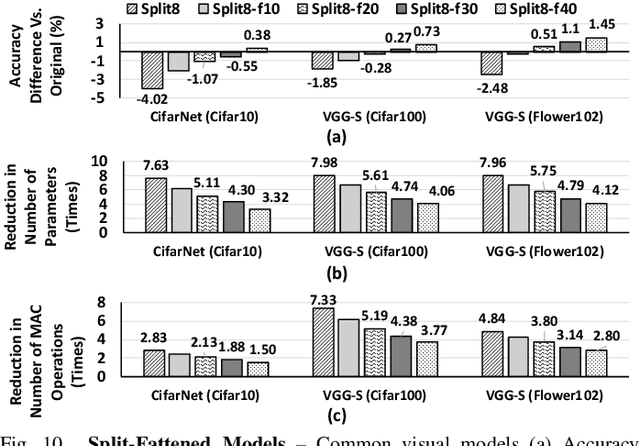
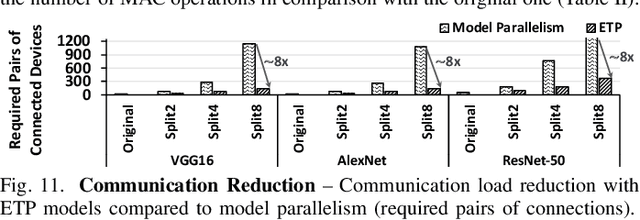
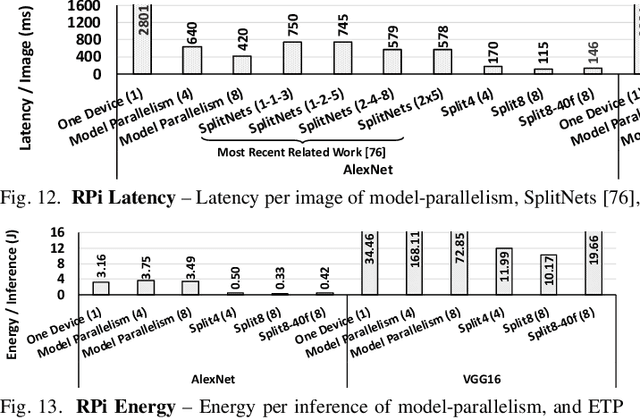
The rise of deep neural networks (DNNs) is inspiring new studies in myriad of edge use cases with robots, autonomous agents, and Internet-of-things (IoT) devices. However, in-the-edge inferencing of DNNs is still a severe challenge mainly because of the contradiction between the inherent intensive resource requirements and the tight resource availability in several edge domains. Further, as communication is costly, taking advantage of other available edge devices is not an effective solution in edge domains. Therefore, to benefit from available compute resources with low communication overhead, we propose new edge-tailored perception (ETP) models that consist of several almost-independent and narrow branches. ETP models offer close-to-minimum communication overheads with better distribution opportunities while significantly reducing memory and computation footprints, all with a trivial accuracy loss for not accuracy-critical tasks. To show the benefits, we deploy ETP models on two real systems, Raspberry Pis and edge-level PYNQ FPGAs. Additionally, we share our insights about tailoring a systolic-based architecture for edge computing with FPGA implementations. ETP models created based on LeNet, CifarNet, VGG-S/16, AlexNet, and ResNets and trained on MNIST, CIFAR10/100, Flower102, and ImageNet, achieve a maximum and average speedups of 56x and 7x, compared to originals. ETP is an addition to existing single-device optimizations for embedded devices by enabling the exploitation of multiple devices. As an example, we show applying pruning and quantization on ETP models improves the average speedup to 33x.
A Case Study: Exploiting Neural Machine Translation to Translate CUDA to OpenCL
May 18, 2019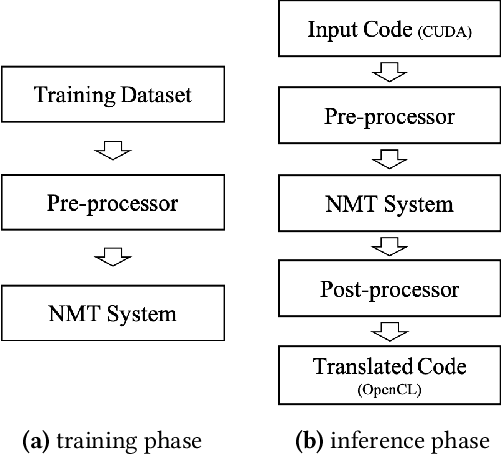
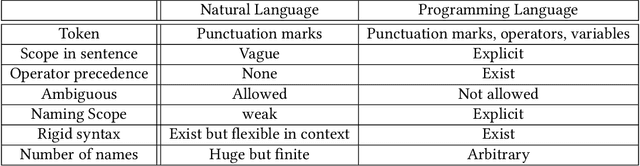

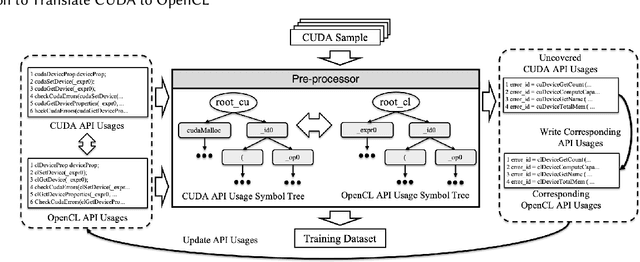
The sequence-to-sequence (seq2seq) model for neural machine translation has significantly improved the accuracy of language translation. There have been new efforts to use this seq2seq model for program language translation or program comparisons. In this work, we present the detailed steps of using a seq2seq model to translate CUDA programs to OpenCL programs, which both have very similar programming styles. Our work shows (i) a training input set generation method, (ii) pre/post processing, and (iii) a case study using Polybench-gpu-1.0, NVIDIA SDK, and Rodinia benchmarks.
Collaborative Execution of Deep Neural Networks on Internet of Things Devices
Jan 08, 2019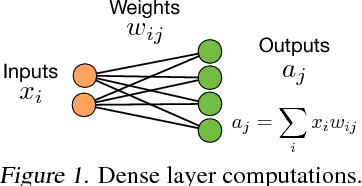

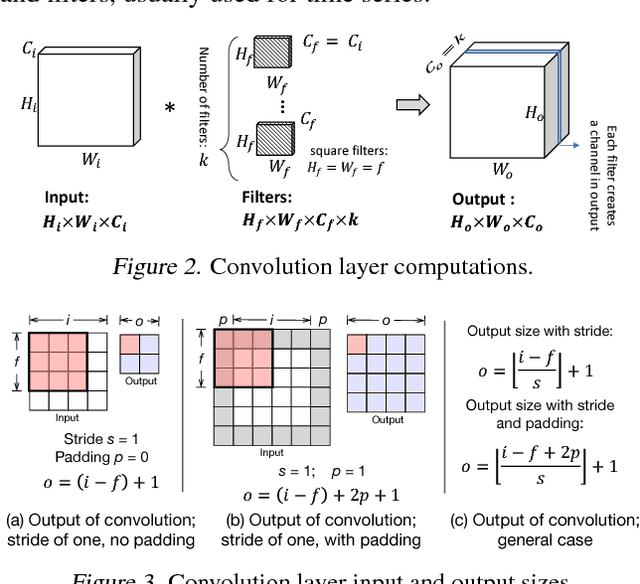
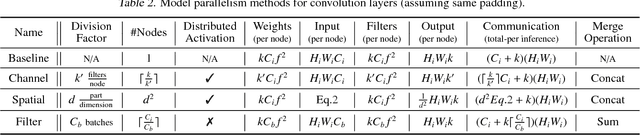
With recent advancements in deep neural networks (DNNs), we are able to solve traditionally challenging problems. Since DNNs are compute intensive, consumers, to deploy a service, need to rely on expensive and scarce compute resources in the cloud. This approach, in addition to its dependability on high-quality network infrastructure and data centers, raises new privacy concerns. These challenges may limit DNN-based applications, so many researchers have tried optimize DNNs for local and in-edge execution. However, inadequate power and computing resources of edge devices along with small number of requests limits current optimizations applicability, such as batch processing. In this paper, we propose an approach that utilizes aggregated existing computing power of Internet of Things (IoT) devices surrounding an environment by creating a collaborative network. In this approach, IoT devices cooperate to conduct single-batch inferencing in real time. While exploiting several new model-parallelism methods and their distribution characteristics, our approach enhances the collaborative network by creating a balanced and distributed processing pipeline. We have illustrated our work using many Raspberry Pis with studying DNN models such as AlexNet, VGG16, Xception, and C3D.
Musical Chair: Efficient Real-Time Recognition Using Collaborative IoT Devices
Mar 21, 2018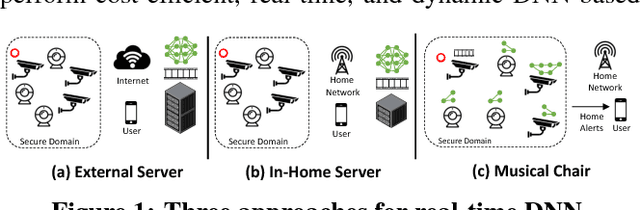

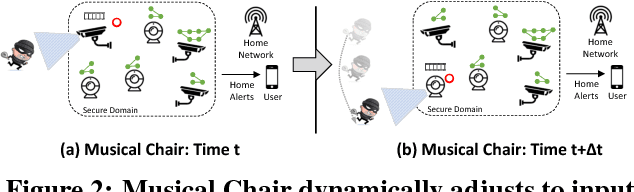

The prevalence of Internet of things (IoT) devices and abundance of sensor data has created an increase in real-time data processing such as recognition of speech, image, and video. While currently such processes are offloaded to the computationally powerful cloud system, a localized and distributed approach is desirable because (i) it preserves the privacy of users and (ii) it omits the dependency on cloud services. However, IoT networks are usually composed of resource-constrained devices, and a single device is not powerful enough to process real-time data. To overcome this challenge, we examine data and model parallelism for such devices in the context of deep neural networks. We propose Musical Chair to enable efficient, localized, and dynamic real-time recognition by harvesting the aggregated computational power from the resource-constrained devices in the same IoT network as input sensors. Musical chair adapts to the availability of computing devices at runtime and adjusts to the inherit dynamics of IoT networks. To demonstrate Musical Chair, on a network of Raspberry PIs (up to 12) each connected to a camera, we implement a state-of-the-art action recognition model for videos and two recognition models for images. Compared to the Tegra TX2, an embedded low-power platform with a six-core CPU and a GPU, our distributed action recognition system achieves not only similar energy consumption but also twice the performance of the TX2. Furthermore, in image recognition, Musical Chair achieves similar performance and saves dynamic energy.