 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVEGETA: Vertically-Integrated Extensions for Sparse/Dense GEMM Tile Acceleration on CPUs
Feb 23, 2023



Deep Learning (DL) acceleration support in CPUs has recently gained a lot of traction, with several companies (Arm, Intel, IBM) announcing products with specialized matrix engines accessible via GEMM instructions. CPUs are pervasive and need to handle diverse requirements across DL workloads running in edge/HPC/cloud platforms. Therefore, as DL workloads embrace sparsity to reduce the computations and memory size of models, it is also imperative for CPUs to add support for sparsity to avoid under-utilization of the dense matrix engine and inefficient usage of the caches and registers. This work presents VEGETA, a set of ISA and microarchitecture extensions over dense matrix engines to support flexible structured sparsity for CPUs, enabling programmable support for diverse DL models with varying degrees of sparsity. Compared to the state-of-the-art (SOTA) dense matrix engine in CPUs, a VEGETA engine provides 1.09x, 2.20x, 3.74x, and 3.28x speed-ups when running 4:4 (dense), 2:4, 1:4, and unstructured (95%) sparse DNN layers.
RASA: Efficient Register-Aware Systolic Array Matrix Engine for CPU
Oct 05, 2021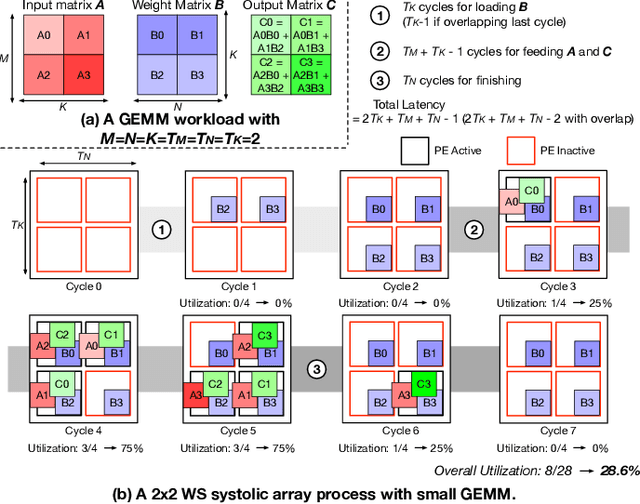
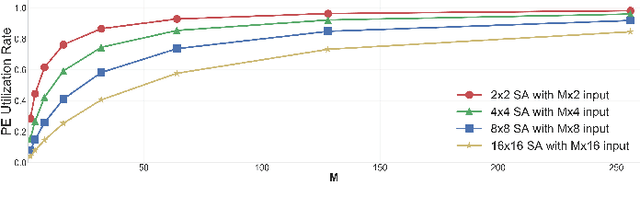
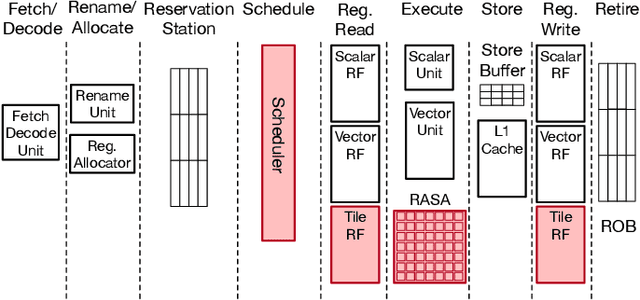
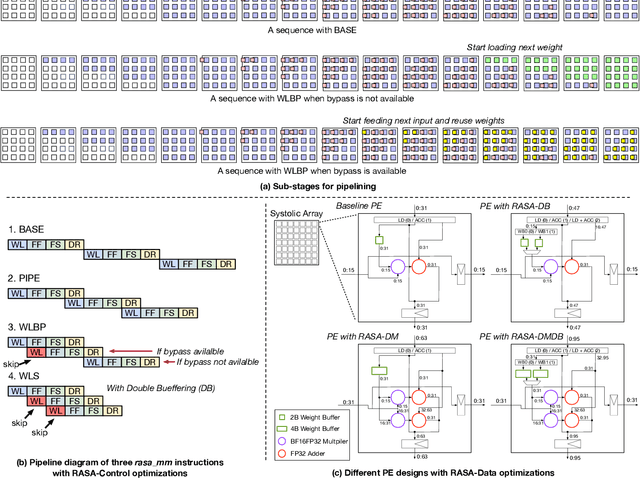
As AI-based applications become pervasive, CPU vendors are starting to incorporate matrix engines within the datapath to boost efficiency. Systolic arrays have been the premier architectural choice as matrix engines in offload accelerators. However, we demonstrate that incorporating them inside CPUs can introduce under-utilization and stalls due to limited register storage to amortize the fill and drain times of the array. To address this, we propose RASA, Register-Aware Systolic Array. We develop techniques to divide an execution stage into several sub-stages and overlap instructions to hide overheads and run them concurrently. RASA-based designs improve performance significantly with negligible area and power overhead.