 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Multi-Node Mixture-of-Experts Inference Using Expert Activation Patterns
Apr 25, 2026Most recent state-of-the-art (SOTA) large language models (LLMs) use Mixture-of-Experts (MoE) architectures to scale model capacity without proportional per-token compute, enabling higher-quality outputs at manageable serving costs. However, MoE inference at scale is fundamentally bottlenecked by expert load imbalance and inefficient token routing, especially in multi-node deployments where tokens are not guaranteed to be routed to local experts, resulting in significant inter-node all-to-all communication overhead. To systematically characterize these challenges, we profile SOTA open-source MoE models, including Llama 4 Maverick, DeepSeek V3-671B, and Qwen3-230B-A22B, on various datasets and collected over 100k real expert activation traces. Upon studying the expert activation patterns, we uncover various persistent properties across all the frontier MoE models: variable expert load imbalance, domain-specific expert activation where expert popularity shifts across task families (code, math, chat, general), and a strong correlation between prefill and decode expert activations. Motivated by these findings, we propose workload-aware micro-batch grouping and an expert placement strategy to maximize token locality to the destination expert, thereby reducing inter-node communication. Across models and datasets, these optimizations help reduce all2all communication data up to 20, resulting in lower MoE decode latency and better accelerator utilization.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Accelerating Transformer Inference and Training with 2:4 Activation Sparsity
Mar 20, 2025



In this paper, we demonstrate how to leverage 2:4 sparsity, a popular hardware-accelerated GPU sparsity pattern, to activations to accelerate large language model training and inference. Crucially we exploit the intrinsic sparsity found in Squared-ReLU activations to provide this acceleration with no accuracy loss. Our approach achieves up to 1.3x faster Feed Forward Network (FFNs) in both the forwards and backwards pass. This work highlights the potential for sparsity to play a key role in accelerating large language model training and inference.
SDQ: Sparse Decomposed Quantization for LLM Inference
Jun 19, 2024



Recently, large language models (LLMs) have shown surprising performance in task-specific workloads as well as general tasks with the given prompts. However, to achieve unprecedented performance, recent LLMs use billions to trillions of parameters, which hinder the wide adaptation of those models due to their extremely large compute and memory requirements. To resolve the issue, various model compression methods are being actively investigated. In this work, we propose SDQ (Sparse Decomposed Quantization) to exploit both structured sparsity and quantization to achieve both high compute and memory efficiency. From our evaluations, we observe that SDQ can achieve 4x effective compute throughput with <1% quality drop.
Demystifying Platform Requirements for Diverse LLM Inference Use Cases
Jun 03, 2024



Large language models (LLMs) have shown remarkable performance across a wide range of applications, often outperforming human experts. However, deploying these parameter-heavy models efficiently for diverse inference use cases requires carefully designed hardware platforms with ample computing, memory, and network resources. With LLM deployment scenarios and models evolving at breakneck speed, the hardware requirements to meet SLOs remains an open research question. In this work, we present an analytical tool, GenZ, to study the relationship between LLM inference performance and various platform design parameters. Our analysis provides insights into configuring platforms for different LLM workloads and use cases. We quantify the platform requirements to support SOTA LLMs models like LLaMA and GPT-4 under diverse serving settings. Furthermore, we project the hardware capabilities needed to enable future LLMs potentially exceeding hundreds of trillions of parameters. The trends and insights derived from GenZ can guide AI engineers deploying LLMs as well as computer architects designing next-generation hardware accelerators and platforms. Ultimately, this work sheds light on the platform design considerations for unlocking the full potential of large language models across a spectrum of applications. The source code is available at https://github.com/abhibambhaniya/GenZ-LLM-Analyzer .
Abstracting Sparse DNN Acceleration via Structured Sparse Tensor Decomposition
Mar 12, 2024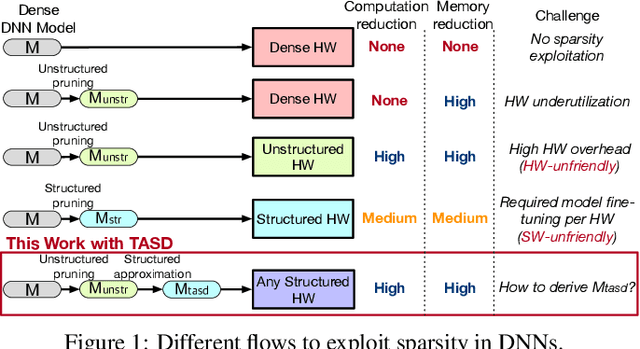
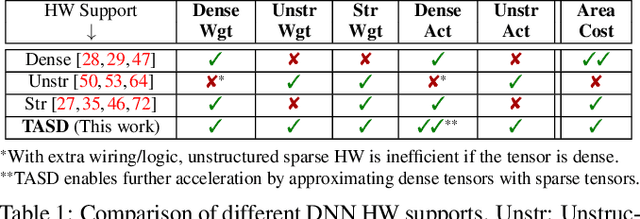
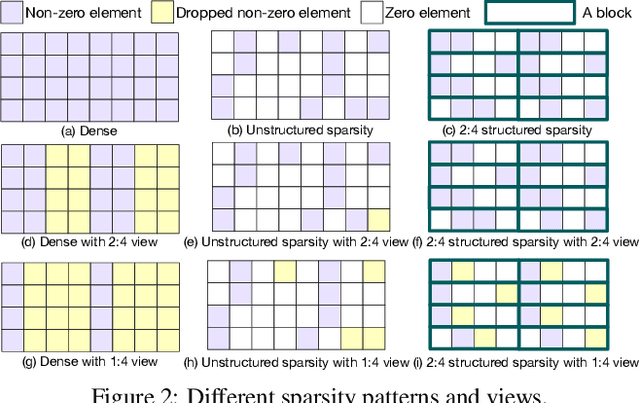
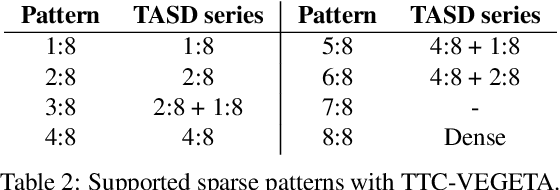
Exploiting sparsity in deep neural networks (DNNs) has been a promising area to meet the growing computation need of modern DNNs. However, in practice, sparse DNN acceleration still faces a key challenge. To minimize the overhead of sparse acceleration, hardware designers have proposed structured sparse hardware support recently, which provides limited flexibility and requires extra model fine-tuning. Moreover, any sparse model fine-tuned for certain structured sparse hardware cannot be accelerated by other structured hardware. To bridge the gap between sparse DNN models and hardware, this paper proposes tensor approximation via structured decomposition (TASD), which leverages the distributive property in linear algebra to turn any sparse tensor into a series of structured sparse tensors. Next, we develop a software framework, TASDER, to accelerate DNNs by searching layer-wise, high-quality structured decomposition for both weight and activation tensors so that they can be accelerated by any systems with structured sparse hardware support. Evaluation results show that, by exploiting prior structured sparse hardware baselines, our method can accelerate off-the-shelf dense and sparse DNNs without fine-tuning and improves energy-delay-product by up to 83% and 74% on average.
GEAR: An Efficient KV Cache Compression Recipe for Near-Lossless Generative Inference of LLM
Mar 11, 2024



Key-value (KV) caching has become the de-facto to accelerate generation speed for large language models (LLMs) inference. However, the growing cache demand with increasing sequence length has transformed LLM inference to be a memory bound problem, significantly constraining the system throughput. Existing methods rely on dropping unimportant tokens or quantizing all entries uniformly. Such methods, however, often incur high approximation errors to represent the compressed matrices. The autoregressive decoding process further compounds the error of each step, resulting in critical deviation in model generation and deterioration of performance. To tackle this challenge, we propose GEAR, an efficient KV cache compression framework that achieves near-lossless high-ratio compression. GEAR first applies quantization to majority of entries of similar magnitudes to ultra-low precision. It then employs a low rank matrix to approximate the quantization error, and a sparse matrix to remedy individual errors from outlier entries. By adeptly integrating three techniques, GEAR is able to fully exploit their synergistic potentials. Our experiments demonstrate that compared to alternatives, GEAR achieves near-lossless 4-bit KV cache compression with up to 2.38x throughput improvement, while reducing peak-memory size up to 2.29x. Our code is publicly available at https://github.com/HaoKang-Timmy/GEAR.
Algorithm-Hardware Co-Design of Distribution-Aware Logarithmic-Posit Encodings for Efficient DNN Inference
Mar 08, 2024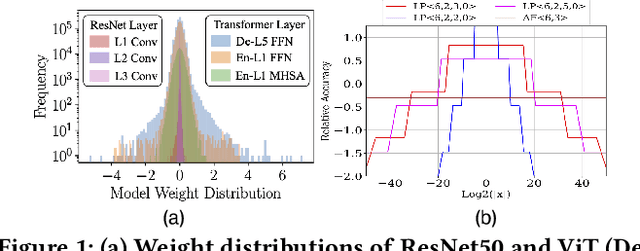

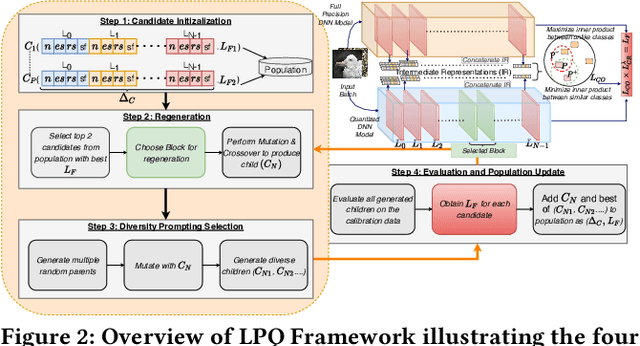
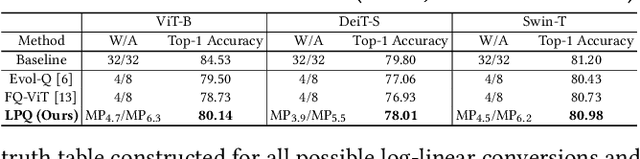
Traditional Deep Neural Network (DNN) quantization methods using integer, fixed-point, or floating-point data types struggle to capture diverse DNN parameter distributions at low precision, and often require large silicon overhead and intensive quantization-aware training. In this study, we introduce Logarithmic Posits (LP), an adaptive, hardware-friendly data type inspired by posits that dynamically adapts to DNN weight/activation distributions by parameterizing LP bit fields. We also develop a novel genetic-algorithm based framework, LP Quantization (LPQ), to find optimal layer-wise LP parameters while reducing representational divergence between quantized and full-precision models through a novel global-local contrastive objective. Additionally, we design a unified mixed-precision LP accelerator (LPA) architecture comprising of processing elements (PEs) incorporating LP in the computational datapath. Our algorithm-hardware co-design demonstrates on average <1% drop in top-1 accuracy across various CNN and ViT models. It also achieves ~ 2x improvements in performance per unit area and 2.2x gains in energy efficiency compared to state-of-the-art quantization accelerators using different data types.
VEGETA: Vertically-Integrated Extensions for Sparse/Dense GEMM Tile Acceleration on CPUs
Feb 23, 2023



Deep Learning (DL) acceleration support in CPUs has recently gained a lot of traction, with several companies (Arm, Intel, IBM) announcing products with specialized matrix engines accessible via GEMM instructions. CPUs are pervasive and need to handle diverse requirements across DL workloads running in edge/HPC/cloud platforms. Therefore, as DL workloads embrace sparsity to reduce the computations and memory size of models, it is also imperative for CPUs to add support for sparsity to avoid under-utilization of the dense matrix engine and inefficient usage of the caches and registers. This work presents VEGETA, a set of ISA and microarchitecture extensions over dense matrix engines to support flexible structured sparsity for CPUs, enabling programmable support for diverse DL models with varying degrees of sparsity. Compared to the state-of-the-art (SOTA) dense matrix engine in CPUs, a VEGETA engine provides 1.09x, 2.20x, 3.74x, and 3.28x speed-ups when running 4:4 (dense), 2:4, 1:4, and unstructured (95%) sparse DNN layers.
RASA: Efficient Register-Aware Systolic Array Matrix Engine for CPU
Oct 05, 2021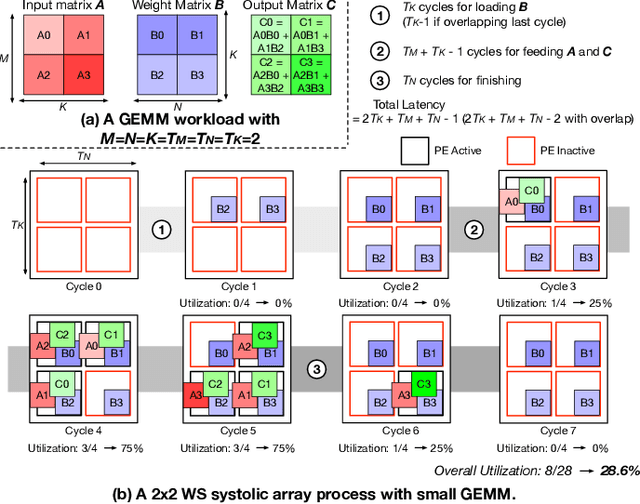
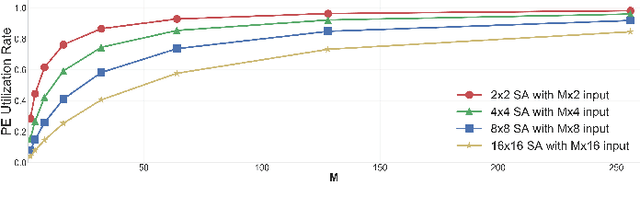
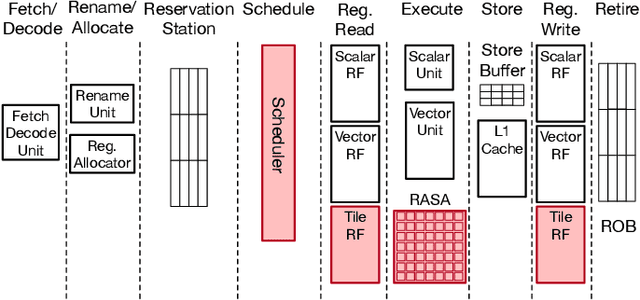
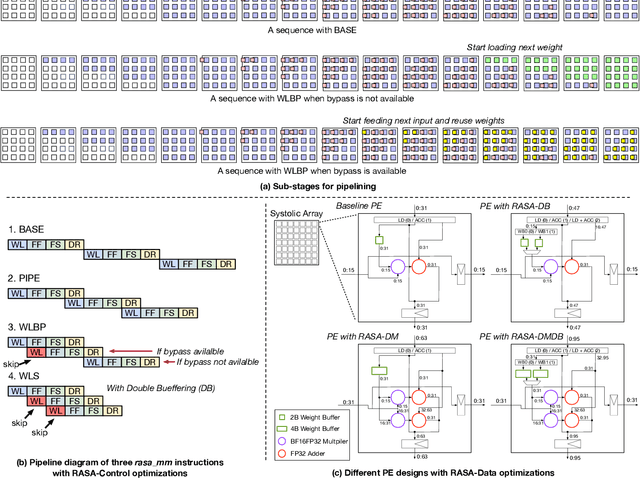
As AI-based applications become pervasive, CPU vendors are starting to incorporate matrix engines within the datapath to boost efficiency. Systolic arrays have been the premier architectural choice as matrix engines in offload accelerators. However, we demonstrate that incorporating them inside CPUs can introduce under-utilization and stalls due to limited register storage to amortize the fill and drain times of the array. To address this, we propose RASA, Register-Aware Systolic Array. We develop techniques to divide an execution stage into several sub-stages and overlap instructions to hide overheads and run them concurrently. RASA-based designs improve performance significantly with negligible area and power overhead.