 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnion: A Unified HW-SW Co-Design Ecosystem in MLIR for Evaluating Tensor Operations on Spatial Accelerators
Sep 17, 2021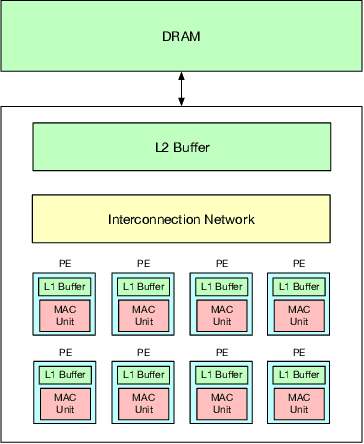
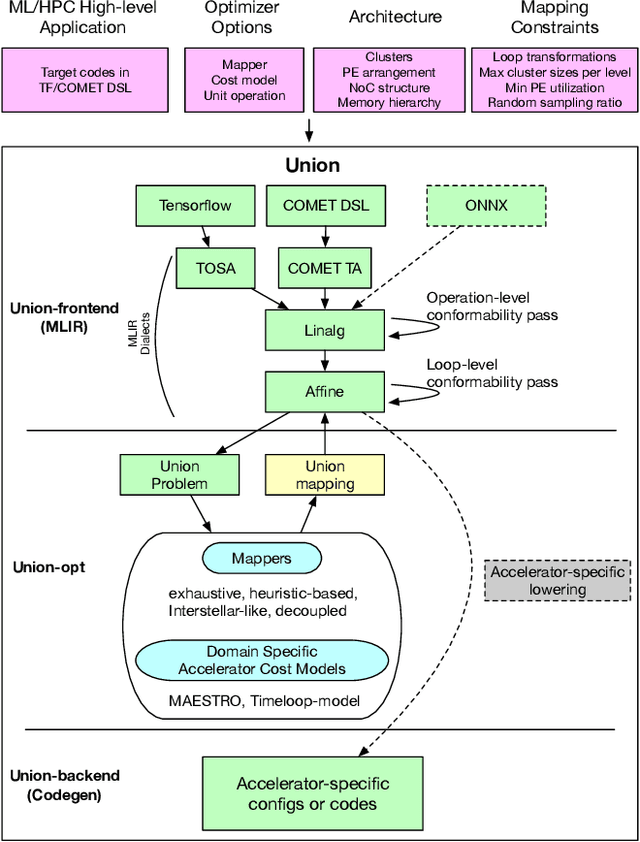
To meet the extreme compute demands for deep learning across commercial and scientific applications, dataflow accelerators are becoming increasingly popular. While these "domain-specific" accelerators are not fully programmable like CPUs and GPUs, they retain varying levels of flexibility with respect to data orchestration, i.e., dataflow and tiling optimizations to enhance efficiency. There are several challenges when designing new algorithms and mapping approaches to execute the algorithms for a target problem on new hardware. Previous works have addressed these challenges individually. To address this challenge as a whole, in this work, we present a HW-SW co-design ecosystem for spatial accelerators called Union within the popular MLIR compiler infrastructure. Our framework allows exploring different algorithms and their mappings on several accelerator cost models. Union also includes a plug-and-play library of accelerator cost models and mappers which can easily be extended. The algorithms and accelerator cost models are connected via a novel mapping abstraction that captures the map space of spatial accelerators which can be systematically pruned based on constraints from the hardware, workload, and mapper. We demonstrate the value of Union for the community with several case studies which examine offloading different tensor operations(CONV/GEMM/Tensor Contraction) on diverse accelerator architectures using different mapping schemes.
Evaluating Spatial Accelerator Architectures with Tiled Matrix-Matrix Multiplication
Jun 19, 2021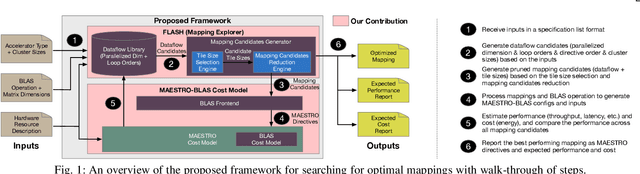
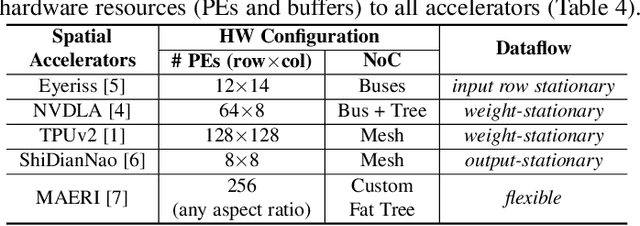
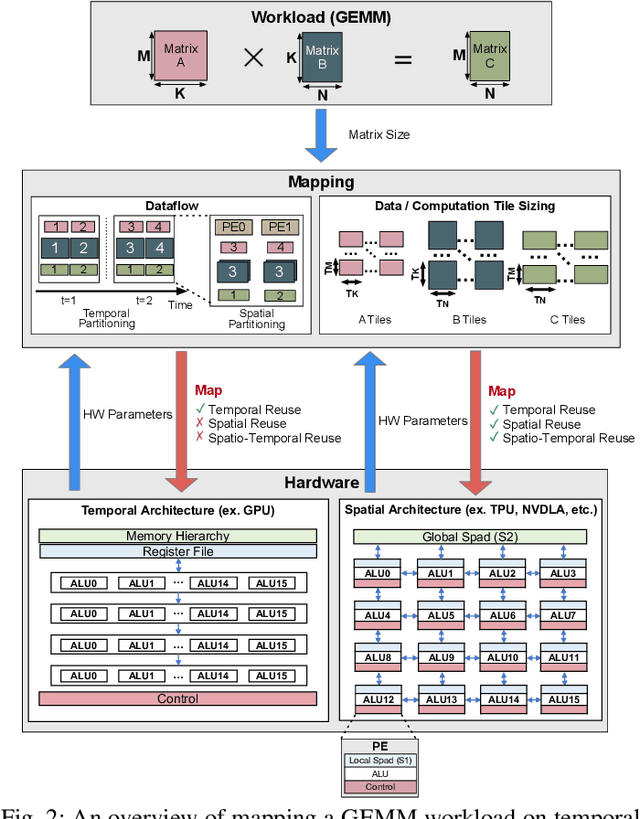

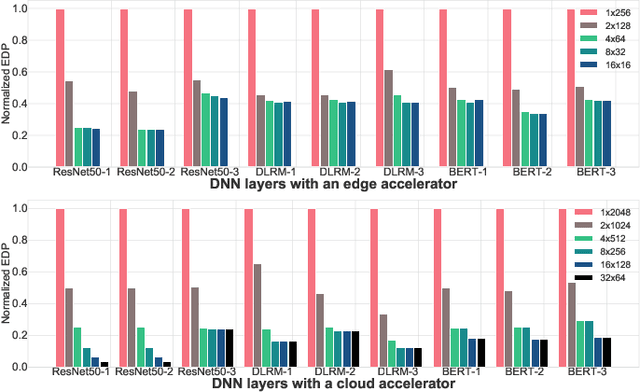
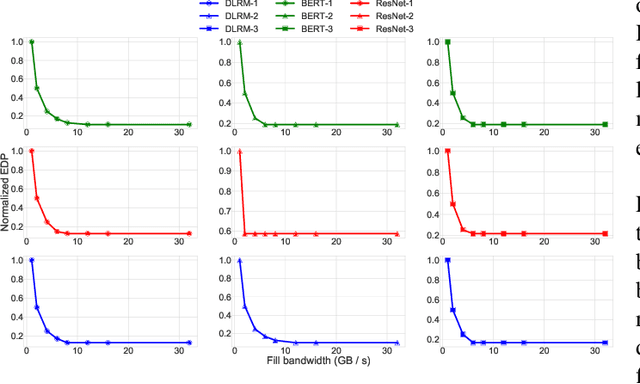
There is a growing interest in custom spatial accelerators for machine learning applications. These accelerators employ a spatial array of processing elements (PEs) interacting via custom buffer hierarchies and networks-on-chip. The efficiency of these accelerators comes from employing optimized dataflow (i.e., spatial/temporal partitioning of data across the PEs and fine-grained scheduling) strategies to optimize data reuse. The focus of this work is to evaluate these accelerator architectures using a tiled general matrix-matrix multiplication (GEMM) kernel. To do so, we develop a framework that finds optimized mappings (dataflow and tile sizes) for a tiled GEMM for a given spatial accelerator and workload combination, leveraging an analytical cost model for runtime and energy. Our evaluations over five spatial accelerators demonstrate that the tiled GEMM mappings systematically generated by our framework achieve high performance on various GEMM workloads and accelerators.
MARVEL: A Decoupled Model-driven Approach for Efficiently Mapping Convolutions on Spatial DNN Accelerators
Feb 18, 2020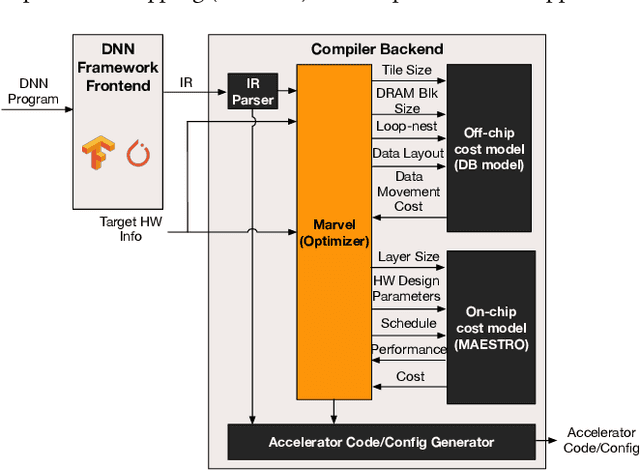
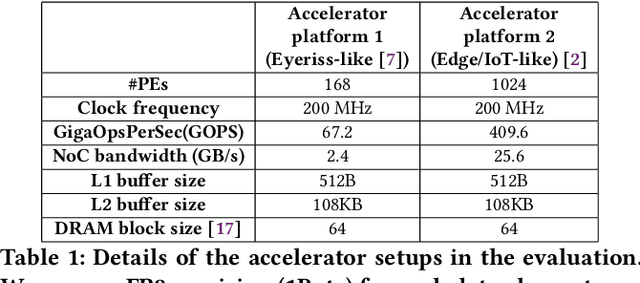
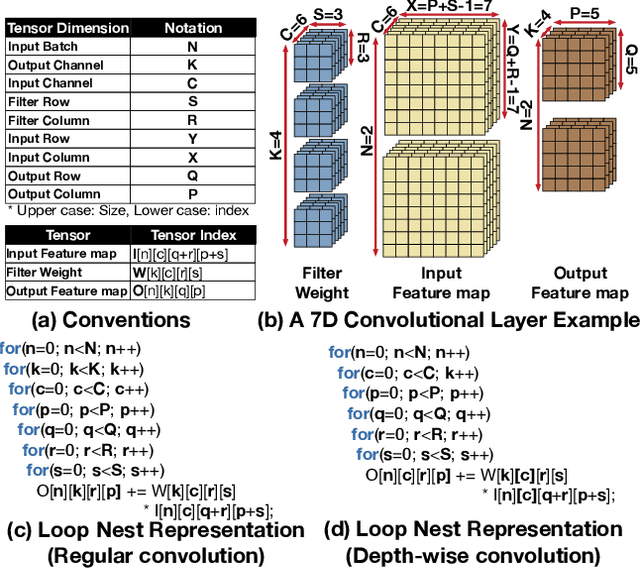
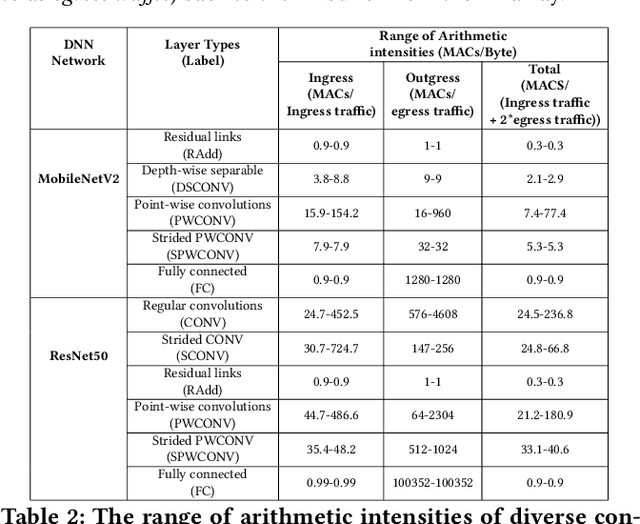
The efficiency of a spatial DNN accelerator depends heavily on the compiler's ability to generate optimized mappings for a given DNN's operators (layers) on to the accelerator's compute and memory resources. Searching for the optimal mapping is challenging because of a massive space of possible data-layouts and loop transformations for the DNN layers. For example, there are over 10^19 valid mappings for a single convolution layer on average for mapping ResNet50 and MobileNetV2 on a representative DNN edge accelerator. This challenge gets exacerbated with new layer types (e.g., depth-wise and point-wise convolutions) and diverse hardware accelerator configurations. To address this challenge, we propose a decoupled off-chip/on-chip approach that decomposes the mapping space into off-chip and on-chip subspaces, and first optimizes the off-chip subspace followed by the on-chip subspace. The motivation for this decomposition is to dramatically reduce the size of the search space, and to also prioritize the optimization of off-chip data movement, which is 2-3 orders of magnitude more compared to the on-chip data movement. We introduce {\em Marvel}, which implements the above approach by leveraging two cost models to explore the two subspaces -- a classical distinct-block (DB) locality cost model for the off-chip subspace, and a state-of-the-art DNN accelerator behavioral cost model, MAESTRO, for the on-chip subspace. Our approach also considers dimension permutation, a form of data-layouts, in the mapping space formulation along with the loop transformations.