 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvanced Graph-Based Deep Learning for Probabilistic Type Inference
Sep 13, 2020

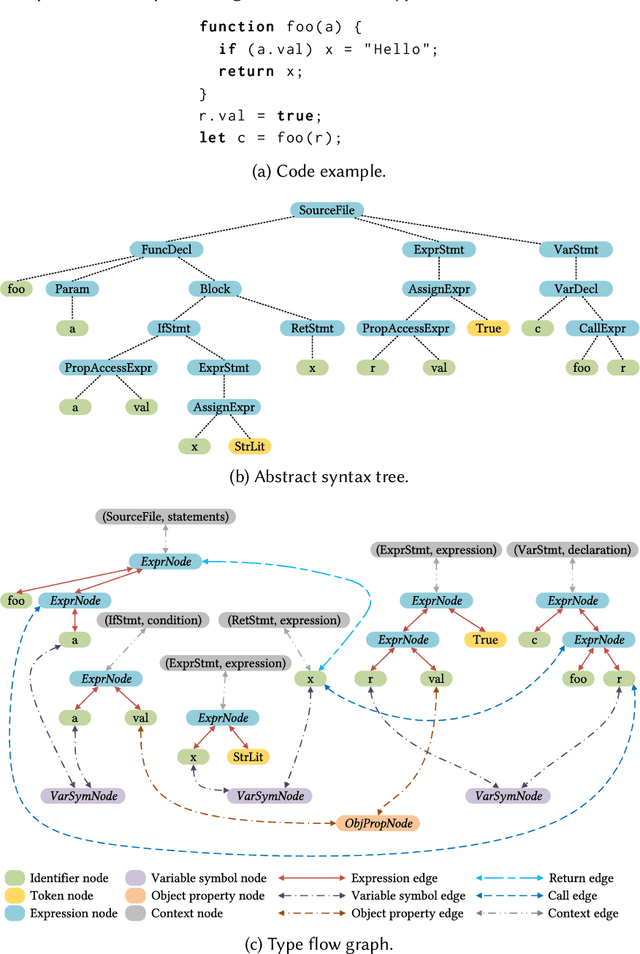
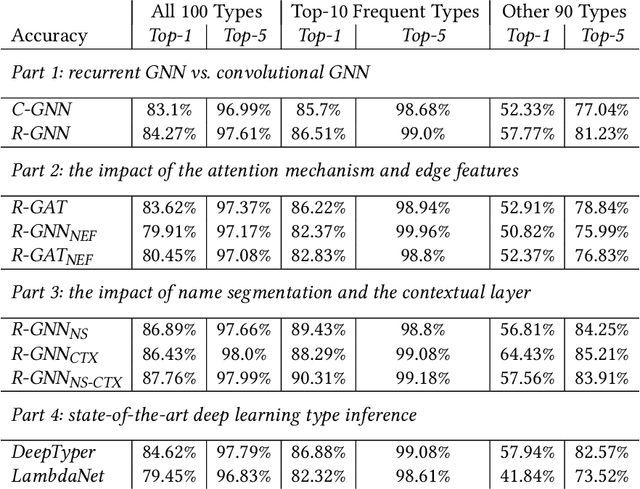
Dynamically typed languages such as JavaScript and Python have emerged as the most popular programming languages in use. Important benefits can accrue from including type annotations in dynamically typed programs. This approach to gradual typing is exemplified by the TypeScript programming system which allows programmers to specify partially typed programs, and then uses static analysis to infer the remaining types. However, in general, the effectiveness of static type inference is limited and depends on the complexity of the program's structure and the initial type annotations. As a result, there is a strong motivation for new approaches that can advance the state of the art in statically predicting types in dynamically typed programs, and that do so with acceptable performance for use in interactive programming environments. Previous work has demonstrated the promise of probabilistic type inference using deep learning. In this paper, we advance past work by introducing a range of graph neural network (GNN) models that operate on a novel type flow graph (TFG) representation. The TFG represents an input program's elements as graph nodes connected with syntax edges and data flow edges, and our GNN models are trained to predict the type labels in the TFG for a given input program. We study different design choices for our GNN models for the 100 most common types in our evaluation dataset, and show that our best two GNN configurations for accuracy achieve a top-1 accuracy of 87.76% and 86.89% respectively, outperforming the two most closely related deep learning type inference approaches from past work -- DeepTyper with a top-1 accuracy of 84.62% and LambdaNet with a top-1 accuracy of 79.45%. Further, the average inference throughputs of those two configurations are 353.8 and 1,303.9 files/second, compared to 186.7 files/second for DeepTyper and 1,050.3 files/second for LambdaNet.
MISIM: An End-to-End Neural Code Similarity System
Jun 15, 2020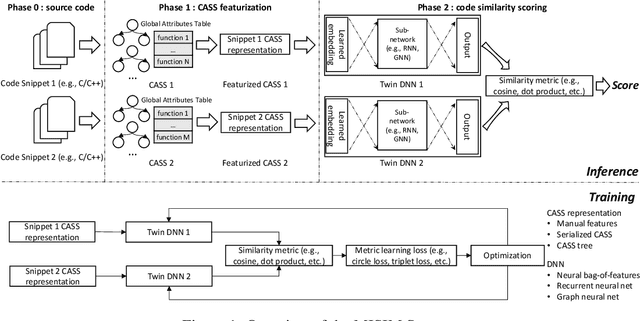
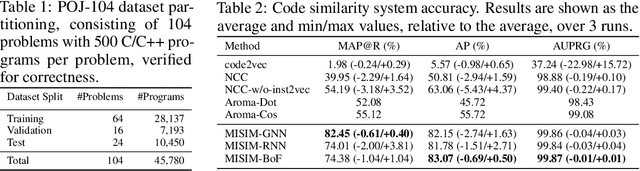
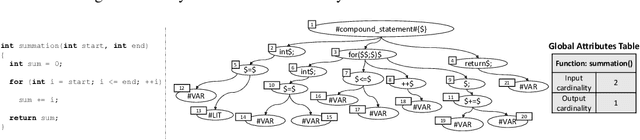
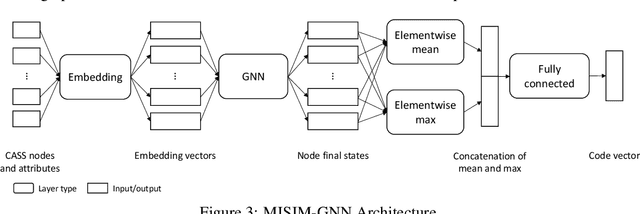
Code similarity systems are integral to a range of applications from code recommendation to automated construction of software tests and defect mitigation. In this paper, we present Machine Inferred Code Similarity (MISIM), a novel end-to-end code similarity system that consists of two core components. First, MISIM uses a novel context-aware similarity structure, which is designed to aid in lifting semantic meaning from code syntax. Second, MISIM provides a neural-based code similarity scoring system, which can be implemented with various neural network algorithms and topologies with learned parameters. We compare MISIM to three other state-of-the-art code similarity systems: (i) code2vec, (ii) Neural Code Comprehension, and (iii) Aroma. In our experimental evaluation across 45,780 programs, MISIM consistently outperformed all three systems, often by a large factor (upwards of 40.6x).
Context-Aware Parse Trees
Mar 24, 2020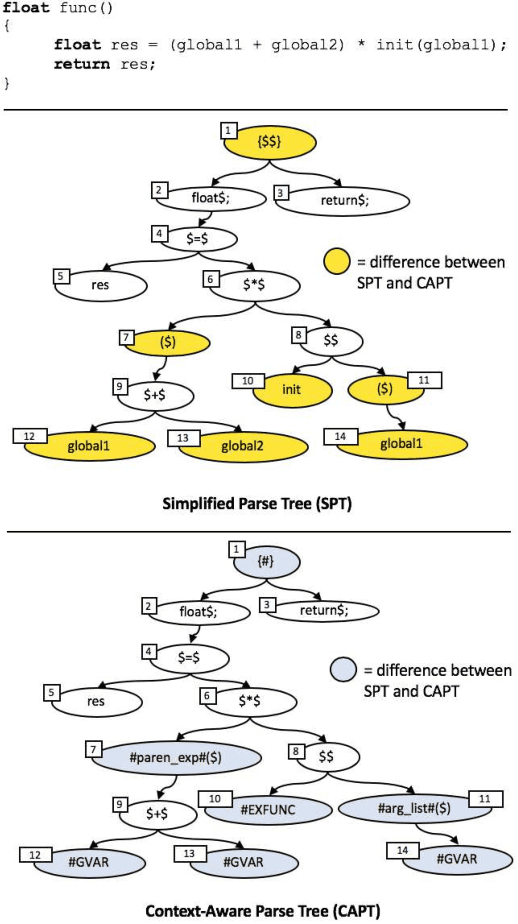
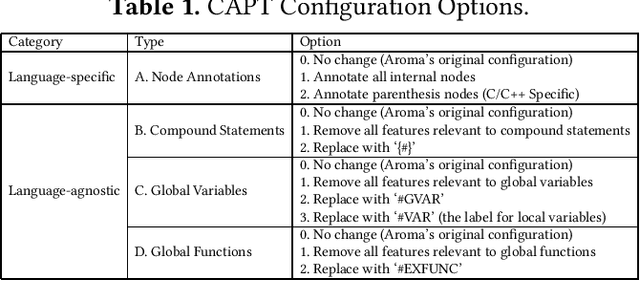
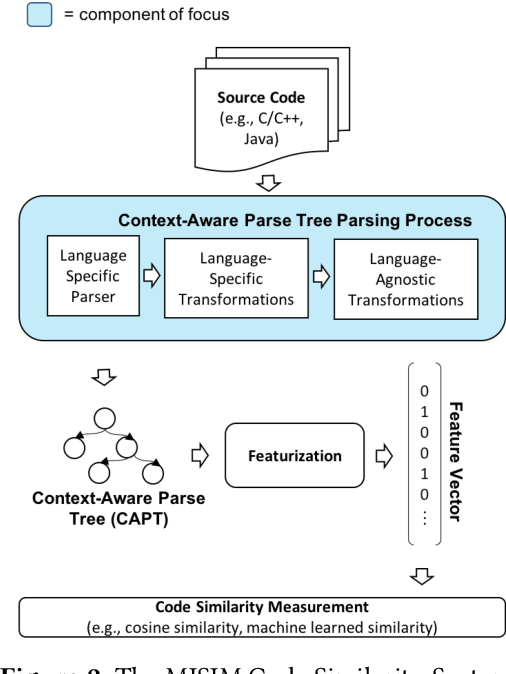
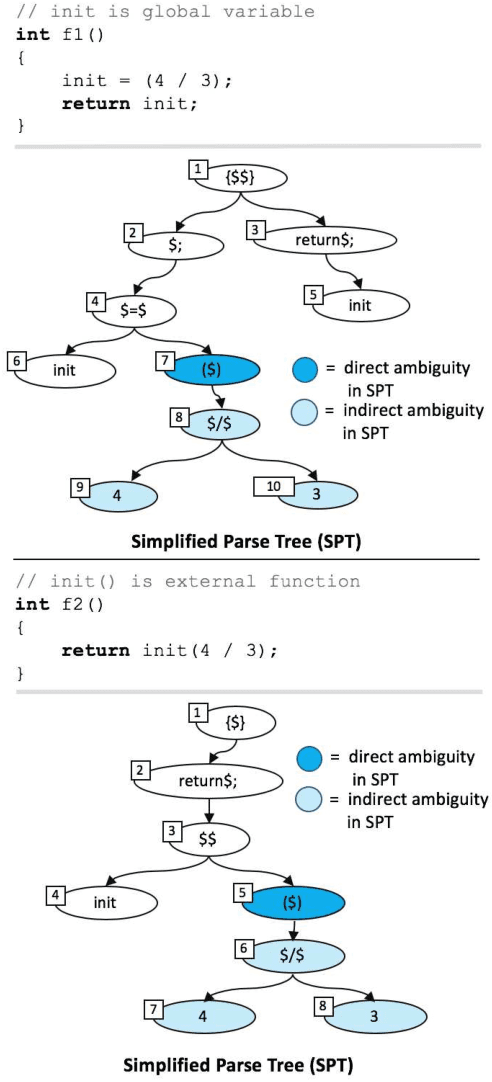
The simplified parse tree (SPT) presented in Aroma, a state-of-the-art code recommendation system, is a tree-structured representation used to infer code semantics by capturing program \emph{structure} rather than program \emph{syntax}. This is a departure from the classical abstract syntax tree, which is principally driven by programming language syntax. While we believe a semantics-driven representation is desirable, the specifics of an SPT's construction can impact its performance. We analyze these nuances and present a new tree structure, heavily influenced by Aroma's SPT, called a \emph{context-aware parse tree} (CAPT). CAPT enhances SPT by providing a richer level of semantic representation. Specifically, CAPT provides additional binding support for language-specific techniques for adding semantically-salient features, and language-agnostic techniques for removing syntactically-present but semantically-irrelevant features. Our research quantitatively demonstrates the value of our proposed semantically-salient features, enabling a specific CAPT configuration to be 39\% more accurate than SPT across the 48,610 programs we analyzed.
MARVEL: A Decoupled Model-driven Approach for Efficiently Mapping Convolutions on Spatial DNN Accelerators
Feb 18, 2020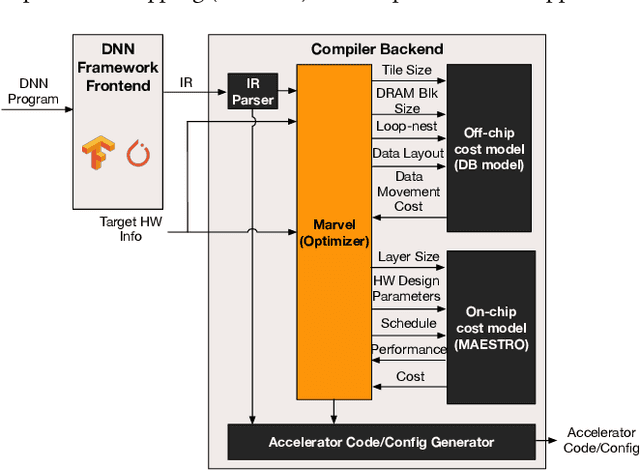
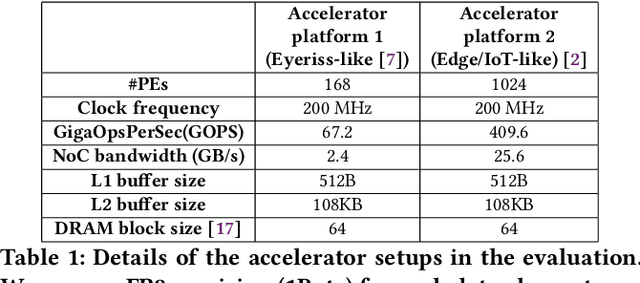
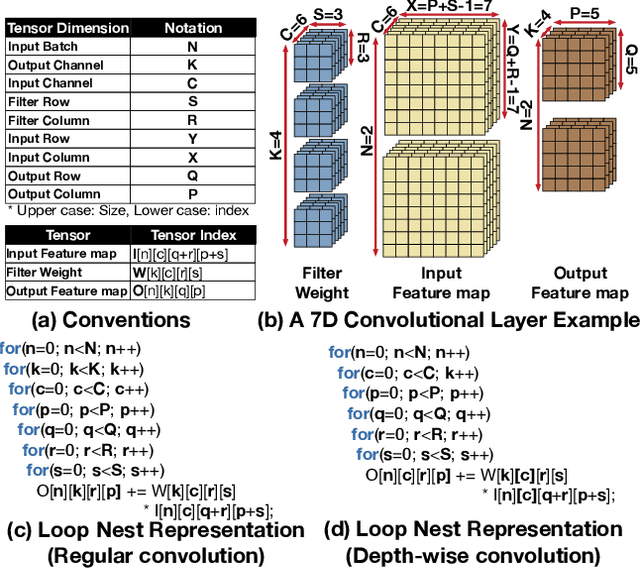
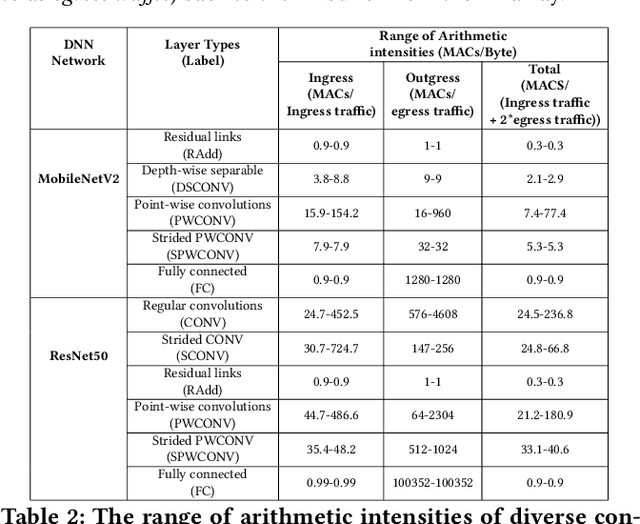
The efficiency of a spatial DNN accelerator depends heavily on the compiler's ability to generate optimized mappings for a given DNN's operators (layers) on to the accelerator's compute and memory resources. Searching for the optimal mapping is challenging because of a massive space of possible data-layouts and loop transformations for the DNN layers. For example, there are over 10^19 valid mappings for a single convolution layer on average for mapping ResNet50 and MobileNetV2 on a representative DNN edge accelerator. This challenge gets exacerbated with new layer types (e.g., depth-wise and point-wise convolutions) and diverse hardware accelerator configurations. To address this challenge, we propose a decoupled off-chip/on-chip approach that decomposes the mapping space into off-chip and on-chip subspaces, and first optimizes the off-chip subspace followed by the on-chip subspace. The motivation for this decomposition is to dramatically reduce the size of the search space, and to also prioritize the optimization of off-chip data movement, which is 2-3 orders of magnitude more compared to the on-chip data movement. We introduce {\em Marvel}, which implements the above approach by leveraging two cost models to explore the two subspaces -- a classical distinct-block (DB) locality cost model for the off-chip subspace, and a state-of-the-art DNN accelerator behavioral cost model, MAESTRO, for the on-chip subspace. Our approach also considers dimension permutation, a form of data-layouts, in the mapping space formulation along with the loop transformations.