 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMISIM: An End-to-End Neural Code Similarity System
Jun 15, 2020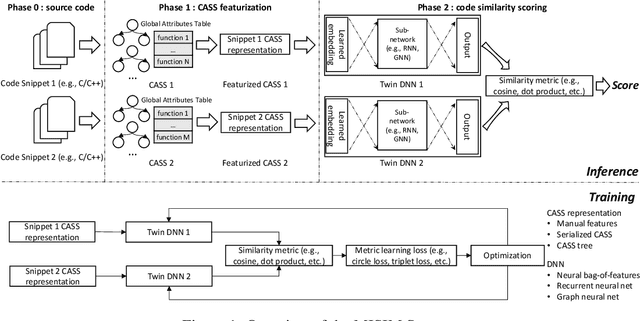
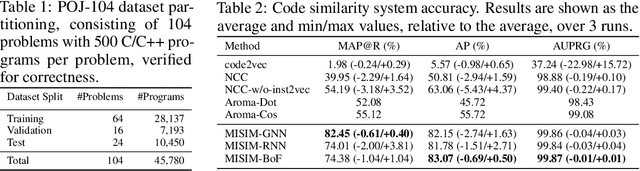
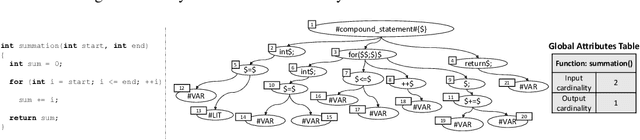
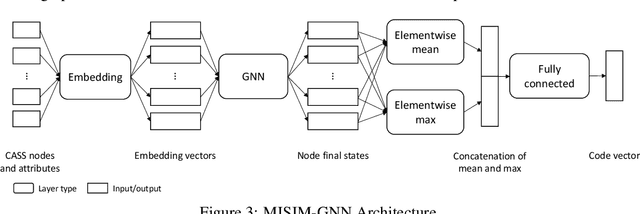
Code similarity systems are integral to a range of applications from code recommendation to automated construction of software tests and defect mitigation. In this paper, we present Machine Inferred Code Similarity (MISIM), a novel end-to-end code similarity system that consists of two core components. First, MISIM uses a novel context-aware similarity structure, which is designed to aid in lifting semantic meaning from code syntax. Second, MISIM provides a neural-based code similarity scoring system, which can be implemented with various neural network algorithms and topologies with learned parameters. We compare MISIM to three other state-of-the-art code similarity systems: (i) code2vec, (ii) Neural Code Comprehension, and (iii) Aroma. In our experimental evaluation across 45,780 programs, MISIM consistently outperformed all three systems, often by a large factor (upwards of 40.6x).
Context-Aware Parse Trees
Mar 24, 2020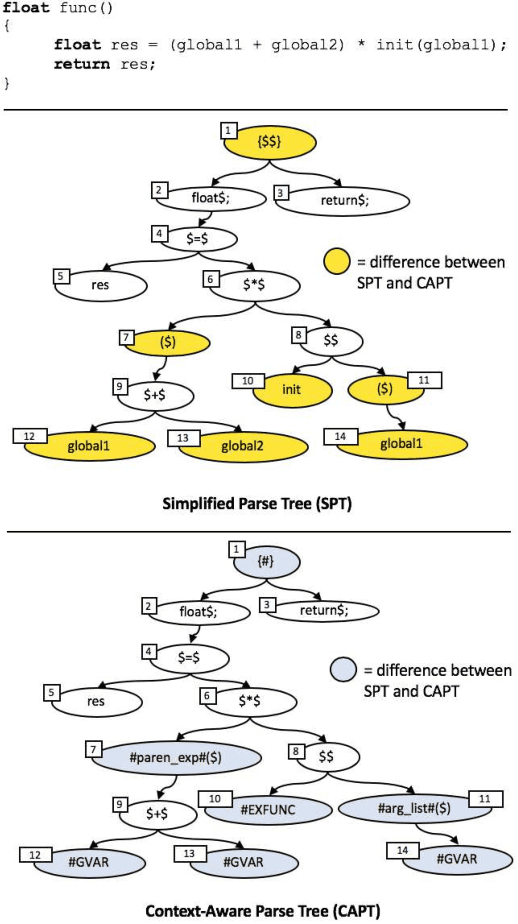
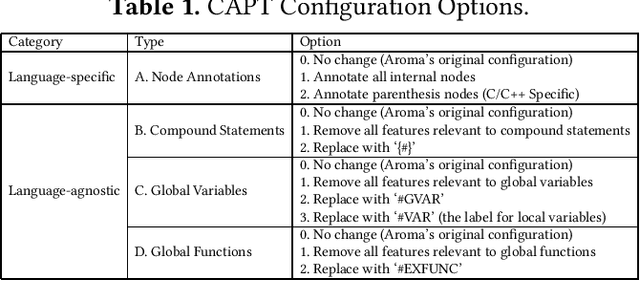
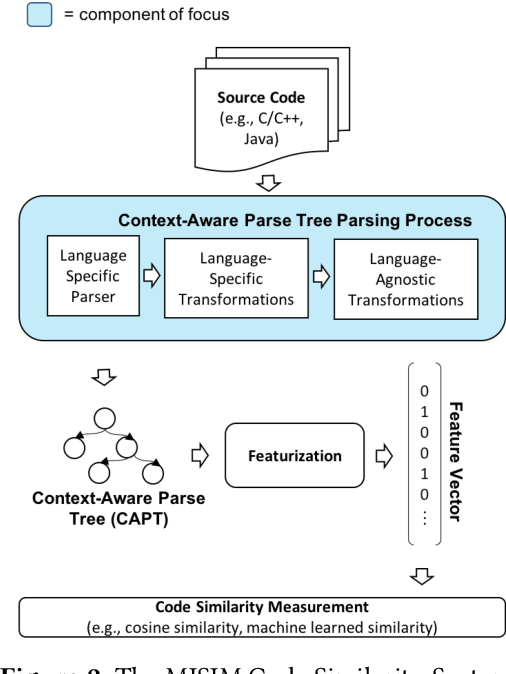
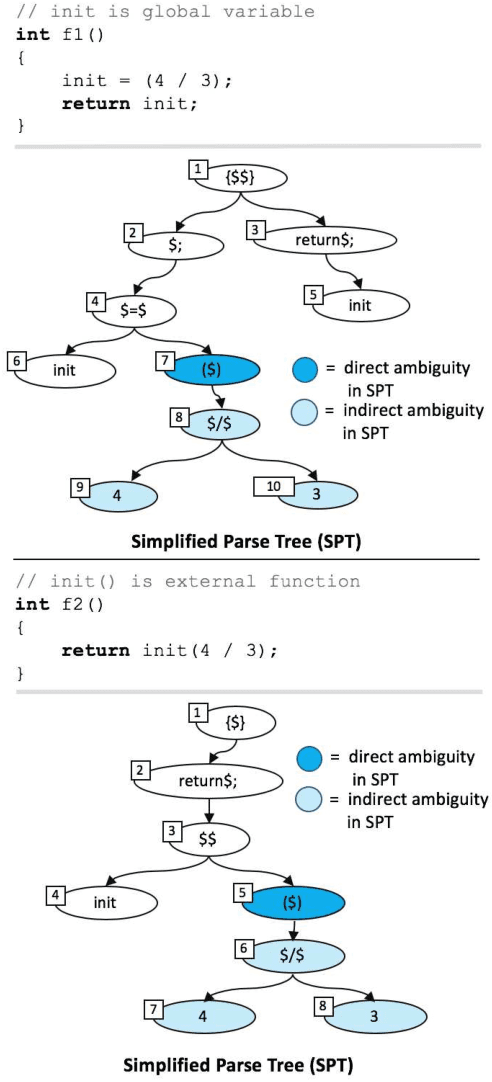
The simplified parse tree (SPT) presented in Aroma, a state-of-the-art code recommendation system, is a tree-structured representation used to infer code semantics by capturing program \emph{structure} rather than program \emph{syntax}. This is a departure from the classical abstract syntax tree, which is principally driven by programming language syntax. While we believe a semantics-driven representation is desirable, the specifics of an SPT's construction can impact its performance. We analyze these nuances and present a new tree structure, heavily influenced by Aroma's SPT, called a \emph{context-aware parse tree} (CAPT). CAPT enhances SPT by providing a richer level of semantic representation. Specifically, CAPT provides additional binding support for language-specific techniques for adding semantically-salient features, and language-agnostic techniques for removing syntactically-present but semantically-irrelevant features. Our research quantitatively demonstrates the value of our proposed semantically-salient features, enabling a specific CAPT configuration to be 39\% more accurate than SPT across the 48,610 programs we analyzed.
High-Performance Deep Learning via a Single Building Block
Jun 18, 2019


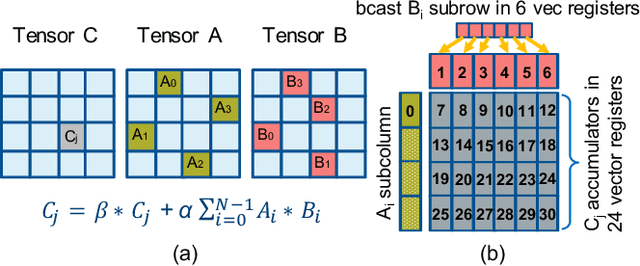
Deep learning (DL) is one of the most prominent branches of machine learning. Due to the immense computational cost of DL workloads, industry and academia have developed DL libraries with highly-specialized kernels for each workload/architecture, leading to numerous, complex code-bases that strive for performance, yet they are hard to maintain and do not generalize. In this work, we introduce the batch-reduce GEMM kernel and show how the most popular DL algorithms can be formulated with this kernel as the basic building-block. Consequently, the DL library-development degenerates to mere (potentially automatic) tuning of loops around this sole optimized kernel. By exploiting our new kernel we implement Recurrent Neural Networks, Convolution Neural Networks and Multilayer Perceptron training and inference primitives in just 3K lines of high-level code. Our primitives outperform vendor-optimized libraries on multi-node CPU clusters, and we also provide proof-of-concept CNN kernels targeting GPUs. Finally, we demonstrate that the batch-reduce GEMM kernel within a tensor compiler yields high-performance CNN primitives, further amplifying the viability of our approach.
ISA Mapper: A Compute and Hardware Agnostic Deep Learning Compiler
Oct 12, 2018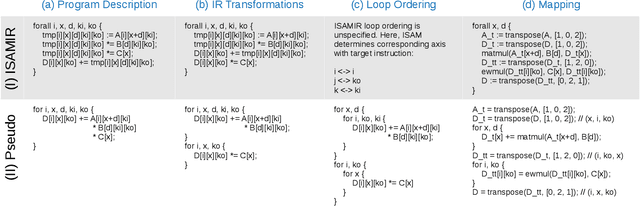
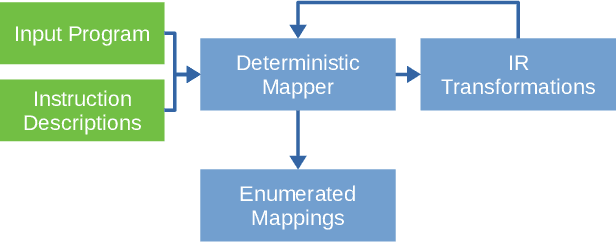
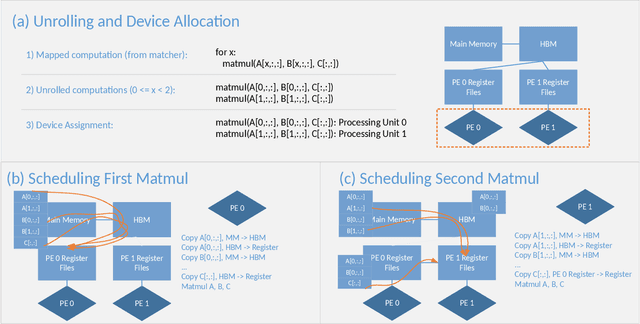
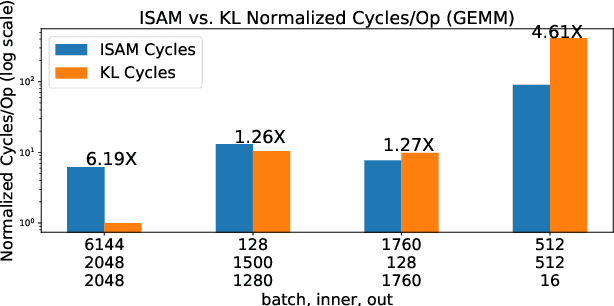
Domain specific accelerators present new challenges and opportunities for code generation onto novel instruction sets, communication fabrics, and memory architectures. In this paper we introduce an intermediate representation (IR) which enables both deep learning computational kernels and hardware capabilities to be described in the same IR. We then formulate and apply instruction mapping to determine the possible ways a computation can be performed on a hardware system. Next, our scheduler chooses a specific mapping and determines the data movement and computation order. In order to manage the large search space of mappings and schedules, we developed a flexible framework that allows heuristics, cost models, and potentially machine learning to facilitate this search problem. With this system, we demonstrate the automated extraction of matrix multiplication kernels out of recent deep learning kernels such as depthwise-separable convolution. In addition, we demonstrate two to five times better performance on DeepBench sized GEMMs and GRU RNN execution when compared to state-of-the-art (SOTA) implementations on new hardware and up to 85% of the performance for SOTA implementations on existing hardware.