 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplementing Neural Network-Based Equalizers in a Coherent Optical Transmission System Using Field-Programmable Gate Arrays
Dec 09, 2022



In this work, we demonstrate the offline FPGA realization of both recurrent and feedforward neural network (NN)-based equalizers for nonlinearity compensation in coherent optical transmission systems. First, we present a realization pipeline showing the conversion of the models from Python libraries to the FPGA chip synthesis and implementation. Then, we review the main alternatives for the hardware implementation of nonlinear activation functions. The main results are divided into three parts: a performance comparison, an analysis of how activation functions are implemented, and a report on the complexity of the hardware. The performance in Q-factor is presented for the cases of bidirectional long-short-term memory coupled with convolutional NN (biLSTM + CNN) equalizer, CNN equalizer, and standard 1-StpS digital back-propagation (DBP) for the simulation and experiment propagation of a single channel dual-polarization (SC-DP) 16QAM at 34 GBd along 17x70km of LEAF. The biLSTM+CNN equalizer provides a similar result to DBP and a 1.7 dB Q-factor gain compared with the chromatic dispersion compensation baseline in the experimental dataset. After that, we assess the Q-factor and the impact of hardware utilization when approximating the activation functions of NN using Taylor series, piecewise linear, and look-up table (LUT) approximations. We also show how to mitigate the approximation errors with extra training and provide some insights into possible gradient problems in the LUT approximation. Finally, to evaluate the complexity of hardware implementation to achieve 400G throughput, fixed-point NN-based equalizers with approximated activation functions are developed and implemented in an FPGA.
Reducing Computational Complexity of Neural Networks in Optical Channel Equalization: From Concepts to Implementation
Aug 26, 2022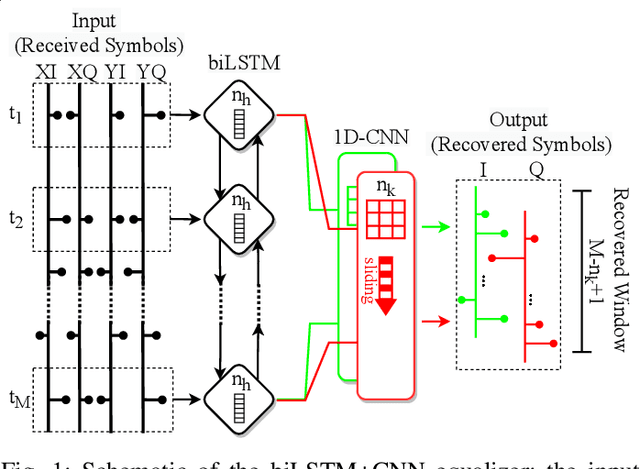
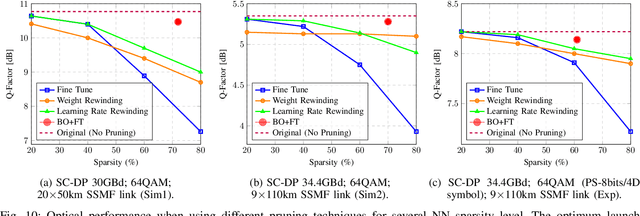
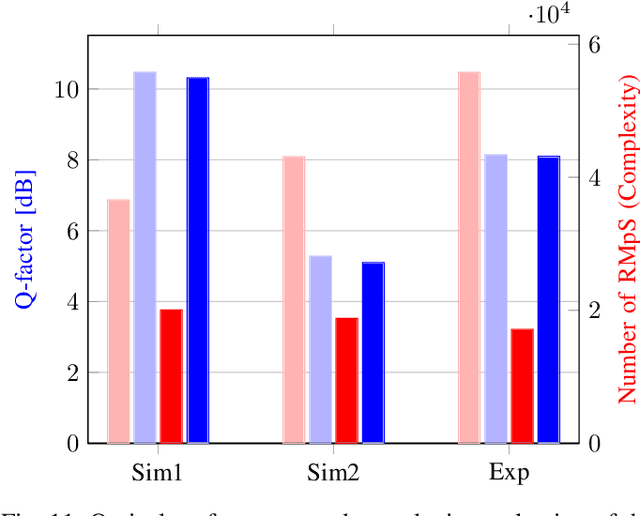
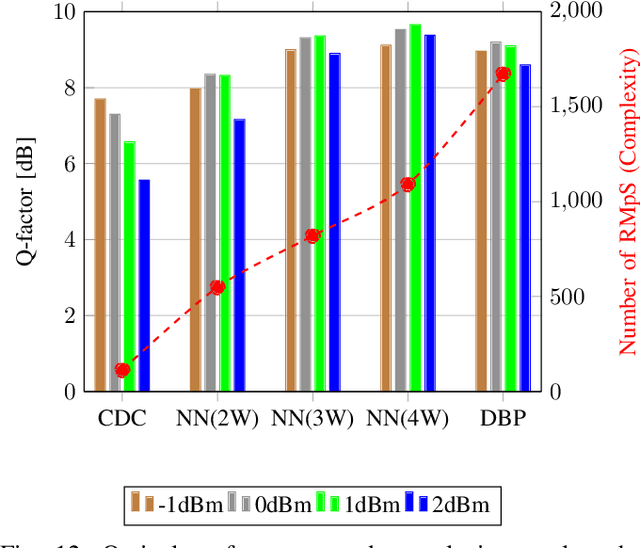
In this paper, a new methodology is proposed that allows for the low-complexity development of neural network (NN) based equalizers for the mitigation of impairments in high-speed coherent optical transmission systems. In this work, we provide a comprehensive description and comparison of various deep model compression approaches that have been applied to feed-forward and recurrent NN designs. Additionally, we evaluate the influence these strategies have on the performance of each NN equalizer. Quantization, weight clustering, pruning, and other cutting-edge strategies for model compression are taken into consideration. In this work, we propose and evaluate a Bayesian optimization-assisted compression, in which the hyperparameters of the compression are chosen to simultaneously reduce complexity and improve performance. In conclusion, the trade-off between the complexity of each compression approach and its performance is evaluated by utilizing both simulated and experimental data in order to complete the analysis. By utilizing optimal compression approaches, we show that it is possible to design an NN-based equalizer that is simpler to implement and has better performance than the conventional digital back-propagation (DBP) equalizer with only one step per span. This is accomplished by reducing the number of multipliers used in the NN equalizer after applying the weighted clustering and pruning algorithms. Furthermore, we demonstrate that an equalizer based on NN can also achieve superior performance while still maintaining the same degree of complexity as the full electronic chromatic dispersion compensation block. We conclude our analysis by highlighting open questions and existing challenges, as well as possible future research directions.
Towards FPGA Implementation of Neural Network-Based Nonlinearity Mitigation Equalizers in Coherent Optical Transmission Systems
Jun 24, 2022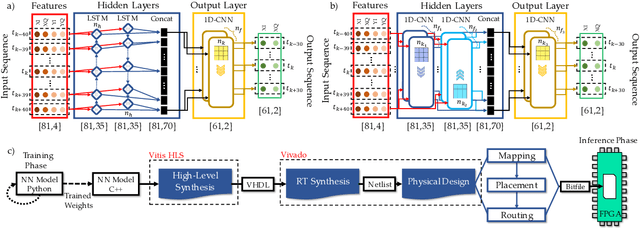
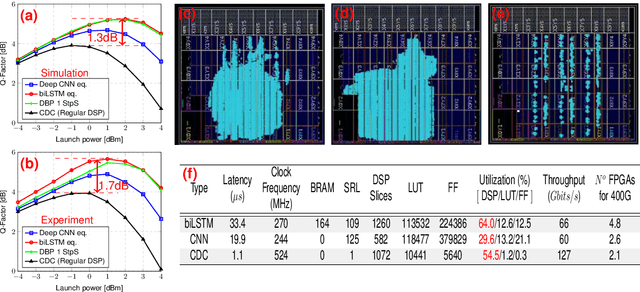
For the first time, recurrent and feedforward neural network-based equalizers for nonlinearity compensation are implemented in an FPGA, with a level of complexity comparable to that of a dispersion equalizer. We demonstrate that the NN-based equalizers can outperform a 1 step-per-span DBP.
High-Performance Deep Learning via a Single Building Block
Jun 18, 2019


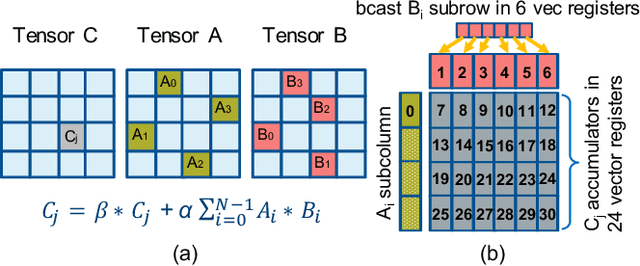
Deep learning (DL) is one of the most prominent branches of machine learning. Due to the immense computational cost of DL workloads, industry and academia have developed DL libraries with highly-specialized kernels for each workload/architecture, leading to numerous, complex code-bases that strive for performance, yet they are hard to maintain and do not generalize. In this work, we introduce the batch-reduce GEMM kernel and show how the most popular DL algorithms can be formulated with this kernel as the basic building-block. Consequently, the DL library-development degenerates to mere (potentially automatic) tuning of loops around this sole optimized kernel. By exploiting our new kernel we implement Recurrent Neural Networks, Convolution Neural Networks and Multilayer Perceptron training and inference primitives in just 3K lines of high-level code. Our primitives outperform vendor-optimized libraries on multi-node CPU clusters, and we also provide proof-of-concept CNN kernels targeting GPUs. Finally, we demonstrate that the batch-reduce GEMM kernel within a tensor compiler yields high-performance CNN primitives, further amplifying the viability of our approach.
Responses to a Critique of Artificial Moral Agents
Mar 17, 2019The field of machine ethics is concerned with the question of how to embed ethical behaviors, or a means to determine ethical behaviors, into artificial intelligence (AI) systems. The goal is to produce artificial moral agents (AMAs) that are either implicitly ethical (designed to avoid unethical consequences) or explicitly ethical (designed to behave ethically). Van Wynsberghe and Robbins' (2018) paper Critiquing the Reasons for Making Artificial Moral Agents critically addresses the reasons offered by machine ethicists for pursuing AMA research; this paper, co-authored by machine ethicists and commentators, aims to contribute to the machine ethics conversation by responding to that critique. The reasons for developing AMAs discussed in van Wynsberghe and Robbins (2018) are: it is inevitable that they will be developed; the prevention of harm; the necessity for public trust; the prevention of immoral use; such machines are better moral reasoners than humans, and building these machines would lead to a better understanding of human morality. In this paper, each co-author addresses those reasons in turn. In so doing, this paper demonstrates that the reasons critiqued are not shared by all co-authors; each machine ethicist has their own reasons for researching AMAs. But while we express a diverse range of views on each of the six reasons in van Wynsberghe and Robbins' critique, we nevertheless share the opinion that the scientific study of AMAs has considerable value.
Representation, Justification and Explanation in a Value Driven Agent: An Argumentation-Based Approach
Dec 13, 2018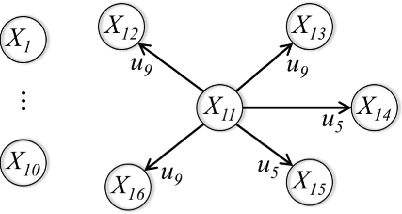
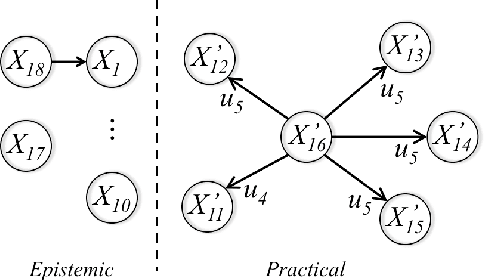
For an autonomous system, the ability to justify and explain its decision making is crucial to improve its transparency and trustworthiness. This paper proposes an argumentation-based approach to represent, justify and explain the decision making of a value driven agent (VDA). By using a newly defined formal language, some implicit knowledge of a VDA is made explicit. The selection of an action in each situation is justified by constructing and comparing arguments supporting different actions. In terms of a constructed argumentation framework and its extensions, the reasons for explaining an action are defined in terms of the arguments for or against the action, by exploiting their defeat relation, as well as their premises and conclusions.
ISA Mapper: A Compute and Hardware Agnostic Deep Learning Compiler
Oct 12, 2018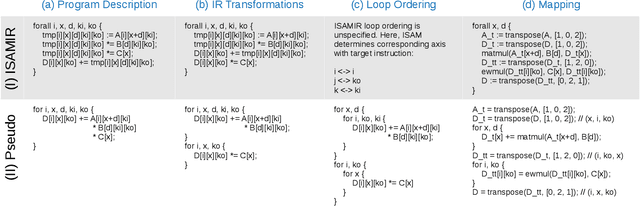
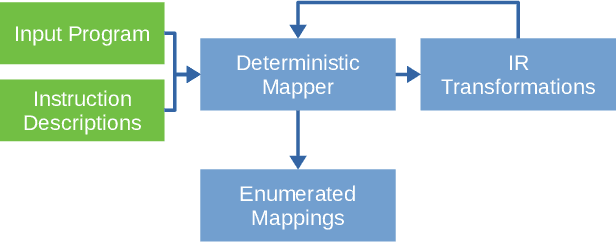
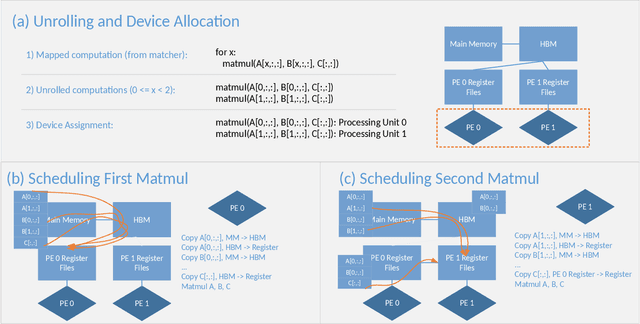
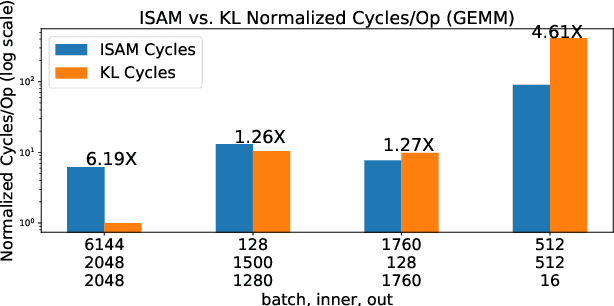
Domain specific accelerators present new challenges and opportunities for code generation onto novel instruction sets, communication fabrics, and memory architectures. In this paper we introduce an intermediate representation (IR) which enables both deep learning computational kernels and hardware capabilities to be described in the same IR. We then formulate and apply instruction mapping to determine the possible ways a computation can be performed on a hardware system. Next, our scheduler chooses a specific mapping and determines the data movement and computation order. In order to manage the large search space of mappings and schedules, we developed a flexible framework that allows heuristics, cost models, and potentially machine learning to facilitate this search problem. With this system, we demonstrate the automated extraction of matrix multiplication kernels out of recent deep learning kernels such as depthwise-separable convolution. In addition, we demonstrate two to five times better performance on DeepBench sized GEMMs and GRU RNN execution when compared to state-of-the-art (SOTA) implementations on new hardware and up to 85% of the performance for SOTA implementations on existing hardware.