 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSysML: The New Frontier of Machine Learning Systems
May 01, 2019Machine learning (ML) techniques are enjoying rapidly increasing adoption. However, designing and implementing the systems that support ML models in real-world deployments remains a significant obstacle, in large part due to the radically different development and deployment profile of modern ML methods, and the range of practical concerns that come with broader adoption. We propose to foster a new systems machine learning research community at the intersection of the traditional systems and ML communities, focused on topics such as hardware systems for ML, software systems for ML, and ML optimized for metrics beyond predictive accuracy. To do this, we describe a new conference, SysML, that explicitly targets research at the intersection of systems and machine learning with a program committee split evenly between experts in systems and ML, and an explicit focus on topics at the intersection of the two.
ISA Mapper: A Compute and Hardware Agnostic Deep Learning Compiler
Oct 12, 2018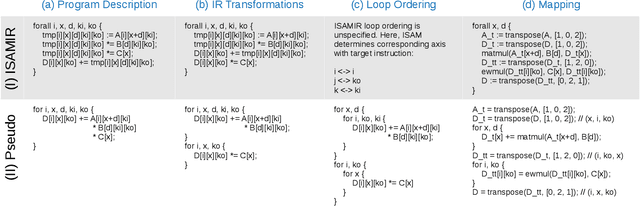
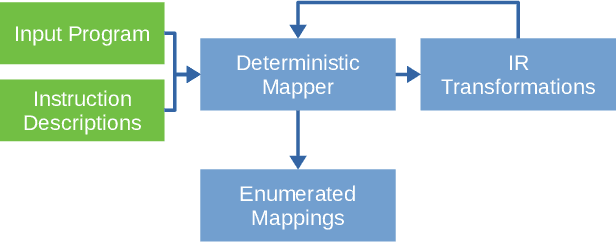
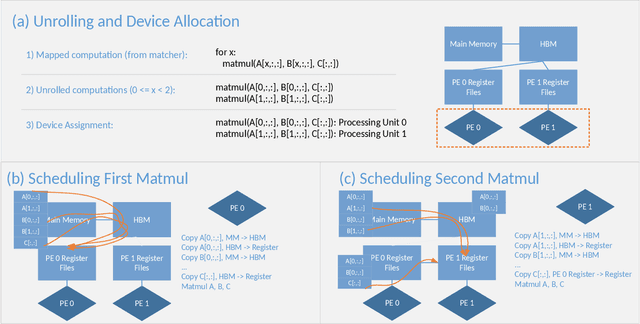
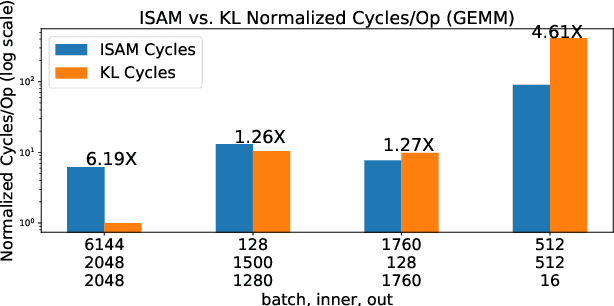
Domain specific accelerators present new challenges and opportunities for code generation onto novel instruction sets, communication fabrics, and memory architectures. In this paper we introduce an intermediate representation (IR) which enables both deep learning computational kernels and hardware capabilities to be described in the same IR. We then formulate and apply instruction mapping to determine the possible ways a computation can be performed on a hardware system. Next, our scheduler chooses a specific mapping and determines the data movement and computation order. In order to manage the large search space of mappings and schedules, we developed a flexible framework that allows heuristics, cost models, and potentially machine learning to facilitate this search problem. With this system, we demonstrate the automated extraction of matrix multiplication kernels out of recent deep learning kernels such as depthwise-separable convolution. In addition, we demonstrate two to five times better performance on DeepBench sized GEMMs and GRU RNN execution when compared to state-of-the-art (SOTA) implementations on new hardware and up to 85% of the performance for SOTA implementations on existing hardware.
Intel nGraph: An Intermediate Representation, Compiler, and Executor for Deep Learning
Jan 30, 2018The Deep Learning (DL) community sees many novel topologies published each year. Achieving high performance on each new topology remains challenging, as each requires some level of manual effort. This issue is compounded by the proliferation of frameworks and hardware platforms. The current approach, which we call "direct optimization", requires deep changes within each framework to improve the training performance for each hardware backend (CPUs, GPUs, FPGAs, ASICs) and requires $\mathcal{O}(fp)$ effort; where $f$ is the number of frameworks and $p$ is the number of platforms. While optimized kernels for deep-learning primitives are provided via libraries like Intel Math Kernel Library for Deep Neural Networks (MKL-DNN), there are several compiler-inspired ways in which performance can be further optimized. Building on our experience creating neon (a fast deep learning library on GPUs), we developed Intel nGraph, a soon to be open-sourced C++ library to simplify the realization of optimized deep learning performance across frameworks and hardware platforms. Initially-supported frameworks include TensorFlow, MXNet, and Intel neon framework. Initial backends are Intel Architecture CPUs (CPU), the Intel(R) Nervana Neural Network Processor(R) (NNP), and NVIDIA GPUs. Currently supported compiler optimizations include efficient memory management and data layout abstraction. In this paper, we describe our overall architecture and its core components. In the future, we envision extending nGraph API support to a wider range of frameworks, hardware (including FPGAs and ASICs), and compiler optimizations (training versus inference optimizations, multi-node and multi-device scaling via efficient sub-graph partitioning, and HW-specific compounding of operations).