 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Ultra: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Jun 12, 2026We introduce Nemotron 3 Ultra, a 550 billion total and 55 billion active parameter Mixture-of-Experts Hybrid Mamba-Attention language model. We pre-trained Nemotron 3 Ultra on 20 trillion text tokens, then extended the context length to 1M tokens, and post-trained using Supervised Fine Tuning (SFT), Reinforcement Learning (RL), and Multi-teacher On-Policy Distillation (MOPD). Nemotron 3 Ultra is our most capable model yet, employing multiple key technologies - LatentMoE, Multi Token Prediction (MTP), NVFP4 pre-training, multi-environment RLVR, MOPD, and reasoning budget control. Nemotron 3 Ultra achieves up to ~6x higher inference throughput as compared to state-of-the-art publicly available LLMs while attaining on-par accuracy. The state-of-the-art accuracy, high inference throughput, and 1M token context length make Nemotron 3 Ultra ideal for long-running autonomous agentic tasks. We open-source the base, post-trained, and quantized checkpoints, along with the training data and recipe on HuggingFace.
Hybrid Verified Decoding: Learning to Allocate Verification in Speculative Decoding
May 31, 2026Large Language Model (LLM) generation remains expensive because autoregressive decoding calls the model once for each new token. Speculative decoding reduces this cost by drafting multiple tokens and verifying them with the target model in one step, but its speedup depends on how many drafted tokens are accepted. Parameter-free draft sources can propose long continuations at low cost in structured and agentic workloads, yet a cache match that looks promising at one generation step may have low payoff at the next. We propose Hybrid Verified Decoding, which predicts the accepted length of a cache draft before verification and uses this payoff estimate to choose between cache verification and a model-based drafter. Across three LLMs and sixteen datasets, Hybrid Verified Decoding is especially effective on agentic workflows, where it outperforms EAGLE3 in every setting with a 2.73x average speedup. Our analysis shows how prompt structure creates cache opportunities, how high-payoff cache drafts concentrate in a small part of the draft space, and how payoff-guided selection reduces sequential decoding work, pointing to runtime draft selection as a promising direction for speculative decoding.
Nemotron 3 Nano Omni: Efficient and Open Multimodal Intelligence
Apr 27, 2026We introduce Nemotron 3 Nano Omni, the latest model in the Nemotron multimodal series and the first to natively support audio inputs alongside text, images, and video. Nemotron 3 Nano Omni delivers consistent accuracy improvements over its predecessor, Nemotron Nano V2 VL, across all modalities, enabled by advances in architecture, training data and recipes. In particular, Nemotron 3 delivers leading results in real-world document understanding, long audio-video comprehension, and agentic computer use. Built on the highly efficient Nemotron 3 Nano 30B-A3B backbone, Nemotron 3 Nano Omni further incorporates innovative multimodal token-reduction techniques to deliver substantially lower inference latency and higher throughput than other models of similar size. We are releasing model checkpoints in BF16, FP8, and FP4 formats, along with portions of the training data and codebase to facilitate further research and development.
Nemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Apr 14, 2026We describe the pre-training, post-training, and quantization of Nemotron 3 Super, a 120 billion (active 12 billion) parameter hybrid Mamba-Attention Mixture-of-Experts model. Nemotron 3 Super is the first model in the Nemotron 3 family to 1) be pre-trained in NVFP4, 2) leverage LatentMoE, a new Mixture-of-Experts architecture that optimizes for both accuracy per FLOP and accuracy per parameter, and 3) include MTP layers for inference acceleration through native speculative decoding. We pre-trained Nemotron 3 Super on 25 trillion tokens followed by post-training using supervised fine tuning (SFT) and reinforcement learning (RL). The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2x and 7.5x higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively. Nemotron 3 Super datasets, along with the base, post-trained, and quantized checkpoints, are open-sourced on HuggingFace.
NVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
Llama-Nemotron: Efficient Reasoning Models
May 02, 2025



We introduce the Llama-Nemotron series of models, an open family of heterogeneous reasoning models that deliver exceptional reasoning capabilities, inference efficiency, and an open license for enterprise use. The family comes in three sizes -- Nano (8B), Super (49B), and Ultra (253B) -- and performs competitively with state-of-the-art reasoning models such as DeepSeek-R1 while offering superior inference throughput and memory efficiency. In this report, we discuss the training procedure for these models, which entails using neural architecture search from Llama 3 models for accelerated inference, knowledge distillation, and continued pretraining, followed by a reasoning-focused post-training stage consisting of two main parts: supervised fine-tuning and large scale reinforcement learning. Llama-Nemotron models are the first open-source models to support a dynamic reasoning toggle, allowing users to switch between standard chat and reasoning modes during inference. To further support open research and facilitate model development, we provide the following resources: 1. We release the Llama-Nemotron reasoning models -- LN-Nano, LN-Super, and LN-Ultra -- under the commercially permissive NVIDIA Open Model License Agreement. 2. We release the complete post-training dataset: Llama-Nemotron-Post-Training-Dataset. 3. We also release our training codebases: NeMo, NeMo-Aligner, and Megatron-LM.
LVLM-Compress-Bench: Benchmarking the Broader Impact of Large Vision-Language Model Compression
Mar 06, 2025Despite recent efforts in understanding the compression impact on large language models (LLMs) in terms of their downstream task performance and trustworthiness on relatively simpler uni-modal benchmarks (for example, question answering, common sense reasoning), their detailed study on multi-modal Large Vision-Language Models (LVLMs) is yet to be unveiled. Towards mitigating this gap, we present LVLM-Compress-Bench, a framework to first thoroughly study the broad impact of compression on the generative performance of LVLMs with multi-modal input driven tasks. In specific, we consider two major classes of compression for autoregressive models, namely KV cache and weight compression, for the dynamically growing intermediate cache and static weights, respectively. We use four LVLM variants of the popular LLaVA framework to present our analysis via integrating various state-of-the-art KV and weight compression methods including uniform, outlier-reduced, and group quantization for the KV cache and weights. With this framework we demonstrate on ten different multi-modal datasets with different capabilities including recognition, knowledge, language generation, spatial awareness, visual reasoning, hallucination and visual illusion identification, toxicity, stereotypes and bias. In specific, our framework demonstrates the compression impact on both general and ethically critical metrics leveraging a combination of real world and synthetic datasets to encompass diverse societal intersectional attributes. Extensive experimental evaluations yield diverse and intriguing observations on the behavior of LVLMs at different quantization budget of KV and weights, in both maintaining and losing performance as compared to the baseline model with FP16 data format. Code will be open-sourced at https://github.com/opengear-project/LVLM-compress-bench.
ClimDetect: A Benchmark Dataset for Climate Change Detection and Attribution
Aug 28, 2024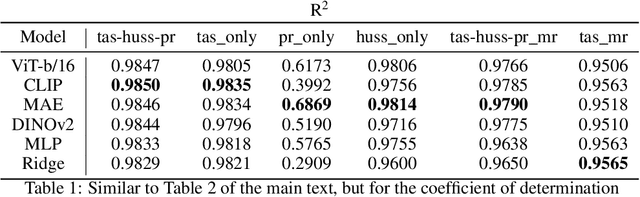
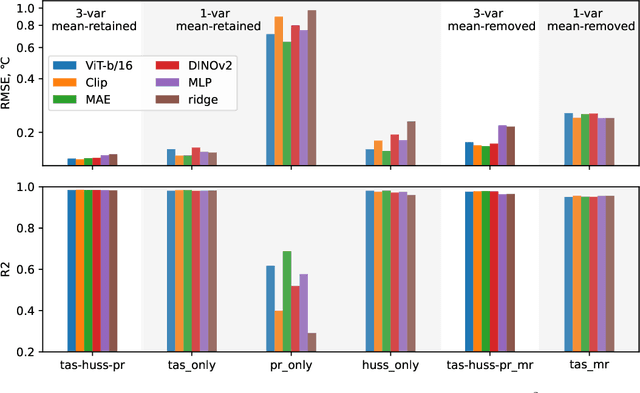
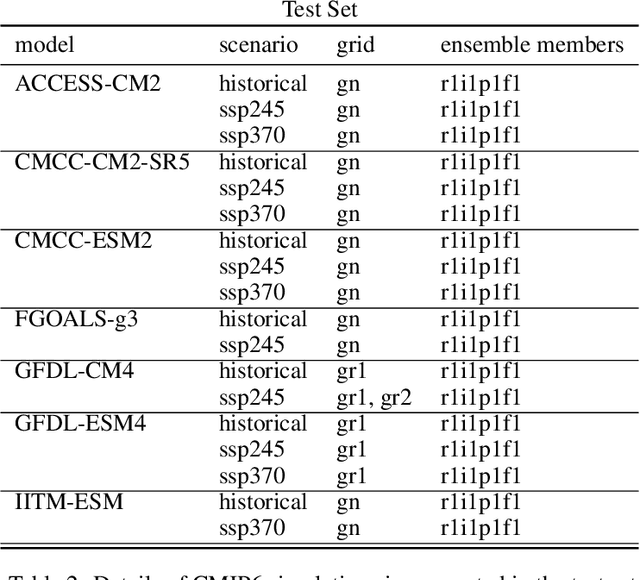
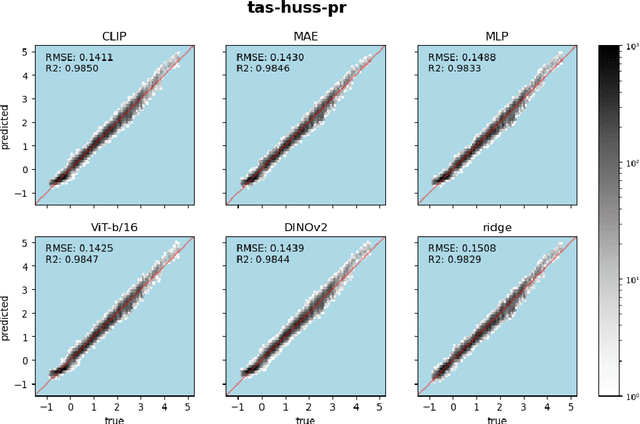
Detecting and attributing temperature increases due to climate change is crucial for understanding global warming and guiding adaptation strategies. The complexity of distinguishing human-induced climate signals from natural variability has challenged traditional detection and attribution (D&A) approaches, which seek to identify specific "fingerprints" in climate response variables. Deep learning offers potential for discerning these complex patterns in expansive spatial datasets. However, lack of standard protocols has hindered consistent comparisons across studies. We introduce ClimDetect, a standardized dataset of over 816k daily climate snapshots, designed to enhance model accuracy in identifying climate change signals. ClimDetect integrates various input and target variables used in past research, ensuring comparability and consistency. We also explore the application of vision transformers (ViT) to climate data, a novel and modernizing approach in this context. Our open-access data and code serve as a benchmark for advancing climate science through improved model evaluations. ClimDetect is publicly accessible via Huggingface dataet respository at: https://huggingface.co/datasets/ClimDetect/ClimDetect.
Why do LLaVA Vision-Language Models Reply to Images in English?
Jul 02, 2024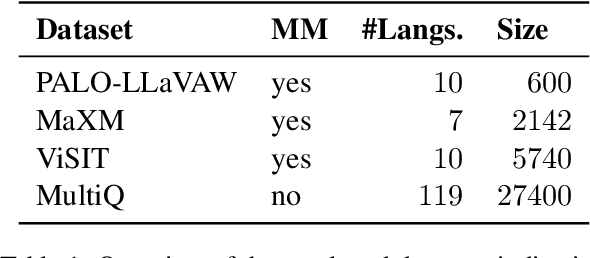
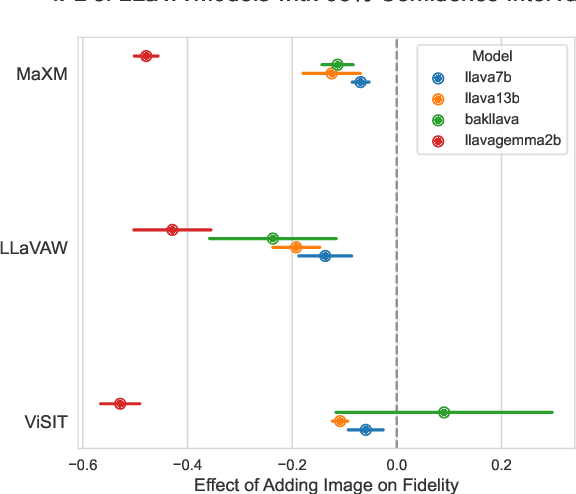
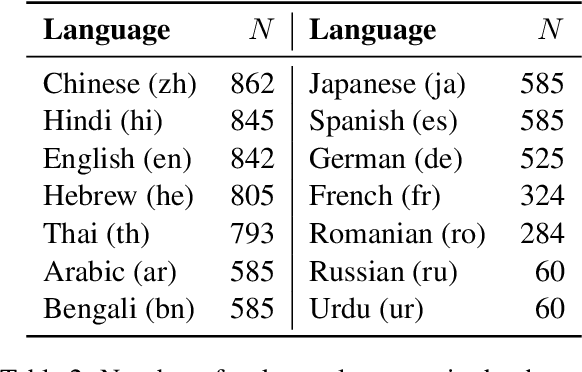
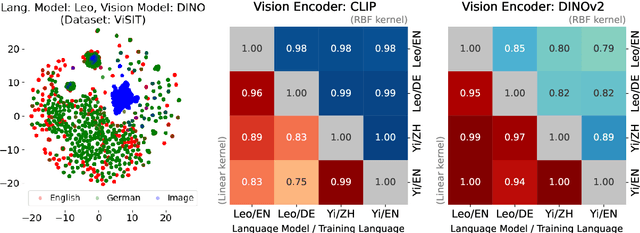
We uncover a surprising multilingual bias occurring in a popular class of multimodal vision-language models (VLMs). Including an image in the query to a LLaVA-style VLM significantly increases the likelihood of the model returning an English response, regardless of the language of the query. This paper investigates the causes of this loss with a two-pronged approach that combines extensive ablation of the design space with a mechanistic analysis of the models' internal representations of image and text inputs. Both approaches indicate that the issue stems in the language modelling component of the LLaVA model. Statistically, we find that switching the language backbone for a bilingual language model has the strongest effect on reducing this error. Mechanistically, we provide compelling evidence that visual inputs are not mapped to a similar space as text ones, and that intervening on intermediary attention layers can reduce this bias. Our findings provide important insights to researchers and engineers seeking to understand the crossover between multimodal and multilingual spaces, and contribute to the goal of developing capable and inclusive VLMs for non-English contexts.