 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRIME: Phase Reversed Interleaved Multi-Echo acquisition enables highly accelerated distortion-free diffusion MRI
Sep 11, 2024


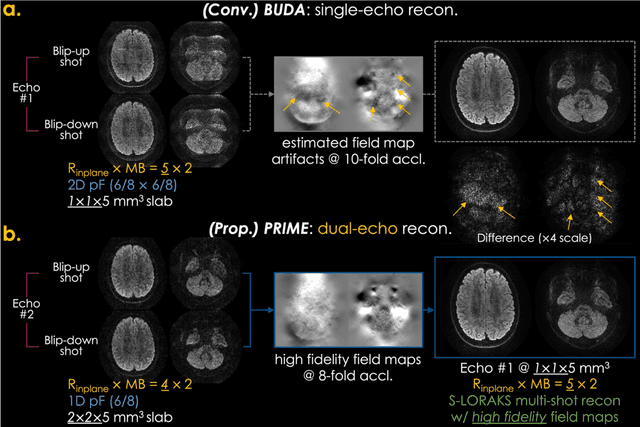
Purpose: To develop and evaluate a new pulse sequence for highly accelerated distortion-free diffusion MRI (dMRI) by inserting an additional echo without prolonging TR, when generalized slice dithered enhanced resolution (gSlider) radiofrequency encoding is used for volumetric acquisition. Methods: A phase-reversed interleaved multi-echo acquisition (PRIME) was developed for rapid, high-resolution, and distortion-free dMRI, which includes two echoes where the first echo is for target diffusion-weighted imaging (DWI) acquisition with high-resolution and the second echo is acquired with either 1) lower-resolution for high-fidelity field map estimation, or 2) matching resolution to enable efficient diffusion relaxometry acquisitions. The sequence was evaluated on in vivo data acquired from healthy volunteers on clinical and Connectome 2.0 scanners. Results: In vivo experiments demonstrated that 1) high in-plane acceleration (Rin-plane of 5-fold with 2D partial Fourier) was achieved using the high-fidelity field maps estimated from the second echo, which was made at a lower resolution/acceleration to increase its SNR while matching the effective echo spacing of the first readout, 2) high-resolution diffusion relaxometry parameters were estimated from dual-echo PRIME data using a white matter model of multi-TE spherical mean technique (MTE-SMT), and 3) high-fidelity mesoscale DWI at 550 um isotropic resolution could be obtained in vivo by capitalizing on the high-performance gradients of the Connectome 2.0 scanner. Conclusion: The proposed PRIME sequence enabled highly accelerated, high-resolution, and distortion-free dMRI using an additional echo without prolonging scan time when gSlider encoding is utilized.
High-resolution myelin-water fraction and quantitative relaxation mapping using 3D ViSTa-MR fingerprinting
Dec 21, 2023Purpose: This study aims to develop a high-resolution whole-brain multi-parametric quantitative MRI approach for simultaneous mapping of myelin-water fraction (MWF), T1, T2, and proton-density (PD), all within a clinically feasible scan time. Methods: We developed 3D ViSTa-MRF, which combined Visualization of Short Transverse relaxation time component (ViSTa) technique with MR Fingerprinting (MRF), to achieve high-fidelity whole-brain MWF and T1/T2/PD mapping on a clinical 3T scanner. To achieve fast acquisition and memory-efficient reconstruction, the ViSTa-MRF sequence leverages an optimized 3D tiny-golden-angle-shuffling spiral-projection acquisition and joint spatial-temporal subspace reconstruction with optimized preconditioning algorithm. With the proposed ViSTa-MRF approach, high-fidelity direct MWF mapping was achieved without a need for multi-compartment fitting that could introduce bias and/or noise from additional assumptions or priors. Results: The in-vivo results demonstrate the effectiveness of the proposed acquisition and reconstruction framework to provide fast multi-parametric mapping with high SNR and good quality. The in-vivo results of 1mm- and 0.66mm-iso datasets indicate that the MWF values measured by the proposed method are consistent with standard ViSTa results that are 30x slower with lower SNR. Furthermore, we applied the proposed method to enable 5-minute whole-brain 1mm-iso assessment of MWF and T1/T2/PD mappings for infant brain development and for post-mortem brain samples. Conclusions: In this work, we have developed a 3D ViSTa-MRF technique that enables the acquisition of whole-brain MWF, quantitative T1, T2, and PD maps at 1mm and 0.66mm isotropic resolution in 5 and 15 minutes, respectively. This advancement allows for quantitative investigations of myelination changes in the brain.
Patch-CNN: Training data-efficient deep learning for high-fidelity diffusion tensor estimation from minimal diffusion protocols
Jul 03, 2023We propose a new method, Patch-CNN, for diffusion tensor (DT) estimation from only six-direction diffusion weighted images (DWI). Deep learning-based methods have been recently proposed for dMRI parameter estimation, using either voxel-wise fully-connected neural networks (FCN) or image-wise convolutional neural networks (CNN). In the acute clinical context -- where pressure of time limits the number of imaged directions to a minimum -- existing approaches either require an infeasible number of training images volumes (image-wise CNNs), or do not estimate the fibre orientations (voxel-wise FCNs) required for tractogram estimation. To overcome these limitations, we propose Patch-CNN, a neural network with a minimal (non-voxel-wise) convolutional kernel (3$\times$3$\times$3). Compared with voxel-wise FCNs, this has the advantage of allowing the network to leverage local anatomical information. Compared with image-wise CNNs, the minimal kernel vastly reduces training data demand. Evaluated against both conventional model fitting and a voxel-wise FCN, Patch-CNN, trained with a single subject is shown to improve the estimation of both scalar dMRI parameters and fibre orientation from six-direction DWIs. The improved fibre orientation estimation is shown to produce improved tractogram.
Optimized multi-axis spiral projection MR fingerprinting with subspace reconstruction for rapid whole-brain high-isotropic-resolution quantitative imaging
Aug 12, 2021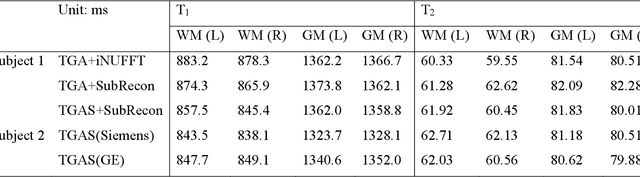

Purpose: To improve image quality and accelerate the acquisition of 3D MRF. Methods: Building on the multi-axis spiral-projection MRF technique, a subspace reconstruction with locally low rank (LLR) constraint and a modified spiral-projection spatiotemporal encoding scheme termed tiny-golden-angle-shuffling (TGAS) were implemented for rapid whole-brain high-resolution quantitative mapping. The LLR regularization parameter and the number of subspace bases were tuned using retrospective in-vivo data and simulated examinations, respectively. B0 inhomogeneity correction using multi-frequency interpolation was incorporated into the subspace reconstruction to further improve the image quality by mitigating blurring caused by off-resonance effect. Results: The proposed MRF acquisition and reconstruction framework can produce provide high quality 1-mm isotropic whole-brain quantitative maps in a total acquisition time of 1 minute 55 seconds, with higher-quality results than ones obtained from the previous approach in 6 minutes. The comparison of quantitative results indicates that neither the subspace reconstruction nor the TGAS trajectory induce bias for T1 and T2 mapping. High quality whole-brain MRF data were also obtained at 0.66-mm isotropic resolution in 4 minutes using the proposed technique, where the increased resolution was shown to improve visualization of subtle brain structures. Conclusion: The proposed TGAS-SPI-MRF with optimized spiral-projection trajectory and subspace reconstruction can enable high-resolution quantitative mapping with faster acquisition speed.
Shifted and Squeezed 8-bit Floating Point format for Low-Precision Training of Deep Neural Networks
Jan 16, 2020

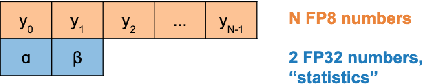

Training with larger number of parameters while keeping fast iterations is an increasingly adopted strategy and trend for developing better performing Deep Neural Network (DNN) models. This necessitates increased memory footprint and computational requirements for training. Here we introduce a novel methodology for training deep neural networks using 8-bit floating point (FP8) numbers. Reduced bit precision allows for a larger effective memory and increased computational speed. We name this method Shifted and Squeezed FP8 (S2FP8). We show that, unlike previous 8-bit precision training methods, the proposed method works out-of-the-box for representative models: ResNet-50, Transformer and NCF. The method can maintain model accuracy without requiring fine-tuning loss scaling parameters or keeping certain layers in single precision. We introduce two learnable statistics of the DNN tensors - shifted and squeezed factors that are used to optimally adjust the range of the tensors in 8-bits, thus minimizing the loss in information due to quantization.
Label-efficient audio classification through multitask learning and self-supervision
Oct 19, 2019
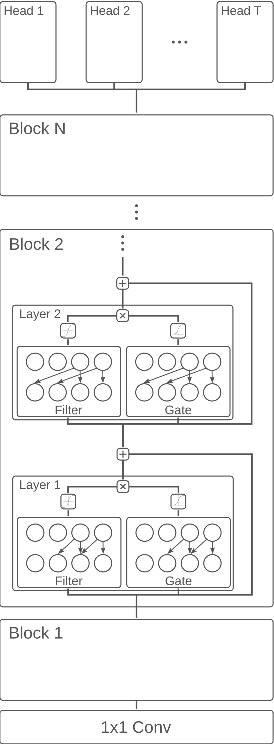
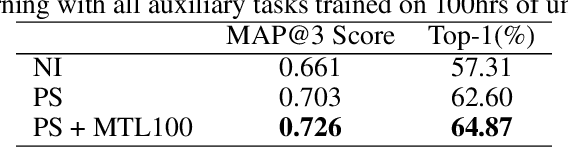
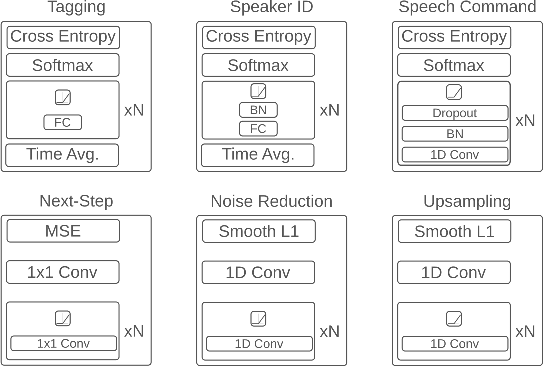
While deep learning has been incredibly successful in modeling tasks with large, carefully curated labeled datasets, its application to problems with limited labeled data remains a challenge. The aim of the present work is to improve the label efficiency of large neural networks operating on audio data through a combination of multitask learning and self-supervised learning on unlabeled data. We trained an end-to-end audio feature extractor based on WaveNet that feeds into simple, yet versatile task-specific neural networks. We describe several easily implemented self-supervised learning tasks that can operate on any large, unlabeled audio corpus. We demonstrate that, in scenarios with limited labeled training data, one can significantly improve the performance of three different supervised classification tasks individually by up to 6% through simultaneous training with these additional self-supervised tasks. We also show that incorporating data augmentation into our multitask setting leads to even further gains in performance.