 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizable automated ischaemic stroke lesion segmentation with vision transformers
Feb 10, 2025
Ischaemic stroke, a leading cause of death and disability, critically relies on neuroimaging for characterising the anatomical pattern of injury. Diffusion-weighted imaging (DWI) provides the highest expressivity in ischemic stroke but poses substantial challenges for automated lesion segmentation: susceptibility artefacts, morphological heterogeneity, age-related comorbidities, time-dependent signal dynamics, instrumental variability, and limited labelled data. Current U-Net-based models therefore underperform, a problem accentuated by inadequate evaluation metrics that focus on mean performance, neglecting anatomical, subpopulation, and acquisition-dependent variability. Here, we present a high-performance DWI lesion segmentation tool addressing these challenges through optimized vision transformer-based architectures, integration of 3563 annotated lesions from multi-site data, and algorithmic enhancements, achieving state-of-the-art results. We further propose a novel evaluative framework assessing model fidelity, equity (across demographics and lesion subtypes), anatomical precision, and robustness to instrumental variability, promoting clinical and research utility. This work advances stroke imaging by reconciling model expressivity with domain-specific challenges and redefining performance benchmarks to prioritize equity and generalizability, critical for personalized medicine and mechanistic research.
Deep generative computed perfusion-deficit mapping of ischaemic stroke
Feb 03, 2025



Focal deficits in ischaemic stroke result from impaired perfusion downstream of a critical vascular occlusion. While parenchymal lesions are traditionally used to predict clinical deficits, the underlying pattern of disrupted perfusion provides information upstream of the lesion, potentially yielding earlier predictive and localizing signals. Such perfusion maps can be derived from routine CT angiography (CTA) widely deployed in clinical practice. Analysing computed perfusion maps from 1,393 CTA-imaged-patients with acute ischaemic stroke, we use deep generative inference to localise neural substrates of NIHSS sub-scores. We show that our approach replicates known lesion-deficit relations without knowledge of the lesion itself and reveals novel neural dependents. The high achieved anatomical fidelity suggests acute CTA-derived computed perfusion maps may be of substantial clinical-and-scientific value in rich phenotyping of acute stroke. Using only hyperacute imaging, deep generative inference could power highly expressive models of functional anatomical relations in ischaemic stroke within the pre-interventional window.
Patch-CNN: Training data-efficient deep learning for high-fidelity diffusion tensor estimation from minimal diffusion protocols
Jul 03, 2023We propose a new method, Patch-CNN, for diffusion tensor (DT) estimation from only six-direction diffusion weighted images (DWI). Deep learning-based methods have been recently proposed for dMRI parameter estimation, using either voxel-wise fully-connected neural networks (FCN) or image-wise convolutional neural networks (CNN). In the acute clinical context -- where pressure of time limits the number of imaged directions to a minimum -- existing approaches either require an infeasible number of training images volumes (image-wise CNNs), or do not estimate the fibre orientations (voxel-wise FCNs) required for tractogram estimation. To overcome these limitations, we propose Patch-CNN, a neural network with a minimal (non-voxel-wise) convolutional kernel (3$\times$3$\times$3). Compared with voxel-wise FCNs, this has the advantage of allowing the network to leverage local anatomical information. Compared with image-wise CNNs, the minimal kernel vastly reduces training data demand. Evaluated against both conventional model fitting and a voxel-wise FCN, Patch-CNN, trained with a single subject is shown to improve the estimation of both scalar dMRI parameters and fibre orientation from six-direction DWIs. The improved fibre orientation estimation is shown to produce improved tractogram.
Deep Variational Lesion-Deficit Mapping
May 27, 2023Causal mapping of the functional organisation of the human brain requires evidence of \textit{necessity} available at adequate scale only from pathological lesions of natural origin. This demands inferential models with sufficient flexibility to capture both the observable distribution of pathological damage and the unobserved distribution of the neural substrate. Current model frameworks -- both mass-univariate and multivariate -- either ignore distributed lesion-deficit relations or do not model them explicitly, relying on featurization incidental to a predictive task. Here we initiate the application of deep generative neural network architectures to the task of lesion-deficit inference, formulating it as the estimation of an expressive hierarchical model of the joint lesion and deficit distributions conditioned on a latent neural substrate. We implement such deep lesion deficit inference with variational convolutional volumetric auto-encoders. We introduce a comprehensive framework for lesion-deficit model comparison, incorporating diverse candidate substrates, forms of substrate interactions, sample sizes, noise corruption, and population heterogeneity. Drawing on 5500 volume images of ischaemic stroke, we show that our model outperforms established methods by a substantial margin across all simulation scenarios, including comparatively small-scale and noisy data regimes. Our analysis justifies the widespread adoption of this approach, for which we provide an open source implementation: https://github.com/guilherme-pombo/vae_lesion_deficit
How can spherical CNNs benefit ML-based diffusion MRI parameter estimation?
Jul 01, 2022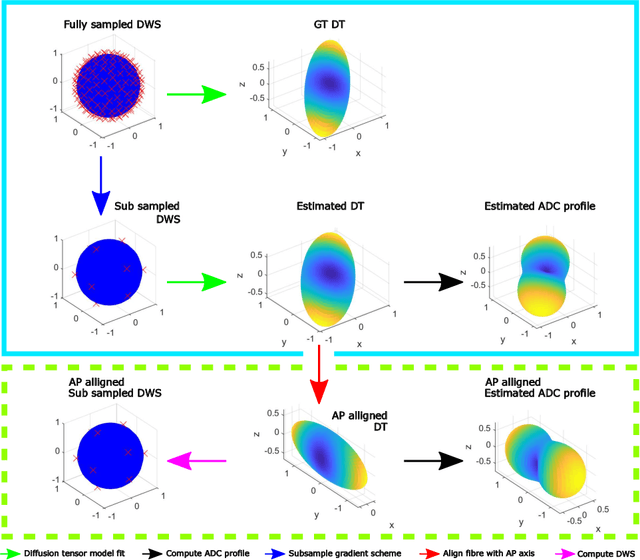
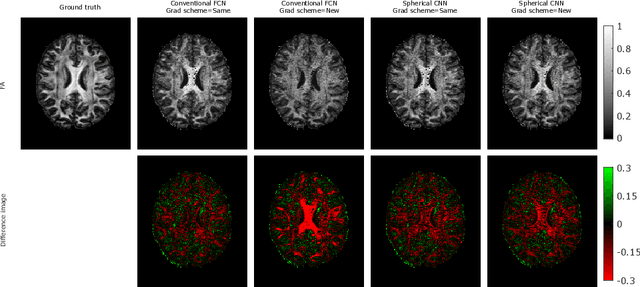
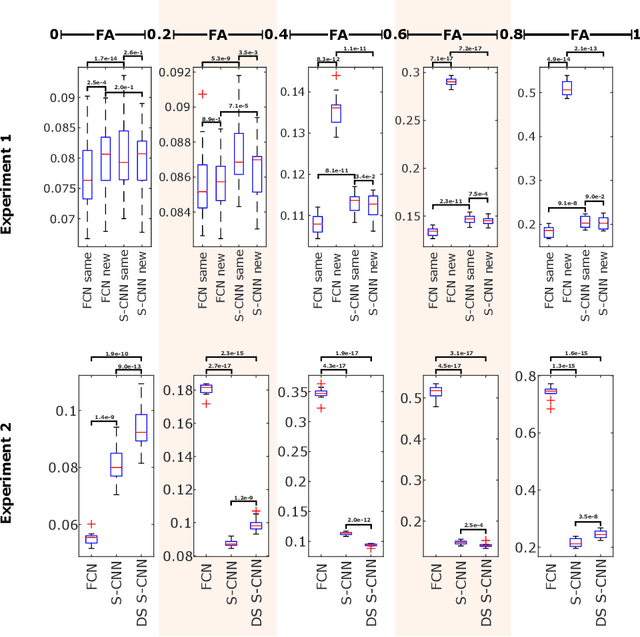
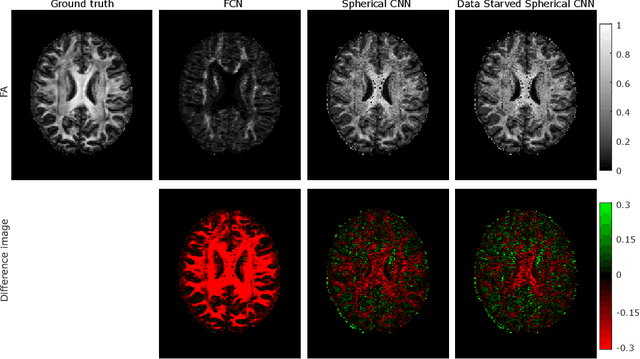
This paper demonstrates spherical convolutional neural networks (S-CNN) offer distinct advantages over conventional fully-connected networks (FCN) at estimating scalar parameters of tissue microstructure from diffusion MRI (dMRI). Such microstructure parameters are valuable for identifying pathology and quantifying its extent. However, current clinical practice commonly acquires dMRI data consisting of only 6 diffusion weighted images (DWIs), limiting the accuracy and precision of estimated microstructure indices. Machine learning (ML) has been proposed to address this challenge. However, existing ML-based methods are not robust to differing dMRI gradient sampling schemes, nor are they rotation equivariant. Lack of robustness to sampling schemes requires a new network to be trained for each scheme, complicating the analysis of data from multiple sources. A possible consequence of the lack of rotational equivariance is that the training dataset must contain a diverse range of microstucture orientations. Here, we show spherical CNNs represent a compelling alternative that is robust to new sampling schemes as well as offering rotational equivariance. We show the latter can be leveraged to decrease the number of training datapoints required.
Fast Unsupervised Brain Anomaly Detection and Segmentation with Diffusion Models
Jun 07, 2022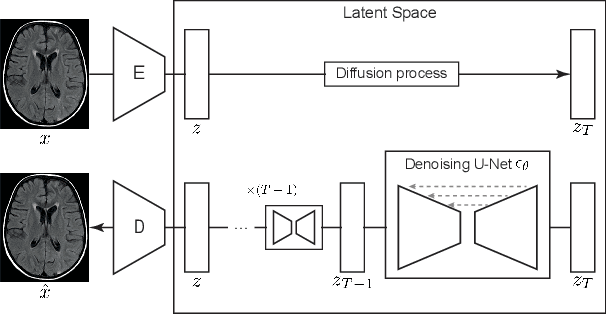
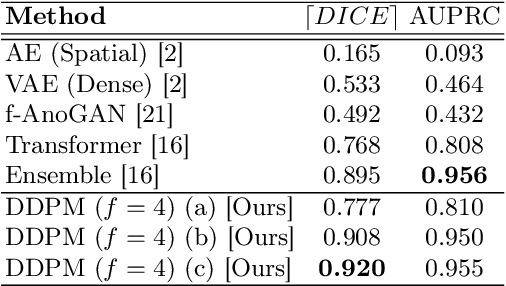
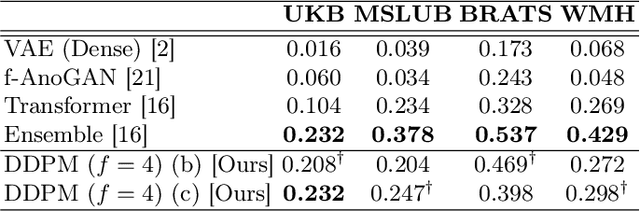
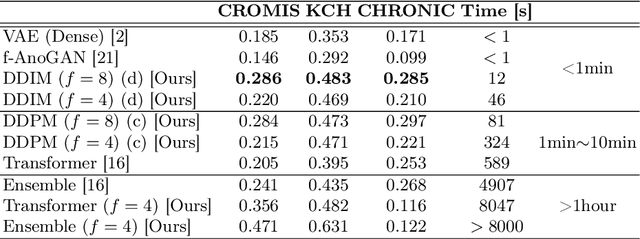
Deep generative models have emerged as promising tools for detecting arbitrary anomalies in data, dispensing with the necessity for manual labelling. Recently, autoregressive transformers have achieved state-of-the-art performance for anomaly detection in medical imaging. Nonetheless, these models still have some intrinsic weaknesses, such as requiring images to be modelled as 1D sequences, the accumulation of errors during the sampling process, and the significant inference times associated with transformers. Denoising diffusion probabilistic models are a class of non-autoregressive generative models recently shown to produce excellent samples in computer vision (surpassing Generative Adversarial Networks), and to achieve log-likelihoods that are competitive with transformers while having fast inference times. Diffusion models can be applied to the latent representations learnt by autoencoders, making them easily scalable and great candidates for application to high dimensional data, such as medical images. Here, we propose a method based on diffusion models to detect and segment anomalies in brain imaging. By training the models on healthy data and then exploring its diffusion and reverse steps across its Markov chain, we can identify anomalous areas in the latent space and hence identify anomalies in the pixel space. Our diffusion models achieve competitive performance compared with autoregressive approaches across a series of experiments with 2D CT and MRI data involving synthetic and real pathological lesions with much reduced inference times, making their usage clinically viable.
Equitable modelling of brain imaging by counterfactual augmentation with morphologically constrained 3D deep generative models
Nov 29, 2021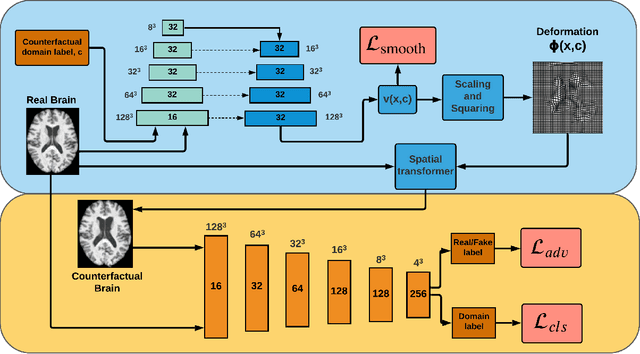

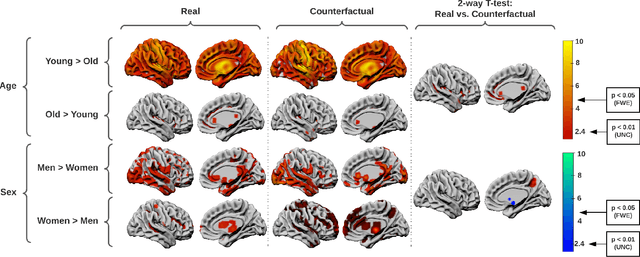
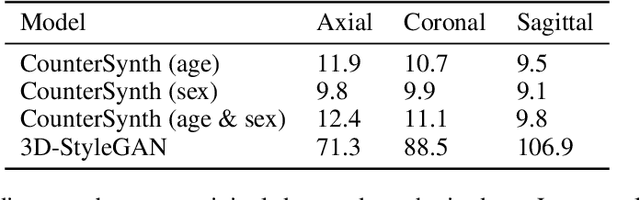
We describe Countersynth, a conditional generative model of diffeomorphic deformations that induce label-driven, biologically plausible changes in volumetric brain images. The model is intended to synthesise counterfactual training data augmentations for downstream discriminative modelling tasks where fidelity is limited by data imbalance, distributional instability, confounding, or underspecification, and exhibits inequitable performance across distinct subpopulations. Focusing on demographic attributes, we evaluate the quality of synthesized counterfactuals with voxel-based morphometry, classification and regression of the conditioning attributes, and the Fr\'{e}chet inception distance. Examining downstream discriminative performance in the context of engineered demographic imbalance and confounding, we use UK Biobank magnetic resonance imaging data to benchmark CounterSynth augmentation against current solutions to these problems. We achieve state-of-the-art improvements, both in overall fidelity and equity. The source code for CounterSynth is available online.
Hierarchical Graph-Convolutional Variational AutoEncoding for Generative Modelling of Human Motion
Nov 29, 2021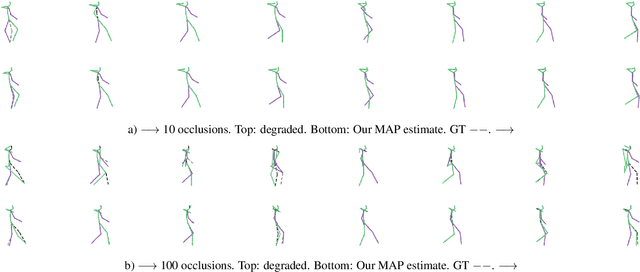
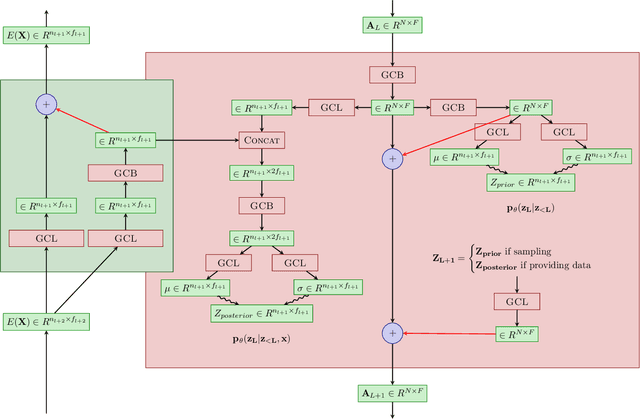
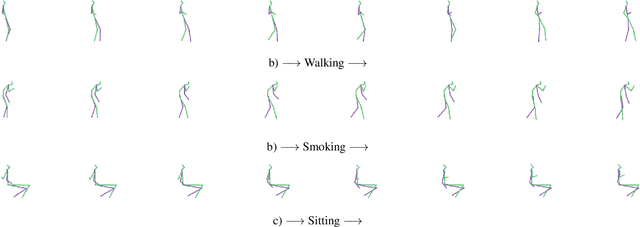
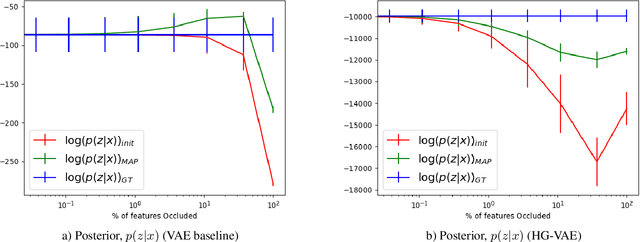
Models of human motion commonly focus either on trajectory prediction or action classification but rarely both. The marked heterogeneity and intricate compositionality of human motion render each task vulnerable to the data degradation and distributional shift common to real-world scenarios. A sufficiently expressive generative model of action could in theory enable data conditioning and distributional resilience within a unified framework applicable to both tasks. Here we propose a novel architecture based on hierarchical variational autoencoders and deep graph convolutional neural networks for generating a holistic model of action over multiple time-scales. We show this Hierarchical Graph-convolutional Variational Autoencoder (HG-VAE) to be capable of generating coherent actions, detecting out-of-distribution data, and imputing missing data by gradient ascent on the model's posterior. Trained and evaluated on H3.6M and the largest collection of open source human motion data, AMASS, we show HG-VAE can facilitate downstream discriminative learning better than baseline models.
An artificial intelligence natural language processing pipeline for information extraction in neuroradiology
Jul 21, 2021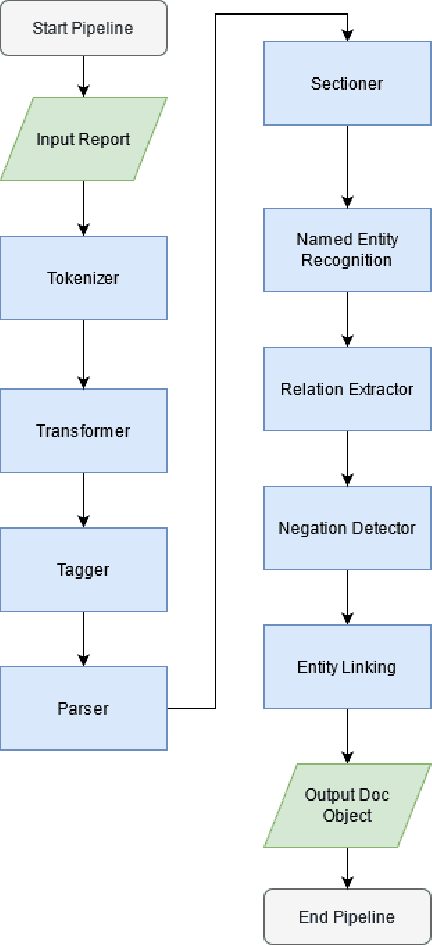



The use of electronic health records in medical research is difficult because of the unstructured format. Extracting information within reports and summarising patient presentations in a way amenable to downstream analysis would be enormously beneficial for operational and clinical research. In this work we present a natural language processing pipeline for information extraction of radiological reports in neurology. Our pipeline uses a hybrid sequence of rule-based and artificial intelligence models to accurately extract and summarise neurological reports. We train and evaluate a custom language model on a corpus of 150000 radiological reports from National Hospital for Neurology and Neurosurgery, London MRI imaging. We also present results for standard NLP tasks on domain-specific neuroradiology datasets. We show our pipeline, called `neuroNLP', can reliably extract clinically relevant information from these reports, enabling downstream modelling of reports and associated imaging on a heretofore unprecedented scale.
Unsupervised Brain Anomaly Detection and Segmentation with Transformers
Feb 23, 2021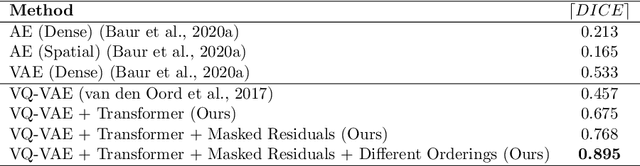
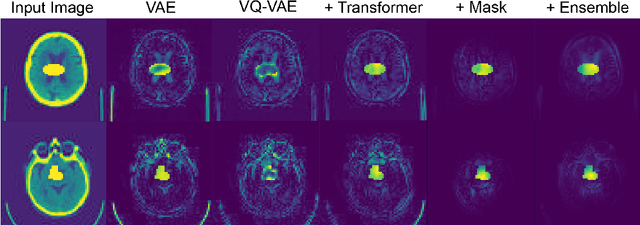
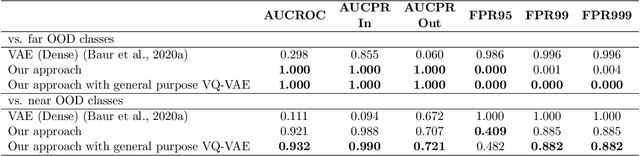
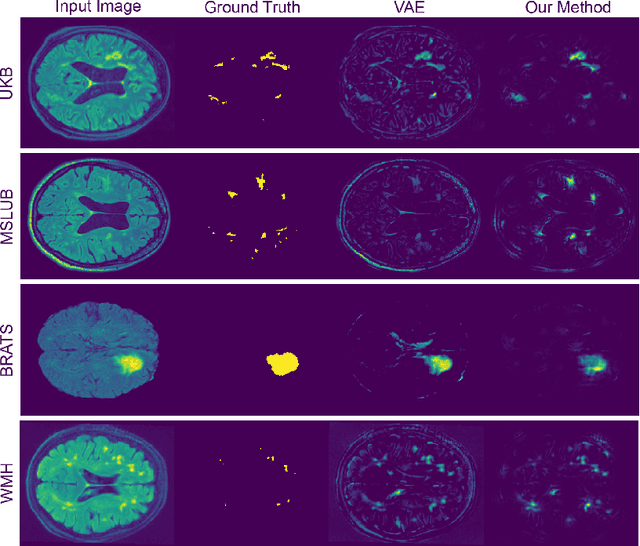
Pathological brain appearances may be so heterogeneous as to be intelligible only as anomalies, defined by their deviation from normality rather than any specific pathological characteristic. Amongst the hardest tasks in medical imaging, detecting such anomalies requires models of the normal brain that combine compactness with the expressivity of the complex, long-range interactions that characterise its structural organisation. These are requirements transformers have arguably greater potential to satisfy than other current candidate architectures, but their application has been inhibited by their demands on data and computational resource. Here we combine the latent representation of vector quantised variational autoencoders with an ensemble of autoregressive transformers to enable unsupervised anomaly detection and segmentation defined by deviation from healthy brain imaging data, achievable at low computational cost, within relative modest data regimes. We compare our method to current state-of-the-art approaches across a series of experiments involving synthetic and real pathological lesions. On real lesions, we train our models on 15,000 radiologically normal participants from UK Biobank, and evaluate performance on four different brain MR datasets with small vessel disease, demyelinating lesions, and tumours. We demonstrate superior anomaly detection performance both image-wise and pixel-wise, achievable without post-processing. These results draw attention to the potential of transformers in this most challenging of imaging tasks.