 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA 3D generative model of pathological multi-modal MR images and segmentations
Nov 08, 2023Generative modelling and synthetic data can be a surrogate for real medical imaging datasets, whose scarcity and difficulty to share can be a nuisance when delivering accurate deep learning models for healthcare applications. In recent years, there has been an increased interest in using these models for data augmentation and synthetic data sharing, using architectures such as generative adversarial networks (GANs) or diffusion models (DMs). Nonetheless, the application of synthetic data to tasks such as 3D magnetic resonance imaging (MRI) segmentation remains limited due to the lack of labels associated with the generated images. Moreover, many of the proposed generative MRI models lack the ability to generate arbitrary modalities due to the absence of explicit contrast conditioning. These limitations prevent the user from adjusting the contrast and content of the images and obtaining more generalisable data for training task-specific models. In this work, we propose brainSPADE3D, a 3D generative model for brain MRI and associated segmentations, where the user can condition on specific pathological phenotypes and contrasts. The proposed joint imaging-segmentation generative model is shown to generate high-fidelity synthetic images and associated segmentations, with the ability to combine pathologies. We demonstrate how the model can alleviate issues with segmentation model performance when unexpected pathologies are present in the data.
Generative AI for Medical Imaging: extending the MONAI Framework
Jul 27, 2023Recent advances in generative AI have brought incredible breakthroughs in several areas, including medical imaging. These generative models have tremendous potential not only to help safely share medical data via synthetic datasets but also to perform an array of diverse applications, such as anomaly detection, image-to-image translation, denoising, and MRI reconstruction. However, due to the complexity of these models, their implementation and reproducibility can be difficult. This complexity can hinder progress, act as a use barrier, and dissuade the comparison of new methods with existing works. In this study, we present MONAI Generative Models, a freely available open-source platform that allows researchers and developers to easily train, evaluate, and deploy generative models and related applications. Our platform reproduces state-of-art studies in a standardised way involving different architectures (such as diffusion models, autoregressive transformers, and GANs), and provides pre-trained models for the community. We have implemented these models in a generalisable fashion, illustrating that their results can be extended to 2D or 3D scenarios, including medical images with different modalities (like CT, MRI, and X-Ray data) and from different anatomical areas. Finally, we adopt a modular and extensible approach, ensuring long-term maintainability and the extension of current applications for future features.
Unsupervised 3D out-of-distribution detection with latent diffusion models
Jul 07, 2023


Methods for out-of-distribution (OOD) detection that scale to 3D data are crucial components of any real-world clinical deep learning system. Classic denoising diffusion probabilistic models (DDPMs) have been recently proposed as a robust way to perform reconstruction-based OOD detection on 2D datasets, but do not trivially scale to 3D data. In this work, we propose to use Latent Diffusion Models (LDMs), which enable the scaling of DDPMs to high-resolution 3D medical data. We validate the proposed approach on near- and far-OOD datasets and compare it to a recently proposed, 3D-enabled approach using Latent Transformer Models (LTMs). Not only does the proposed LDM-based approach achieve statistically significant better performance, it also shows less sensitivity to the underlying latent representation, more favourable memory scaling, and produces better spatial anomaly maps. Code is available at https://github.com/marksgraham/ddpm-ood
Denoising Diffusion Models for Out-of-Distribution Detection
Nov 30, 2022Out-of-distribution detection is crucial to the safe deployment of machine learning systems. Currently, the state-of-the-art in unsupervised out-of-distribution detection is dominated by generative-based approaches that make use of estimates of the likelihood or other measurements from a generative model. Reconstruction-based methods offer an alternative approach, in which a measure of reconstruction error is used to determine if a sample is out-of-distribution. However, reconstruction-based approaches are less favoured, as they require careful tuning of the model's information bottleneck - such as the size of the latent dimension - to produce good results. In this work, we exploit the view of denoising diffusion probabilistic models (DDPM) as denoising autoencoders where the bottleneck is controlled externally, by means of the amount of noise applied. We propose to use DDPMs to reconstruct an input that has been noised to a range of noise levels, and use the resulting multi-dimensional reconstruction error to classify out-of-distribution inputs. Our approach outperforms not only reconstruction-based methods, but also state-of-the-art generative-based approaches.
Morphology-preserving Autoregressive 3D Generative Modelling of the Brain
Sep 07, 2022
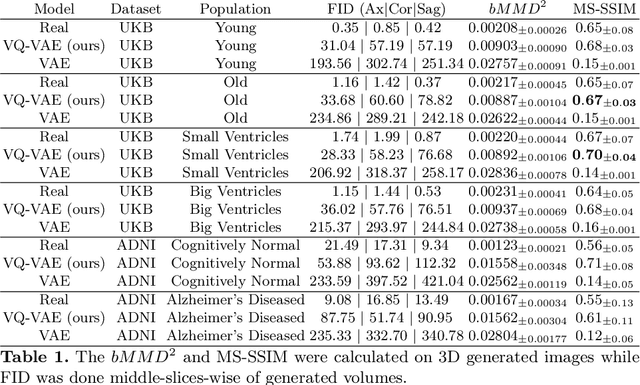
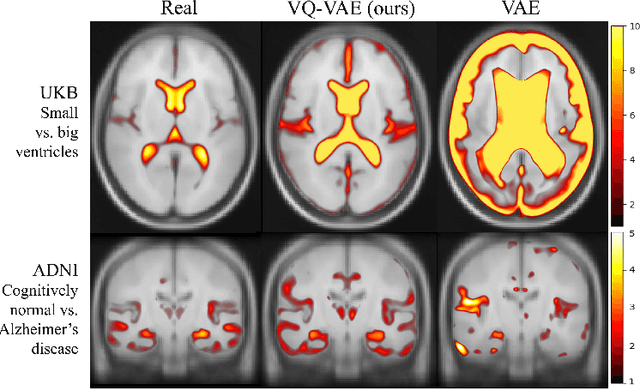
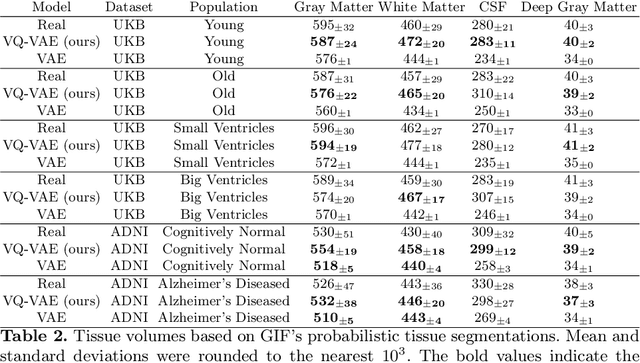
Human anatomy, morphology, and associated diseases can be studied using medical imaging data. However, access to medical imaging data is restricted by governance and privacy concerns, data ownership, and the cost of acquisition, thus limiting our ability to understand the human body. A possible solution to this issue is the creation of a model able to learn and then generate synthetic images of the human body conditioned on specific characteristics of relevance (e.g., age, sex, and disease status). Deep generative models, in the form of neural networks, have been recently used to create synthetic 2D images of natural scenes. Still, the ability to produce high-resolution 3D volumetric imaging data with correct anatomical morphology has been hampered by data scarcity and algorithmic and computational limitations. This work proposes a generative model that can be scaled to produce anatomically correct, high-resolution, and realistic images of the human brain, with the necessary quality to allow further downstream analyses. The ability to generate a potentially unlimited amount of data not only enables large-scale studies of human anatomy and pathology without jeopardizing patient privacy, but also significantly advances research in the field of anomaly detection, modality synthesis, learning under limited data, and fair and ethical AI. Code and trained models are available at: https://github.com/AmigoLab/SynthAnatomy.
Fast Unsupervised Brain Anomaly Detection and Segmentation with Diffusion Models
Jun 07, 2022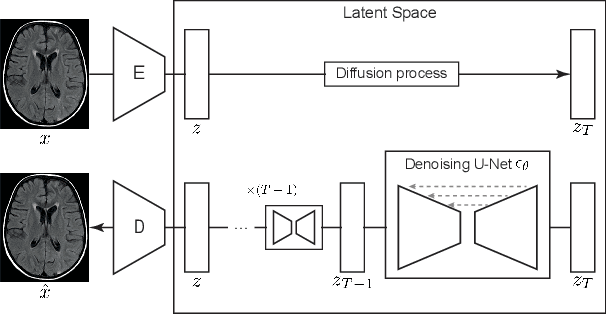
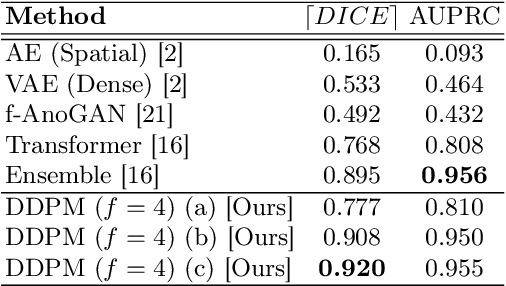
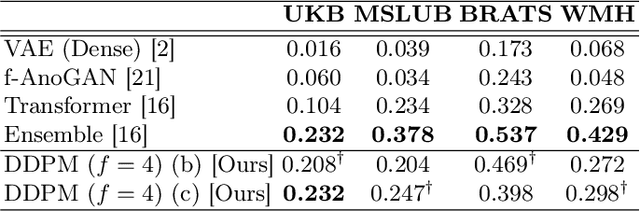
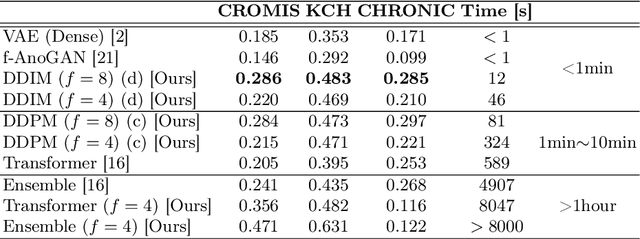
Deep generative models have emerged as promising tools for detecting arbitrary anomalies in data, dispensing with the necessity for manual labelling. Recently, autoregressive transformers have achieved state-of-the-art performance for anomaly detection in medical imaging. Nonetheless, these models still have some intrinsic weaknesses, such as requiring images to be modelled as 1D sequences, the accumulation of errors during the sampling process, and the significant inference times associated with transformers. Denoising diffusion probabilistic models are a class of non-autoregressive generative models recently shown to produce excellent samples in computer vision (surpassing Generative Adversarial Networks), and to achieve log-likelihoods that are competitive with transformers while having fast inference times. Diffusion models can be applied to the latent representations learnt by autoencoders, making them easily scalable and great candidates for application to high dimensional data, such as medical images. Here, we propose a method based on diffusion models to detect and segment anomalies in brain imaging. By training the models on healthy data and then exploring its diffusion and reverse steps across its Markov chain, we can identify anomalous areas in the latent space and hence identify anomalies in the pixel space. Our diffusion models achieve competitive performance compared with autoregressive approaches across a series of experiments with 2D CT and MRI data involving synthetic and real pathological lesions with much reduced inference times, making their usage clinically viable.
Test-time Unsupervised Domain Adaptation
Oct 05, 2020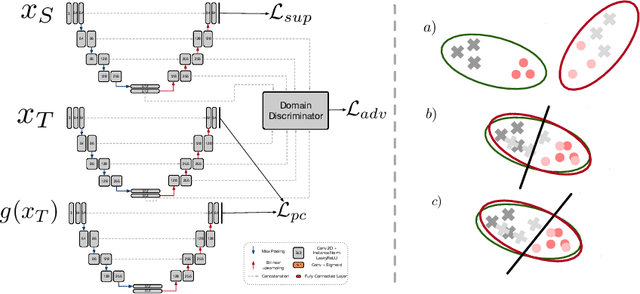
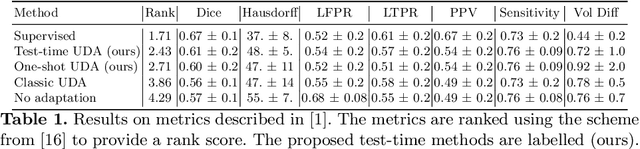
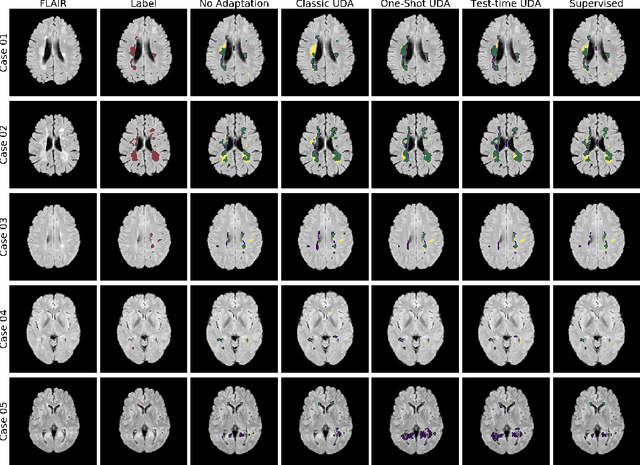
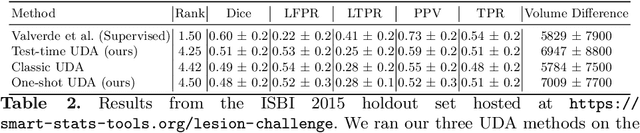
Convolutional neural networks trained on publicly available medical imaging datasets (source domain) rarely generalise to different scanners or acquisition protocols (target domain). This motivates the active field of domain adaptation. While some approaches to the problem require labeled data from the target domain, others adopt an unsupervised approach to domain adaptation (UDA). Evaluating UDA methods consists of measuring the model's ability to generalise to unseen data in the target domain. In this work, we argue that this is not as useful as adapting to the test set directly. We therefore propose an evaluation framework where we perform test-time UDA on each subject separately. We show that models adapted to a specific target subject from the target domain outperform a domain adaptation method which has seen more data of the target domain but not this specific target subject. This result supports the thesis that unsupervised domain adaptation should be used at test-time, even if only using a single target-domain subject
Hierarchical brain parcellation with uncertainty
Sep 16, 2020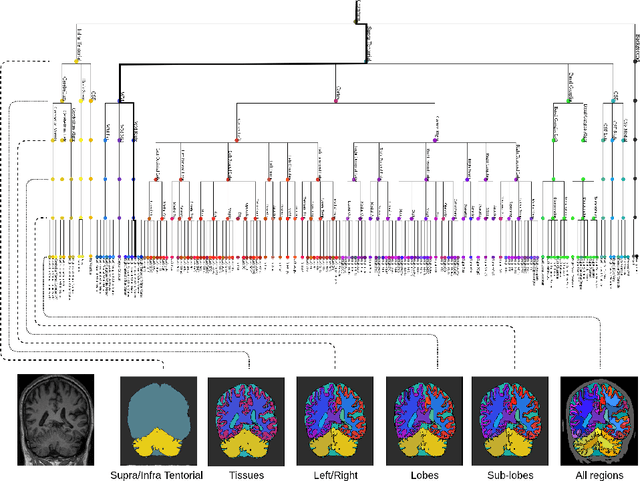
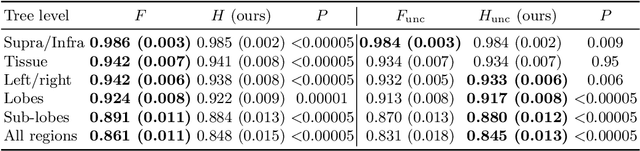
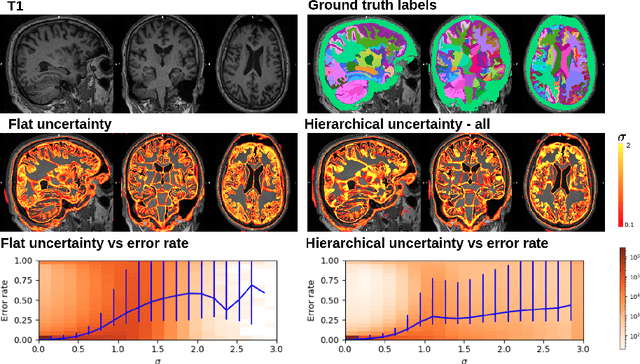
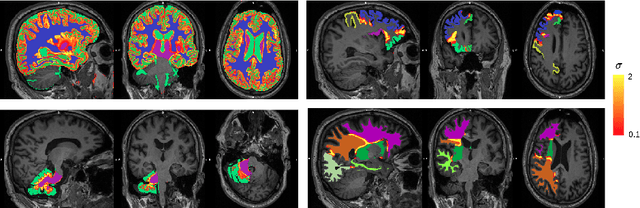
Many atlases used for brain parcellation are hierarchically organised, progressively dividing the brain into smaller sub-regions. However, state-of-the-art parcellation methods tend to ignore this structure and treat labels as if they are `flat'. We introduce a hierarchically-aware brain parcellation method that works by predicting the decisions at each branch in the label tree. We further show how this method can be used to model uncertainty separately for every branch in this label tree. Our method exceeds the performance of flat uncertainty methods, whilst also providing decomposed uncertainty estimates that enable us to obtain self-consistent parcellations and uncertainty maps at any level of the label hierarchy. We demonstrate a simple way these decision-specific uncertainty maps may be used to provided uncertainty-thresholded tissue maps at any level of the label tree.
Disease classification of macular Optical Coherence Tomography scans using deep learning software: validation on independent, multi-centre data
Jul 11, 2019



Purpose: To evaluate Pegasus-OCT, a clinical decision support software for the identification of features of retinal disease from macula OCT scans, across heterogenous populations involving varying patient demographics, device manufacturers, acquisition sites and operators. Methods: 5,588 normal and anomalous macular OCT volumes (162,721 B-scans), acquired at independent centres in five countries, were processed using the software. Results were evaluated against ground truth provided by the dataset owners. Results: Pegasus-OCT performed with AUROCs of at least 98% for all datasets in the detection of general macular anomalies. For scans of sufficient quality, the AUROCs for general AMD and DME detection were found to be at least 99% and 98%, respectively. Conclusions: The ability of a clinical decision support system to cater for different populations is key to its adoption. Pegasus-OCT was shown to be able to detect AMD, DME and general anomalies in OCT volumes acquired across multiple independent sites with high performance. Its use thus offers substantial promise, with the potential to alleviate the burden of growing demand in eye care services caused by retinal disease.