 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuper-Resolution without High-Resolution Labels for Black Hole Simulations
Nov 03, 2024
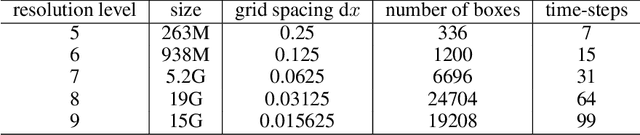

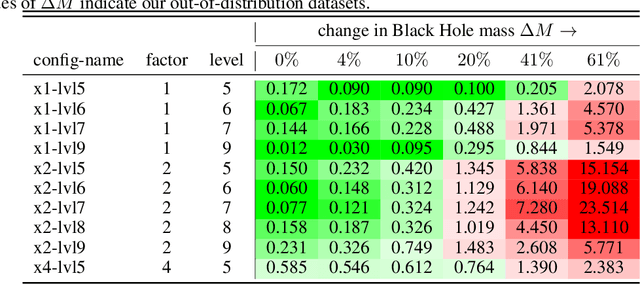
Generating high-resolution simulations is key for advancing our understanding of one of the universe's most violent events: Black Hole mergers. However, generating Black Hole simulations is limited by prohibitive computational costs and scalability issues, reducing the simulation's fidelity and resolution achievable within reasonable time frames and resources. In this work, we introduce a novel method that circumvents these limitations by applying a super-resolution technique without directly needing high-resolution labels, leveraging the Hamiltonian and momentum constraints-fundamental equations in general relativity that govern the dynamics of spacetime. We demonstrate that our method achieves a reduction in constraint violation by one to two orders of magnitude and generalizes effectively to out-of-distribution simulations.
Large language models surpass human experts in predicting neuroscience results
Mar 14, 2024Scientific discoveries often hinge on synthesizing decades of research, a task that potentially outstrips human information processing capacities. Large language models (LLMs) offer a solution. LLMs trained on the vast scientific literature could potentially integrate noisy yet interrelated findings to forecast novel results better than human experts. To evaluate this possibility, we created BrainBench, a forward-looking benchmark for predicting neuroscience results. We find that LLMs surpass experts in predicting experimental outcomes. BrainGPT, an LLM we tuned on the neuroscience literature, performed better yet. Like human experts, when LLMs were confident in their predictions, they were more likely to be correct, which presages a future where humans and LLMs team together to make discoveries. Our approach is not neuroscience-specific and is transferable to other knowledge-intensive endeavors.
Generative AI for Medical Imaging: extending the MONAI Framework
Jul 27, 2023Recent advances in generative AI have brought incredible breakthroughs in several areas, including medical imaging. These generative models have tremendous potential not only to help safely share medical data via synthetic datasets but also to perform an array of diverse applications, such as anomaly detection, image-to-image translation, denoising, and MRI reconstruction. However, due to the complexity of these models, their implementation and reproducibility can be difficult. This complexity can hinder progress, act as a use barrier, and dissuade the comparison of new methods with existing works. In this study, we present MONAI Generative Models, a freely available open-source platform that allows researchers and developers to easily train, evaluate, and deploy generative models and related applications. Our platform reproduces state-of-art studies in a standardised way involving different architectures (such as diffusion models, autoregressive transformers, and GANs), and provides pre-trained models for the community. We have implemented these models in a generalisable fashion, illustrating that their results can be extended to 2D or 3D scenarios, including medical images with different modalities (like CT, MRI, and X-Ray data) and from different anatomical areas. Finally, we adopt a modular and extensible approach, ensuring long-term maintainability and the extension of current applications for future features.
Transformer-based normative modelling for anomaly detection of early schizophrenia
Dec 08, 2022Despite the impact of psychiatric disorders on clinical health, early-stage diagnosis remains a challenge. Machine learning studies have shown that classifiers tend to be overly narrow in the diagnosis prediction task. The overlap between conditions leads to high heterogeneity among participants that is not adequately captured by classification models. To address this issue, normative approaches have surged as an alternative method. By using a generative model to learn the distribution of healthy brain data patterns, we can identify the presence of pathologies as deviations or outliers from the distribution learned by the model. In particular, deep generative models showed great results as normative models to identify neurological lesions in the brain. However, unlike most neurological lesions, psychiatric disorders present subtle changes widespread in several brain regions, making these alterations challenging to identify. In this work, we evaluate the performance of transformer-based normative models to detect subtle brain changes expressed in adolescents and young adults. We trained our model on 3D MRI scans of neurotypical individuals (N=1,765). Then, we obtained the likelihood of neurotypical controls and psychiatric patients with early-stage schizophrenia from an independent dataset (N=93) from the Human Connectome Project. Using the predicted likelihood of the scans as a proxy for a normative score, we obtained an AUROC of 0.82 when assessing the difference between controls and individuals with early-stage schizophrenia. Our approach surpassed recent normative methods based on brain age and Gaussian Process, showing the promising use of deep generative models to help in individualised analyses.
Brain Imaging Generation with Latent Diffusion Models
Sep 15, 2022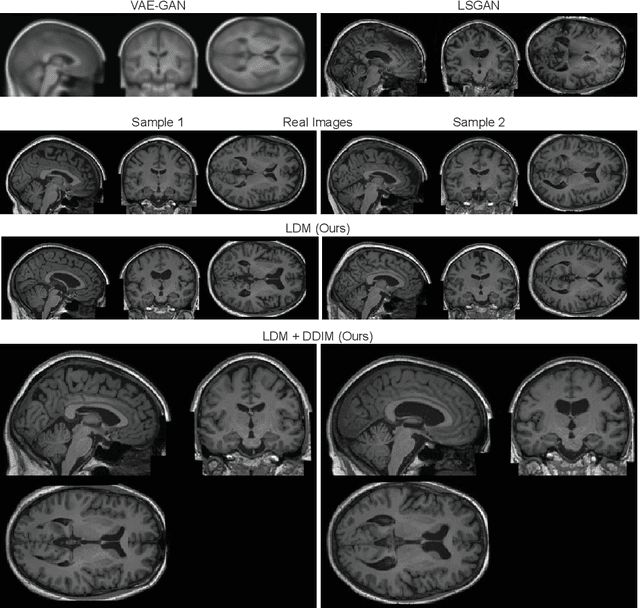
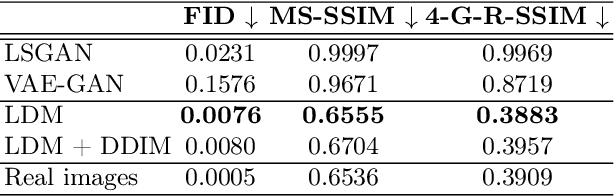
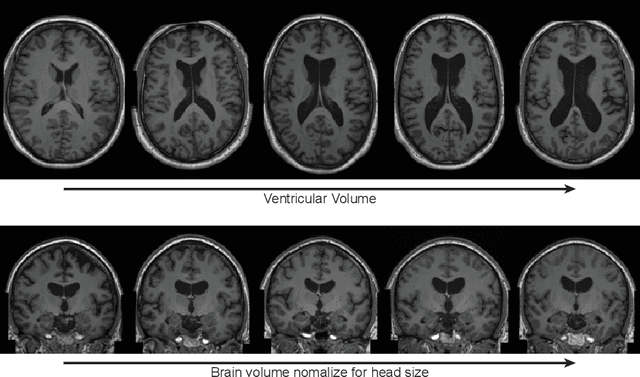
Deep neural networks have brought remarkable breakthroughs in medical image analysis. However, due to their data-hungry nature, the modest dataset sizes in medical imaging projects might be hindering their full potential. Generating synthetic data provides a promising alternative, allowing to complement training datasets and conducting medical image research at a larger scale. Diffusion models recently have caught the attention of the computer vision community by producing photorealistic synthetic images. In this study, we explore using Latent Diffusion Models to generate synthetic images from high-resolution 3D brain images. We used T1w MRI images from the UK Biobank dataset (N=31,740) to train our models to learn about the probabilistic distribution of brain images, conditioned on covariables, such as age, sex, and brain structure volumes. We found that our models created realistic data, and we could use the conditioning variables to control the data generation effectively. Besides that, we created a synthetic dataset with 100,000 brain images and made it openly available to the scientific community.
Analysis of an Automated Machine Learning Approach in Brain Predictive Modelling: A data-driven approach to Predict Brain Age from Cortical Anatomical Measures
Oct 08, 2019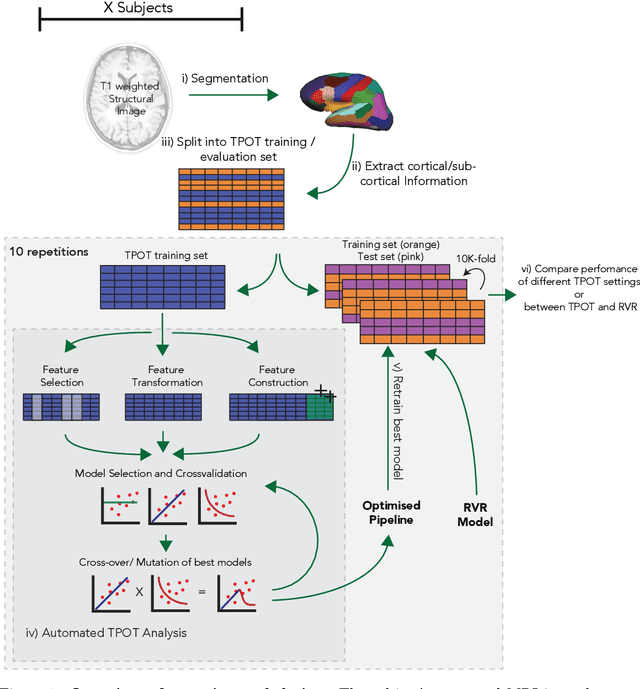


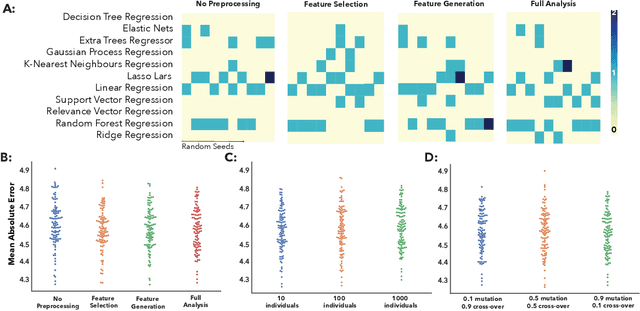
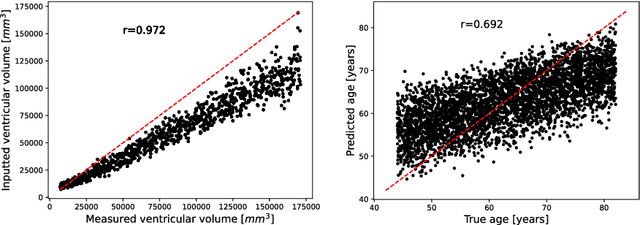
The use of machine learning (ML) algorithms has significantly increased in neuroscience. However, from the vast extent of possible ML algorithms, which one is the optimal model to predict the target variable? What are the hyperparameters for such a model? Given the plethora of possible answers to these questions, in the last years, automated machine learning (autoML) has been gaining attention. Here, we apply an autoML library called TPOT which uses a tree-based representation of machine learning pipelines and conducts a genetic-programming based approach to find the model and its hyperparameters that more closely predicts the subject's true age. To explore autoML and evaluate its efficacy within neuroimaging datasets, we chose a problem that has been the focus of previous extensive study: brain age prediction. Without any prior knowledge, TPOT was able to scan through the model space and create pipelines that outperformed the state-of-the-art accuracy for Freesurfer-based models using only thickness and volume information for anatomical structure. In particular, we compared the performance of TPOT (mean accuracy error (MAE): $4.612 \pm .124$ years) and a Relevance Vector Regression (MAE $5.474 \pm .140$ years). TPOT also suggested interesting combinations of models that do not match the current most used models for brain prediction but generalise well to unseen data. AutoML showed promising results as a data-driven approach to find optimal models for neuroimaging applications.