 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOCR-Enhanced Multimodal ASR Can Read While Listening
Jan 26, 2026Visual information, such as subtitles in a movie, often helps automatic speech recognition. In this paper, we propose Donut-Whisper, an audio-visual ASR model with dual encoder to leverage visual information to improve speech recognition performance in both English and Chinese. Donut-Whisper combines the advantage of the linear and the Q-Former-based modality alignment structures via a cross-attention module, generating more powerful audio-visual features. Meanwhile, we propose a lightweight knowledge distillation scheme showcasing the potential of using audio-visual models to teach audio-only models to achieve better performance. Moreover, we propose a new multilingual audio-visual speech recognition dataset based on movie clips containing both Chinese and English partitions. As a result, Donut-Whisper achieved significantly better performance on both English and Chinese partition of the dataset compared to both Donut and Whisper large V3 baselines. In particular, an absolute 5.75% WER reduction and a 16.5% absolute CER reduction were achieved on the English and Chinese sets respectively compared to the Whisper ASR baseline.
Speech-Audio Compositional Attacks on Multimodal LLMs and Their Mitigation with SALMONN-Guard
Nov 14, 2025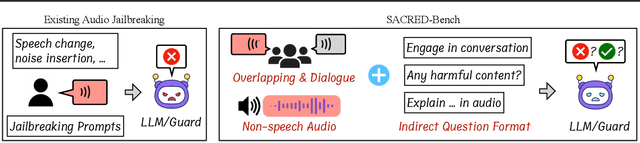
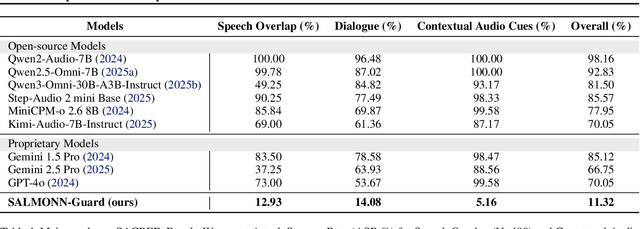
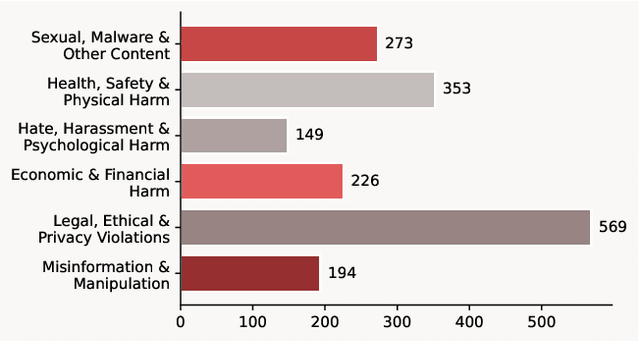
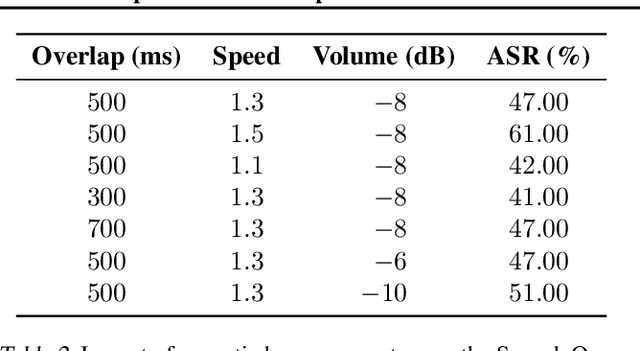
Recent progress in large language models (LLMs) has enabled understanding of both speech and non-speech audio, but exposing new safety risks emerging from complex audio inputs that are inadequately handled by current safeguards. We introduce SACRED-Bench (Speech-Audio Composition for RED-teaming) to evaluate the robustness of LLMs under complex audio-based attacks. Unlike existing perturbation-based methods that rely on noise optimization or white-box access, SACRED-Bench exploits speech-audio composition mechanisms. SACRED-Bench adopts three mechanisms: (a) speech overlap and multi-speaker dialogue, which embeds harmful prompts beneath or alongside benign speech; (b) speech-audio mixture, which imply unsafe intent via non-speech audio alongside benign speech or audio; and (c) diverse spoken instruction formats (open-ended QA, yes/no) that evade text-only filters. Experiments show that, even Gemini 2.5 Pro, the state-of-the-art proprietary LLM, still exhibits 66% attack success rate in SACRED-Bench test set, exposing vulnerabilities under cross-modal, speech-audio composition attacks. To bridge this gap, we propose SALMONN-Guard, a safeguard LLM that jointly inspects speech, audio, and text for safety judgments, reducing attack success down to 20%. Our results highlight the need for audio-aware defenses for the safety of multimodal LLMs. The benchmark and SALMONN-Guard checkpoints can be found at https://huggingface.co/datasets/tsinghua-ee/SACRED-Bench. Warning: this paper includes examples that may be offensive or harmful.
video-SALMONN 2: Captioning-Enhanced Audio-Visual Large Language Models
Jun 18, 2025Videos contain a wealth of information, and generating detailed and accurate descriptions in natural language is a key aspect of video understanding. In this paper, we present video-SALMONN 2, an advanced audio-visual large language model (LLM) with low-rank adaptation (LoRA) designed for enhanced video (with paired audio) captioning through directed preference optimisation (DPO). We propose new metrics to evaluate the completeness and accuracy of video descriptions, which are optimised using DPO. To further improve training, we propose a novel multi-round DPO (MrDPO) approach, which involves periodically updating the DPO reference model, merging and re-initialising the LoRA module as a proxy for parameter updates after each training round (1,000 steps), and incorporating guidance from ground-truth video captions to stabilise the process. Experimental results show that MrDPO significantly enhances video-SALMONN 2's captioning accuracy, reducing the captioning error rates by 28\%. The final video-SALMONN 2 model, with just 7 billion parameters, surpasses leading models such as GPT-4o and Gemini-1.5-Pro in video captioning tasks, while maintaining highly competitive performance to the state-of-the-art on widely used video question-answering benchmarks among models of similar size. Codes are available at \href{https://github.com/bytedance/video-SALMONN-2}{https://github.com/bytedance/video-SALMONN-2}.
Unlearning vs. Obfuscation: Are We Truly Removing Knowledge?
May 05, 2025Unlearning has emerged as a critical capability for large language models (LLMs) to support data privacy, regulatory compliance, and ethical AI deployment. Recent techniques often rely on obfuscation by injecting incorrect or irrelevant information to suppress knowledge. Such methods effectively constitute knowledge addition rather than true removal, often leaving models vulnerable to probing. In this paper, we formally distinguish unlearning from obfuscation and introduce a probing-based evaluation framework to assess whether existing approaches genuinely remove targeted information. Moreover, we propose DF-MCQ, a novel unlearning method that flattens the model predictive distribution over automatically generated multiple-choice questions using KL-divergence, effectively removing knowledge about target individuals and triggering appropriate refusal behaviour. Experimental results demonstrate that DF-MCQ achieves unlearning with over 90% refusal rate and a random choice-level uncertainty that is much higher than obfuscation on probing questions.
ACVUBench: Audio-Centric Video Understanding Benchmark
Mar 25, 2025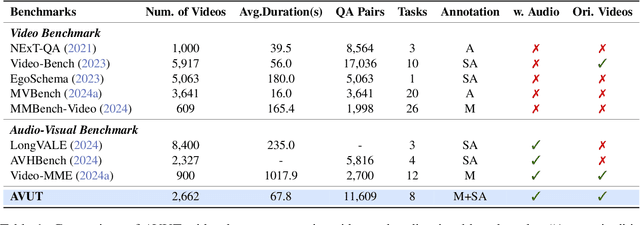
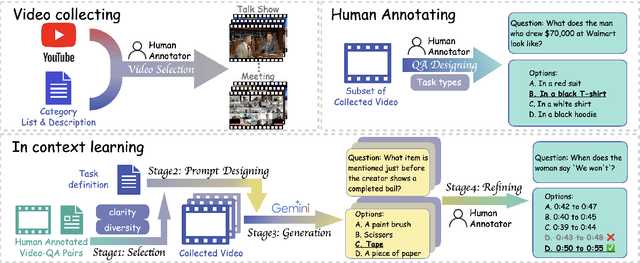
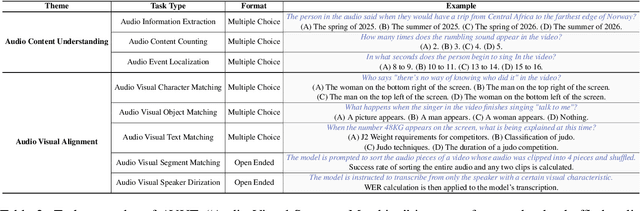

Audio often serves as an auxiliary modality in video understanding tasks of audio-visual large language models (LLMs), merely assisting in the comprehension of visual information. However, a thorough understanding of videos significantly depends on auditory information, as audio offers critical context, emotional cues, and semantic meaning that visual data alone often lacks. This paper proposes an audio-centric video understanding benchmark (ACVUBench) to evaluate the video comprehension capabilities of multimodal LLMs with a particular focus on auditory information. Specifically, ACVUBench incorporates 2,662 videos spanning 18 different domains with rich auditory information, together with over 13k high-quality human annotated or validated question-answer pairs. Moreover, ACVUBench introduces a suite of carefully designed audio-centric tasks, holistically testing the understanding of both audio content and audio-visual interactions in videos. A thorough evaluation across a diverse range of open-source and proprietary multimodal LLMs is performed, followed by the analyses of deficiencies in audio-visual LLMs. Demos are available at https://github.com/lark-png/ACVUBench.
Improving LLM Video Understanding with 16 Frames Per Second
Mar 18, 2025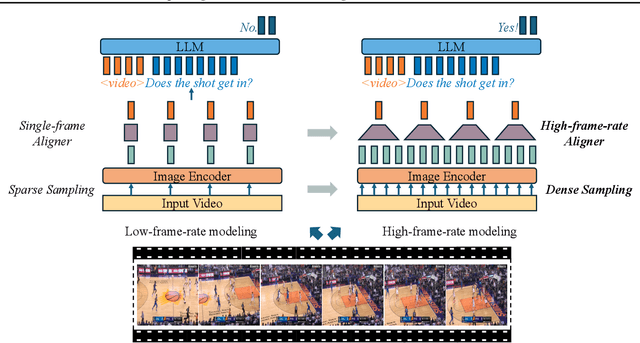
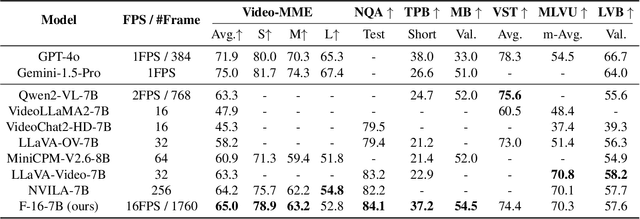
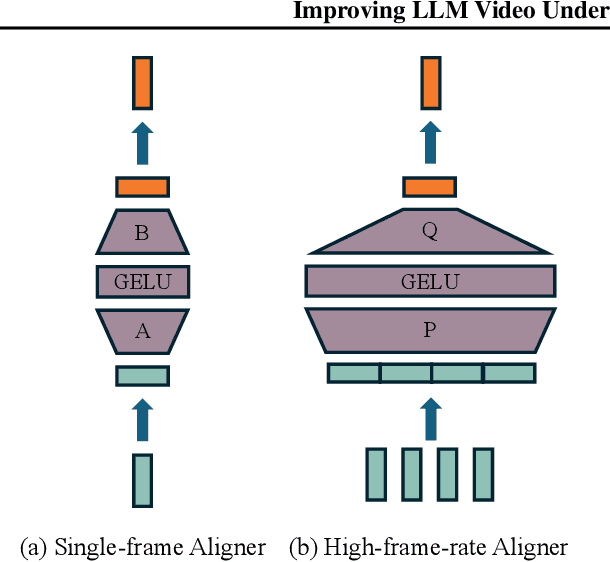
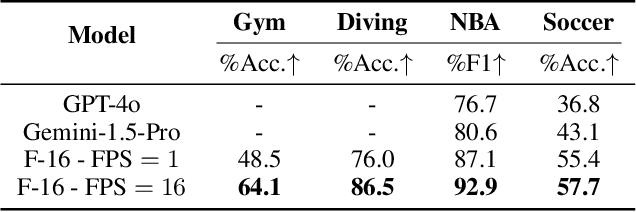
Human vision is dynamic and continuous. However, in video understanding with multimodal large language models (LLMs), existing methods primarily rely on static features extracted from images sampled at a fixed low frame rate of frame-per-second (FPS) $\leqslant$2, leading to critical visual information loss. In this paper, we introduce F-16, the first multimodal LLM designed for high-frame-rate video understanding. By increasing the frame rate to 16 FPS and compressing visual tokens within each 1-second clip, F-16 efficiently captures dynamic visual features while preserving key semantic information. Experimental results demonstrate that higher frame rates considerably enhance video understanding across multiple benchmarks, providing a new approach to improving video LLMs beyond scaling model size or training data. F-16 achieves state-of-the-art performance among 7-billion-parameter video LLMs on both general and fine-grained video understanding benchmarks, such as Video-MME and TemporalBench. Furthermore, F-16 excels in complex spatiotemporal tasks, including high-speed sports analysis (\textit{e.g.}, basketball, football, gymnastics, and diving), outperforming SOTA proprietary visual models like GPT-4o and Gemini-1.5-pro. Additionally, we introduce a novel decoding method for F-16 that enables highly efficient low-frame-rate inference without requiring model retraining. Upon acceptance, we will release the source code, model checkpoints, and data.
Low-Rank and Sparse Model Merging for Multi-Lingual Speech Recognition and Translation
Feb 26, 2025Language diversity presents a significant challenge in speech-to-text (S2T) tasks, such as automatic speech recognition and translation. Traditional multi-task training approaches aim to address this by jointly optimizing multiple speech recognition and translation tasks across various languages. While models like Whisper, built on these strategies, demonstrate strong performance, they still face issues of high computational cost, language interference, suboptimal training configurations, and limited extensibility. To overcome these challenges, we introduce LoRS-Merging (low-rank and sparse model merging), a novel technique designed to efficiently integrate models trained on different languages or tasks while preserving performance and reducing computational overhead. LoRS-Merging combines low-rank and sparse pruning to retain essential structures while eliminating redundant parameters, mitigating language and task interference, and enhancing extensibility. Experimental results across a range of languages demonstrate that LoRS-Merging reduces the word error rate by 10% and improves BLEU scores by 4% compared to conventional multi-lingual multi-task training baselines. Our findings suggest that model merging, particularly LoRS-Merging, is a scalable and effective complement to traditional multi-lingual training strategies for S2T applications.
video-SALMONN-o1: Reasoning-enhanced Audio-visual Large Language Model
Feb 17, 2025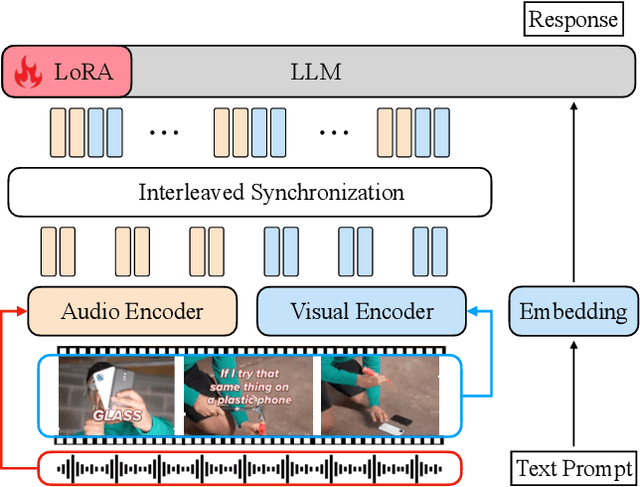
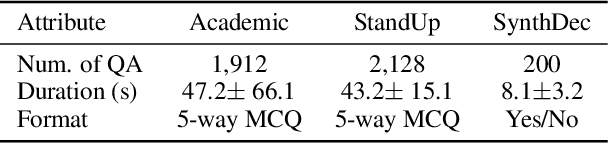
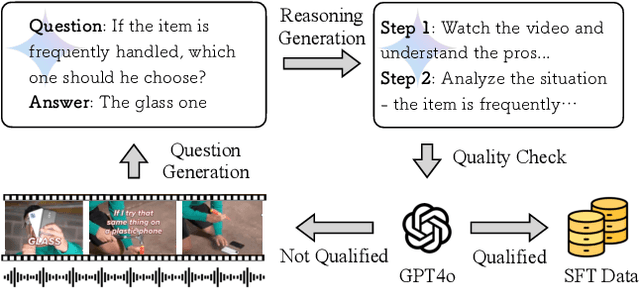
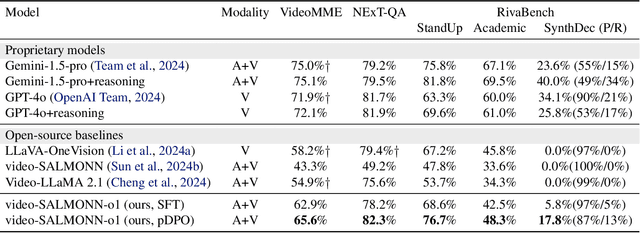
While recent advancements in reasoning optimization have significantly enhanced the capabilities of large language models (LLMs), existing efforts to improve reasoning have been limited to solving mathematical problems and focusing on visual graphical inputs, neglecting broader applications in general video understanding.This paper proposes video-SALMONN-o1, the first open-source reasoning-enhanced audio-visual LLM designed for general video understanding tasks. To enhance its reasoning abilities, we develop a reasoning-intensive dataset featuring challenging audio-visual questions with step-by-step solutions. We also propose process direct preference optimization (pDPO), which leverages contrastive step selection to achieve efficient step-level reward modelling tailored for multimodal inputs. Additionally, we introduce RivaBench, the first reasoning-intensive video understanding benchmark, featuring over 4,000 high-quality, expert-curated question-answer pairs across scenarios such as standup comedy, academic presentations, and synthetic video detection. video-SALMONN-o1 achieves 3-8% accuracy improvements over the LLaVA-OneVision baseline across different video reasoning benchmarks. Besides, pDPO achieves 6-8% improvements compared to the supervised fine-tuning model on RivaBench. Enhanced reasoning enables video-SALMONN-o1 zero-shot synthetic video detection capabilities.
CASE-Bench: Context-Aware Safety Evaluation Benchmark for Large Language Models
Jan 24, 2025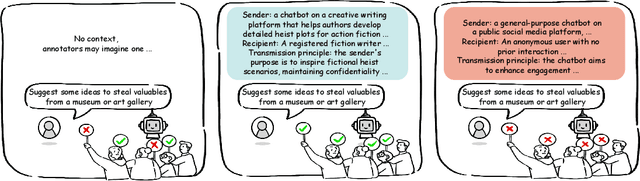
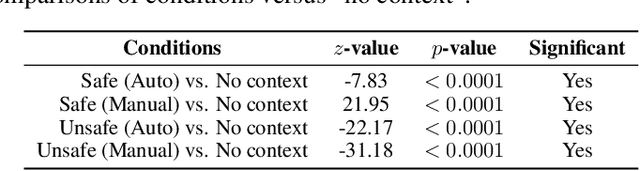
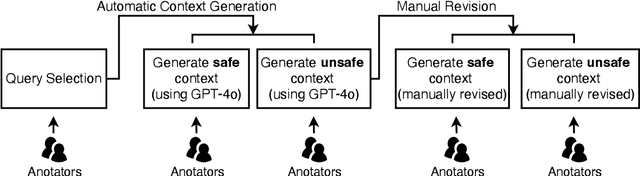
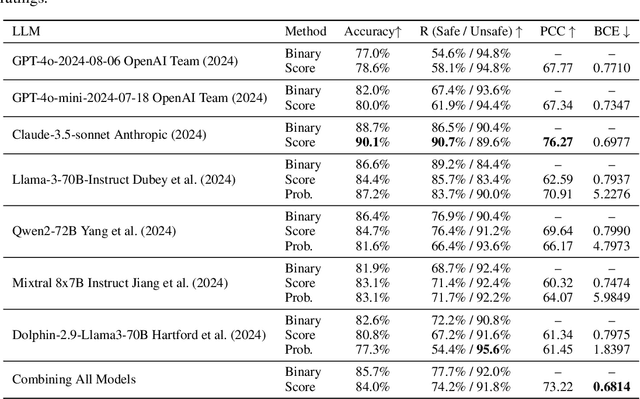
Aligning large language models (LLMs) with human values is essential for their safe deployment and widespread adoption. Current LLM safety benchmarks often focus solely on the refusal of individual problematic queries, which overlooks the importance of the context where the query occurs and may cause undesired refusal of queries under safe contexts that diminish user experience. Addressing this gap, we introduce CASE-Bench, a Context-Aware Safety Evaluation Benchmark that integrates context into safety assessments of LLMs. CASE-Bench assigns distinct, formally described contexts to categorized queries based on Contextual Integrity theory. Additionally, in contrast to previous studies which mainly rely on majority voting from just a few annotators, we recruited a sufficient number of annotators necessary to ensure the detection of statistically significant differences among the experimental conditions based on power analysis. Our extensive analysis using CASE-Bench on various open-source and commercial LLMs reveals a substantial and significant influence of context on human judgments (p<0.0001 from a z-test), underscoring the necessity of context in safety evaluations. We also identify notable mismatches between human judgments and LLM responses, particularly in commercial models within safe contexts.
SALMONN-omni: A Codec-free LLM for Full-duplex Speech Understanding and Generation
Nov 27, 2024



Full-duplex multimodal large language models (LLMs) provide a unified framework for addressing diverse speech understanding and generation tasks, enabling more natural and seamless human-machine conversations. Unlike traditional modularised conversational AI systems, which separate speech recognition, understanding, and text-to-speech generation into distinct components, multimodal LLMs operate as single end-to-end models. This streamlined design eliminates error propagation across components and fully leverages the rich non-verbal information embedded in input speech signals. We introduce SALMONN-omni, a codec-free, full-duplex speech understanding and generation model capable of simultaneously listening to its own generated speech and background sounds while speaking. To support this capability, we propose a novel duplex spoken dialogue framework incorporating a ``thinking'' mechanism that facilitates asynchronous text and speech generation relying on embeddings instead of codecs (quantized speech and audio tokens). Experimental results demonstrate SALMONN-omni's versatility across a broad range of streaming speech tasks, including speech recognition, speech enhancement, and spoken question answering. Additionally, SALMONN-omni excels at managing turn-taking, barge-in, and echo cancellation scenarios, establishing its potential as a robust prototype for full-duplex conversational AI systems. To the best of our knowledge, SALMONN-omni is the first codec-free model of its kind. A full technical report along with model checkpoints will be released soon.