 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Fine-Grained Audio-Visual Evidence for Robust Multimodal Emotion Reasoning
Jan 26, 2026Multimodal emotion analysis is shifting from static classification to generative reasoning. Beyond simple label prediction, robust affective reasoning must synthesize fine-grained signals such as facial micro-expressions and prosodic which shifts to decode the latent causality within complex social contexts. However, current Multimodal Large Language Models (MLLMs) face significant limitations in fine-grained perception, primarily due to data scarcity and insufficient cross-modal fusion. As a result, these models often exhibit unimodal dominance which leads to hallucinations in complex multimodal interactions, particularly when visual and acoustic cues are subtle, ambiguous, or even contradictory (e.g., in sarcastic scenery). To address this, we introduce SABER-LLM, a framework designed for robust multimodal reasoning. First, we construct SABER, a large-scale emotion reasoning dataset comprising 600K video clips, annotated with a novel six-dimensional schema that jointly captures audiovisual cues and causal logic. Second, we propose the structured evidence decomposition paradigm, which enforces a "perceive-then-reason" separation between evidence extraction and reasoning to alleviate unimodal dominance. The ability to perceive complex scenes is further reinforced by consistency-aware direct preference optimization, which explicitly encourages alignment among modalities under ambiguous or conflicting perceptual conditions. Experiments on EMER, EmoBench-M, and SABER-Test demonstrate that SABER-LLM significantly outperforms open-source baselines and achieves robustness competitive with closed-source models in decoding complex emotional dynamics. The dataset and model are available at https://github.com/zxzhao0/SABER-LLM.
QualiSpeech: A Speech Quality Assessment Dataset with Natural Language Reasoning and Descriptions
Mar 26, 2025



This paper explores a novel perspective to speech quality assessment by leveraging natural language descriptions, offering richer, more nuanced insights than traditional numerical scoring methods. Natural language feedback provides instructive recommendations and detailed evaluations, yet existing datasets lack the comprehensive annotations needed for this approach. To bridge this gap, we introduce QualiSpeech, a comprehensive low-level speech quality assessment dataset encompassing 11 key aspects and detailed natural language comments that include reasoning and contextual insights. Additionally, we propose the QualiSpeech Benchmark to evaluate the low-level speech understanding capabilities of auditory large language models (LLMs). Experimental results demonstrate that finetuned auditory LLMs can reliably generate detailed descriptions of noise and distortion, effectively identifying their types and temporal characteristics. The results further highlight the potential for incorporating reasoning to enhance the accuracy and reliability of quality assessments. The dataset will be released at https://huggingface.co/datasets/tsinghua-ee/QualiSpeech.
Solla: Towards a Speech-Oriented LLM That Hears Acoustic Context
Mar 19, 2025
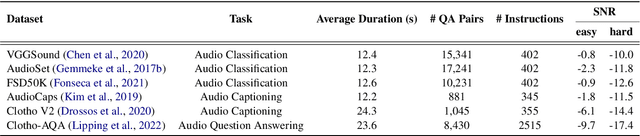
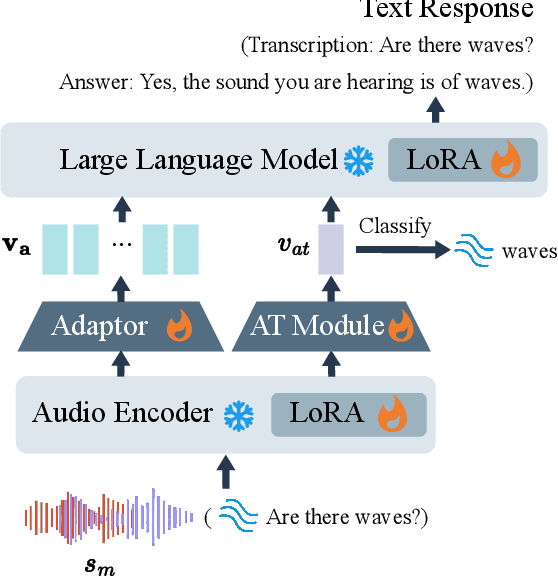
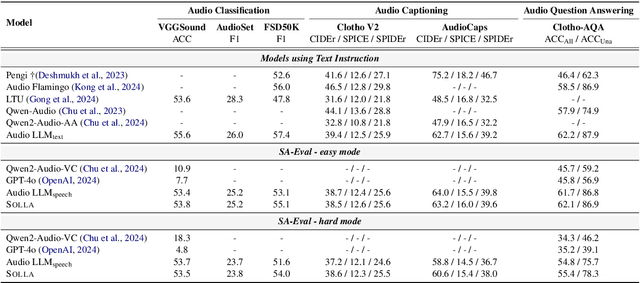
Large Language Models (LLMs) have recently shown remarkable ability to process not only text but also multimodal inputs such as speech and audio. However, most existing models primarily focus on analyzing input signals using text instructions, overlooking scenarios in which speech instructions and audio are mixed and serve as inputs to the model. To address these challenges, we introduce Solla, a novel framework designed to understand speech-based questions and hear the acoustic context concurrently. Solla incorporates an audio tagging module to effectively identify and represent audio events, as well as an ASR-assisted prediction method to improve comprehension of spoken content. To rigorously evaluate Solla and other publicly available models, we propose a new benchmark dataset called SA-Eval, which includes three tasks: audio event classification, audio captioning, and audio question answering. SA-Eval has diverse speech instruction with various speaking styles, encompassing two difficulty levels, easy and hard, to capture the range of real-world acoustic conditions. Experimental results show that Solla performs on par with or outperforms baseline models on both the easy and hard test sets, underscoring its effectiveness in jointly understanding speech and audio.
SALMONN-omni: A Codec-free LLM for Full-duplex Speech Understanding and Generation
Nov 27, 2024



Full-duplex multimodal large language models (LLMs) provide a unified framework for addressing diverse speech understanding and generation tasks, enabling more natural and seamless human-machine conversations. Unlike traditional modularised conversational AI systems, which separate speech recognition, understanding, and text-to-speech generation into distinct components, multimodal LLMs operate as single end-to-end models. This streamlined design eliminates error propagation across components and fully leverages the rich non-verbal information embedded in input speech signals. We introduce SALMONN-omni, a codec-free, full-duplex speech understanding and generation model capable of simultaneously listening to its own generated speech and background sounds while speaking. To support this capability, we propose a novel duplex spoken dialogue framework incorporating a ``thinking'' mechanism that facilitates asynchronous text and speech generation relying on embeddings instead of codecs (quantized speech and audio tokens). Experimental results demonstrate SALMONN-omni's versatility across a broad range of streaming speech tasks, including speech recognition, speech enhancement, and spoken question answering. Additionally, SALMONN-omni excels at managing turn-taking, barge-in, and echo cancellation scenarios, establishing its potential as a robust prototype for full-duplex conversational AI systems. To the best of our knowledge, SALMONN-omni is the first codec-free model of its kind. A full technical report along with model checkpoints will be released soon.
Enabling Auditory Large Language Models for Automatic Speech Quality Evaluation
Sep 25, 2024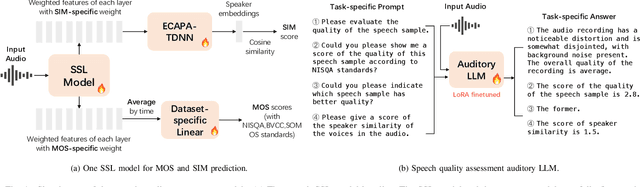
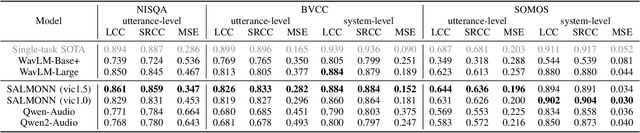


Speech quality assessment typically requires evaluating audio from multiple aspects, such as mean opinion score (MOS) and speaker similarity (SIM) etc., which can be challenging to cover using one small model designed for a single task. In this paper, we propose leveraging recently introduced auditory large language models (LLMs) for automatic speech quality assessment. By employing task-specific prompts, auditory LLMs are finetuned to predict MOS, SIM and A/B testing results, which are commonly used for evaluating text-to-speech systems. Additionally, the finetuned auditory LLM is able to generate natural language descriptions assessing aspects like noisiness, distortion, discontinuity, and overall quality, providing more interpretable outputs. Extensive experiments have been performed on the NISQA, BVCC, SOMOS and VoxSim speech quality datasets, using open-source auditory LLMs such as SALMONN, Qwen-Audio, and Qwen2-Audio. For the natural language descriptions task, a commercial model Google Gemini 1.5 Pro is also evaluated. The results demonstrate that auditory LLMs achieve competitive performance compared to state-of-the-art task-specific small models in predicting MOS and SIM, while also delivering promising results in A/B testing and natural language descriptions. Our data processing scripts and finetuned model checkpoints will be released upon acceptance.
SD-Eval: A Benchmark Dataset for Spoken Dialogue Understanding Beyond Words
Jun 19, 2024



Speech encompasses a wealth of information, including but not limited to content, paralinguistic, and environmental information. This comprehensive nature of speech significantly impacts communication and is crucial for human-computer interaction. Chat-Oriented Large Language Models (LLMs), known for their general-purpose assistance capabilities, have evolved to handle multi-modal inputs, including speech. Although these models can be adept at recognizing and analyzing speech, they often fall short of generating appropriate responses. We argue that this is due to the lack of principles on task definition and model development, which requires open-source datasets and metrics suitable for model evaluation. To bridge the gap, we present SD-Eval, a benchmark dataset aimed at multidimensional evaluation of spoken dialogue understanding and generation. SD-Eval focuses on paralinguistic and environmental information and includes 7,303 utterances, amounting to 8.76 hours of speech data. The data is aggregated from eight public datasets, representing four perspectives: emotion, accent, age, and background sound. To assess the SD-Eval benchmark dataset, we implement three different models and construct a training set following a similar process as SD-Eval. The training set contains 1,052.72 hours of speech data and 724.4k utterances. We also conduct a comprehensive evaluation using objective evaluation methods (e.g. BLEU and ROUGE), subjective evaluations and LLM-based metrics for the generated responses. Models conditioned with paralinguistic and environmental information outperform their counterparts in both objective and subjective measures. Moreover, experiments demonstrate LLM-based metrics show a higher correlation with human evaluation compared to traditional metrics. We open-source SD-Eval at https://github.com/amphionspace/SD-Eval.
CoAVT: A Cognition-Inspired Unified Audio-Visual-Text Pre-Training Model for Multimodal Processing
Jan 22, 2024



There has been a long-standing quest for a unified audio-visual-text model to enable various multimodal understanding tasks, which mimics the listening, seeing and reading process of human beings. Humans tends to represent knowledge using two separate systems: one for representing verbal (textual) information and one for representing non-verbal (visual and auditory) information. These two systems can operate independently but can also interact with each other. Motivated by this understanding of human cognition, in this paper, we introduce CoAVT -- a novel cognition-inspired Correlated Audio-Visual-Text pre-training model to connect the three modalities. It contains a joint audio-visual encoder that learns to encode audio-visual synchronization information together with the audio and visual content for non-verbal information, and a text encoder to handle textual input for verbal information. To bridge the gap between modalities, CoAVT employs a query encoder, which contains a set of learnable query embeddings, and extracts the most informative audiovisual features of the corresponding text. Additionally, to leverage the correspondences between audio and vision with language respectively, we also establish the audio-text and visual-text bi-modal alignments upon the foundational audiovisual-text tri-modal alignment to enhance the multimodal representation learning. Finally, we jointly optimize CoAVT model with three multimodal objectives: contrastive loss, matching loss and language modeling loss. Extensive experiments show that CoAVT can learn strong multimodal correlations and be generalized to various downstream tasks. CoAVT establishes new state-of-the-art performance on text-video retrieval task on AudioCaps for both zero-shot and fine-tuning settings, audio-visual event classification and audio-visual retrieval tasks on AudioSet and VGGSound.
Phonetic and Prosody-aware Self-supervised Learning Approach for Non-native Fluency Scoring
May 19, 2023Speech fluency/disfluency can be evaluated by analyzing a range of phonetic and prosodic features. Deep neural networks are commonly trained to map fluency-related features into the human scores. However, the effectiveness of deep learning-based models is constrained by the limited amount of labeled training samples. To address this, we introduce a self-supervised learning (SSL) approach that takes into account phonetic and prosody awareness for fluency scoring. Specifically, we first pre-train the model using a reconstruction loss function, by masking phones and their durations jointly on a large amount of unlabeled speech and text prompts. We then fine-tune the pre-trained model using human-annotated scoring data. Our experimental results, conducted on datasets such as Speechocean762 and our non-native datasets, show that our proposed method outperforms the baseline systems in terms of Pearson correlation coefficients (PCC). Moreover, we also conduct an ablation study to better understand the contribution of phonetic and prosody factors during the pre-training stage.
Leveraging phone-level linguistic-acoustic similarity for utterance-level pronunciation scoring
Mar 13, 2023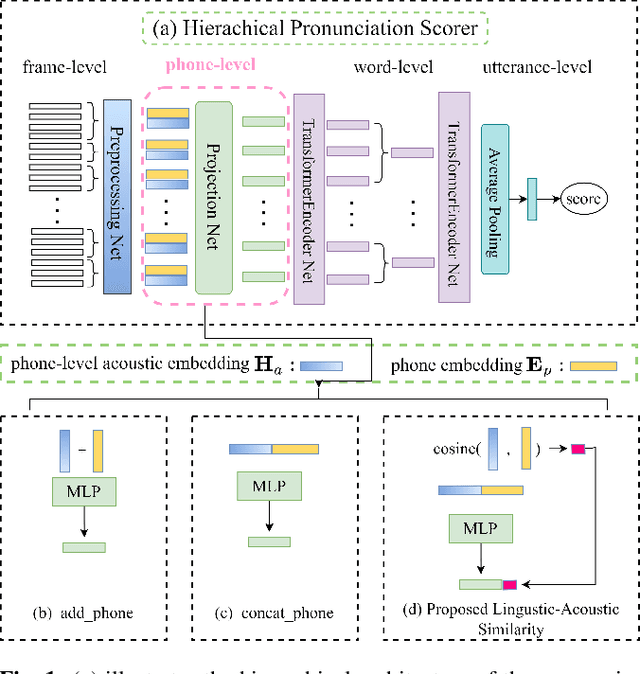
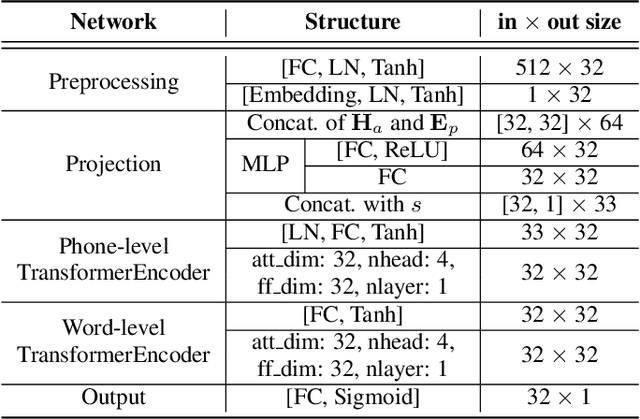
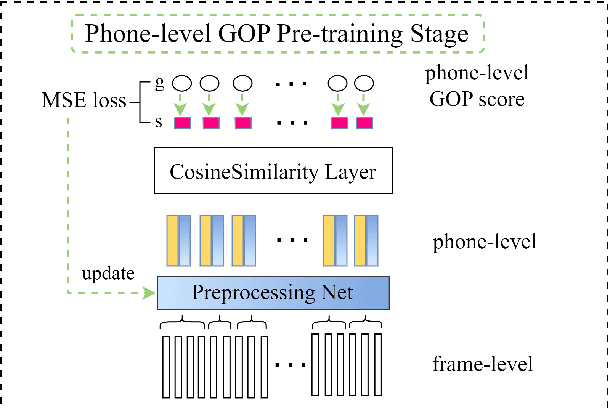
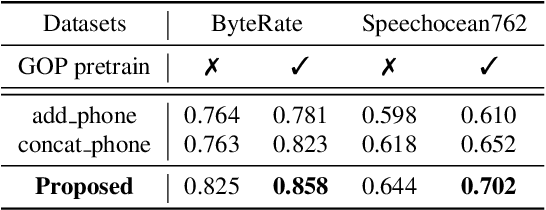
Recent studies on pronunciation scoring have explored the effect of introducing phone embeddings as reference pronunciation, but mostly in an implicit manner, i.e., addition or concatenation of reference phone embedding and actual pronunciation of the target phone as the phone-level pronunciation quality representation. In this paper, we propose to use linguistic-acoustic similarity to explicitly measure the deviation of non-native production from its native reference for pronunciation assessment. Specifically, the deviation is first estimated by the cosine similarity between reference phone embedding and corresponding acoustic embedding. Next, a phone-level Goodness of pronunciation (GOP) pre-training stage is introduced to guide this similarity-based learning for better initialization of the aforementioned two embeddings. Finally, a transformer-based hierarchical pronunciation scorer is used to map a sequence of phone embeddings, acoustic embeddings along with their similarity measures to predict the final utterance-level score. Experimental results on the non-native databases suggest that the proposed system significantly outperforms the baselines, where the acoustic and phone embeddings are simply added or concatenated. A further examination shows that the phone embeddings learned in the proposed approach are able to capture linguistic-acoustic attributes of native pronunciation as reference.
An ASR-free Fluency Scoring Approach with Self-Supervised Learning
Mar 13, 2023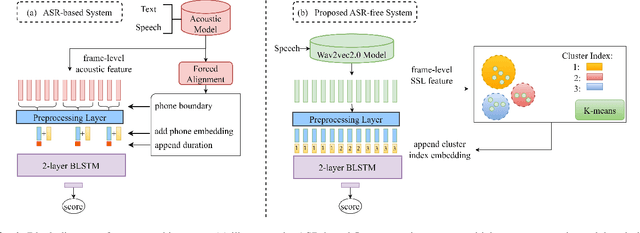
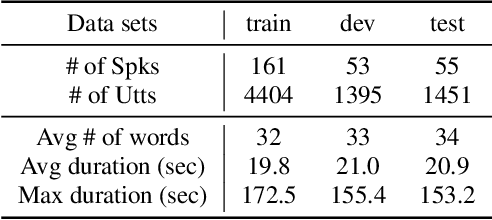
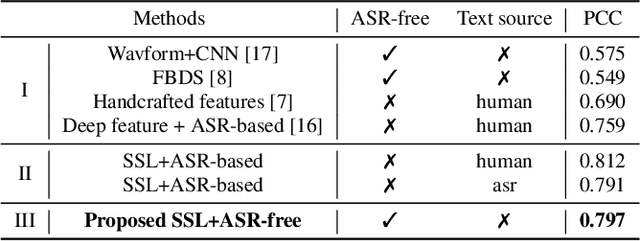
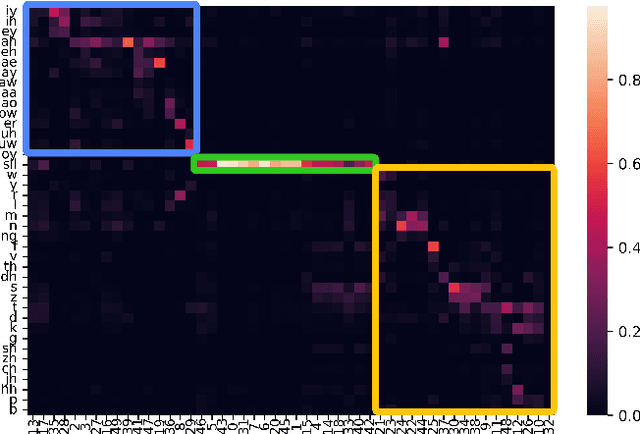
A typical fluency scoring system generally relies on an automatic speech recognition (ASR) system to obtain time stamps in input speech for either the subsequent calculation of fluency-related features or directly modeling speech fluency with an end-to-end approach. This paper describes a novel ASR-free approach for automatic fluency assessment using self-supervised learning (SSL). Specifically, wav2vec2.0 is used to extract frame-level speech features, followed by K-means clustering to assign a pseudo label (cluster index) to each frame. A BLSTM-based model is trained to predict an utterance-level fluency score from frame-level SSL features and the corresponding cluster indexes. Neither speech transcription nor time stamp information is required in the proposed system. It is ASR-free and can potentially avoid the ASR errors effect in practice. Experimental results carried out on non-native English databases show that the proposed approach significantly improves the performance in the "open response" scenario as compared to previous methods and matches the recently reported performance in the "read aloud" scenario.