 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMimicLM: Zero-Shot Voice Imitation through Autoregressive Modeling of Pseudo-Parallel Speech Corpora
Apr 13, 2026Voice imitation aims to transform source speech to match a reference speaker's timbre and speaking style while preserving linguistic content. A straightforward approach is to train on triplets of (source, reference, target), where source and target share the same content but target matches the reference's voice characteristics, yet such data is extremely scarce. Existing approaches either employ carefully designed disentanglement architectures to bypass this data scarcity or leverage external systems to synthesize pseudo-parallel training data. However, the former requires intricate model design, and the latter faces a quality ceiling when synthetic speech is used as training targets. To address these limitations, we propose MimicLM, which takes a novel approach by using synthetic speech as training sources while retaining real recordings as targets. This design enables the model to learn directly from real speech distributions, breaking the synthetic quality ceiling. Building on this data construction approach, we incorporate interleaved text-audio modeling to guide the generation of content-accurate speech and apply post-training with preference alignment to mitigate the inherent distributional mismatch when training on synthetic data. Experiments demonstrate that MimicLM achieves superior voice imitation quality with a simple yet effective architecture, significantly outperforming existing methods in naturalness while maintaining competitive similarity scores across speaker identity, accent, and emotion dimensions.
Scaling Speech Tokenizers with Diffusion Autoencoders
Feb 06, 2026Speech tokenizers are foundational to speech language models, yet existing approaches face two major challenges: (1) balancing trade-offs between encoding semantics for understanding and acoustics for reconstruction, and (2) achieving low bit rates and low token rates. We propose Speech Diffusion Tokenizer (SiTok), a diffusion autoencoder that jointly learns semantic-rich representations through supervised learning and enables high-fidelity audio reconstruction with diffusion. We scale SiTok to 1.6B parameters and train it on 2 million hours of speech. Experiments show that SiTok outperforms strong baselines on understanding, reconstruction and generation tasks, at an extremely low token rate of $12.5$ Hz and a bit-rate of 200 bits-per-second.
SpeechJudge: Towards Human-Level Judgment for Speech Naturalness
Nov 11, 2025

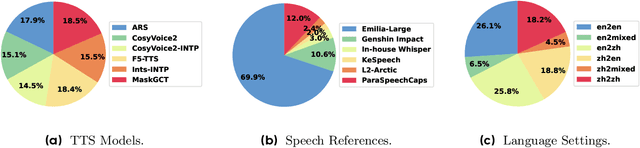
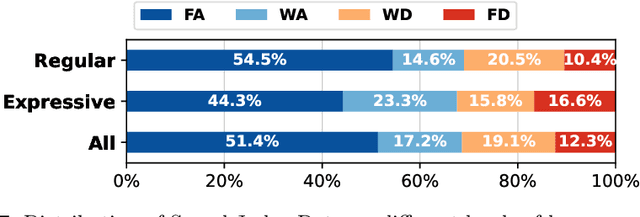
Aligning large generative models with human feedback is a critical challenge. In speech synthesis, this is particularly pronounced due to the lack of a large-scale human preference dataset, which hinders the development of models that truly align with human perception. To address this, we introduce SpeechJudge, a comprehensive suite comprising a dataset, a benchmark, and a reward model centered on naturalness--one of the most fundamental subjective metrics for speech synthesis. First, we present SpeechJudge-Data, a large-scale human feedback corpus of 99K speech pairs. The dataset is constructed using a diverse set of advanced zero-shot text-to-speech (TTS) models across diverse speech styles and multiple languages, with human annotations for both intelligibility and naturalness preference. From this, we establish SpeechJudge-Eval, a challenging benchmark for speech naturalness judgment. Our evaluation reveals that existing metrics and AudioLLMs struggle with this task; the leading model, Gemini-2.5-Flash, achieves less than 70% agreement with human judgment, highlighting a significant gap for improvement. To bridge this gap, we develop SpeechJudge-GRM, a generative reward model (GRM) based on Qwen2.5-Omni-7B. It is trained on SpeechJudge-Data via a two-stage post-training process: Supervised Fine-Tuning (SFT) with Chain-of-Thought rationales followed by Reinforcement Learning (RL) with GRPO on challenging cases. On the SpeechJudge-Eval benchmark, the proposed SpeechJudge-GRM demonstrates superior performance, achieving 77.2% accuracy (and 79.4% after inference-time scaling @10) compared to a classic Bradley-Terry reward model (72.7%). Furthermore, SpeechJudge-GRM can be also employed as a reward function during the post-training of speech generation models to facilitate their alignment with human preferences.
Audio Deepfake Verification
Sep 10, 2025With the rapid development of deepfake technology, simply making a binary judgment of true or false on audio is no longer sufficient to meet practical needs. Accurately determining the specific deepfake method has become crucial. This paper introduces the Audio Deepfake Verification (ADV) task, effectively addressing the limitations of existing deepfake source tracing methods in closed-set scenarios, aiming to achieve open-set deepfake source tracing. Meanwhile, the Audity dual-branch architecture is proposed, extracting deepfake features from two dimensions: audio structure and generation artifacts. Experimental results show that the dual-branch Audity architecture outperforms any single-branch configuration, and it can simultaneously achieve excellent performance in both deepfake detection and verification tasks.
Multi-Metric Preference Alignment for Generative Speech Restoration
Aug 24, 2025Recent generative models have significantly advanced speech restoration tasks, yet their training objectives often misalign with human perceptual preferences, resulting in suboptimal quality. While post-training alignment has proven effective in other generative domains like text and image generation, its application to generative speech restoration remains largely under-explored. This work investigates the challenges of applying preference-based post-training to this task, focusing on how to define a robust preference signal and curate high-quality data to avoid reward hacking. To address these challenges, we propose a multi-metric preference alignment strategy. We construct a new dataset, GenSR-Pref, comprising 80K preference pairs, where each chosen sample is unanimously favored by a complementary suite of metrics covering perceptual quality, signal fidelity, content consistency, and timbre preservation. This principled approach ensures a holistic preference signal. Applying Direct Preference Optimization (DPO) with our dataset, we observe consistent and significant performance gains across three diverse generative paradigms: autoregressive models (AR), masked generative models (MGM), and flow-matching models (FM) on various restoration benchmarks, in both objective and subjective evaluations. Ablation studies confirm the superiority of our multi-metric strategy over single-metric approaches in mitigating reward hacking. Furthermore, we demonstrate that our aligned models can serve as powerful ''data annotators'', generating high-quality pseudo-labels to serve as a supervision signal for traditional discriminative models in data-scarce scenarios like singing voice restoration. Demo Page:https://gensr-pref.github.io
NVSpeech: An Integrated and Scalable Pipeline for Human-Like Speech Modeling with Paralinguistic Vocalizations
Aug 06, 2025Paralinguistic vocalizations-including non-verbal sounds like laughter and breathing, as well as lexicalized interjections such as "uhm" and "oh"-are integral to natural spoken communication. Despite their importance in conveying affect, intent, and interactional cues, such cues remain largely overlooked in conventional automatic speech recognition (ASR) and text-to-speech (TTS) systems. We present NVSpeech, an integrated and scalable pipeline that bridges the recognition and synthesis of paralinguistic vocalizations, encompassing dataset construction, ASR modeling, and controllable TTS. (1) We introduce a manually annotated dataset of 48,430 human-spoken utterances with 18 word-level paralinguistic categories. (2) We develop the paralinguistic-aware ASR model, which treats paralinguistic cues as inline decodable tokens (e.g., "You're so funny [Laughter]"), enabling joint lexical and non-verbal transcription. This model is then used to automatically annotate a large corpus, the first large-scale Chinese dataset of 174,179 utterances (573 hours) with word-level alignment and paralingustic cues. (3) We finetune zero-shot TTS models on both human- and auto-labeled data to enable explicit control over paralinguistic vocalizations, allowing context-aware insertion at arbitrary token positions for human-like speech synthesis. By unifying the recognition and generation of paralinguistic vocalizations, NVSpeech offers the first open, large-scale, word-level annotated pipeline for expressive speech modeling in Mandarin, integrating recognition and synthesis in a scalable and controllable manner. Dataset and audio demos are available at https://nvspeech170k.github.io/.
DualCodec: A Low-Frame-Rate, Semantically-Enhanced Neural Audio Codec for Speech Generation
May 19, 2025Neural audio codecs form the foundational building blocks for language model (LM)-based speech generation. Typically, there is a trade-off between frame rate and audio quality. This study introduces a low-frame-rate, semantically enhanced codec model. Existing approaches distill semantically rich self-supervised (SSL) representations into the first-layer codec tokens. This work proposes DualCodec, a dual-stream encoding approach that integrates SSL and waveform representations within an end-to-end codec framework. In this setting, DualCodec enhances the semantic information in the first-layer codec and enables the codec system to maintain high audio quality while operating at a low frame rate. Note that a low-frame-rate codec improves the efficiency of speech generation. Experimental results on audio codec and speech generation tasks confirm the effectiveness of the proposed DualCodec compared to state-of-the-art codec systems, such as Mimi Codec, SpeechTokenizer, DAC, and Encodec. Demos and codes are available at: https://dualcodec.github.io
Advancing Zero-shot Text-to-Speech Intelligibility across Diverse Domains via Preference Alignment
May 07, 2025Modern zero-shot text-to-speech (TTS) systems, despite using extensive pre-training, often struggle in challenging scenarios such as tongue twisters, repeated words, code-switching, and cross-lingual synthesis, leading to intelligibility issues. To address these limitations, this paper leverages preference alignment techniques, which enable targeted construction of out-of-pretraining-distribution data to enhance performance. We introduce a new dataset, named the Intelligibility Preference Speech Dataset (INTP), and extend the Direct Preference Optimization (DPO) framework to accommodate diverse TTS architectures. After INTP alignment, in addition to intelligibility, we observe overall improvements including naturalness, similarity, and audio quality for multiple TTS models across diverse domains. Based on that, we also verify the weak-to-strong generalization ability of INTP for more intelligible models such as CosyVoice 2 and Ints. Moreover, we showcase the potential for further improvements through iterative alignment based on Ints. Audio samples are available at https://intalign.github.io/.
Metis: A Foundation Speech Generation Model with Masked Generative Pre-training
Feb 05, 2025We introduce Metis, a foundation model for unified speech generation. Unlike previous task-specific or multi-task models, Metis follows a pre-training and fine-tuning paradigm. It is pre-trained on large-scale unlabeled speech data using masked generative modeling and then fine-tuned to adapt to diverse speech generation tasks. Specifically, 1) Metis utilizes two discrete speech representations: SSL tokens derived from speech self-supervised learning (SSL) features, and acoustic tokens directly quantized from waveforms. 2) Metis performs masked generative pre-training on SSL tokens, utilizing 300K hours of diverse speech data, without any additional condition. 3) Through fine-tuning with task-specific conditions, Metis achieves efficient adaptation to various speech generation tasks while supporting multimodal input, even when using limited data and trainable parameters. Experiments demonstrate that Metis can serve as a foundation model for unified speech generation: Metis outperforms state-of-the-art task-specific or multi-task systems across five speech generation tasks, including zero-shot text-to-speech, voice conversion, target speaker extraction, speech enhancement, and lip-to-speech, even with fewer than 20M trainable parameters or 300 times less training data. Audio samples are are available at https://metis-demo.github.io/.
Emilia: A Large-Scale, Extensive, Multilingual, and Diverse Dataset for Speech Generation
Jan 27, 2025Recent advancements in speech generation have been driven by the large-scale training datasets. However, current models fall short of capturing the spontaneity and variability inherent in real-world human speech, due to their reliance on audiobook datasets limited to formal read-aloud speech styles. To bridge this gap, we introduce Emilia-Pipe, an open-source preprocessing pipeline to extract high-quality training data from valuable yet underexplored in-the-wild data that capture spontaneous human speech in real-world contexts. By leveraging Emilia-Pipe, we construct Emilia, the first multilingual speech generation dataset derived from in-the-wild speech data. This dataset comprises over 101k hours of speech across six languages: English, Chinese, German, French, Japanese, and Korean. Besides, we expand Emilia to Emilia-Large, a dataset exceeding 216k hours, making it the largest open-source speech generation dataset available. Extensive experiments demonstrate that Emilia significantly outperforms traditional audiobook datasets in generating spontaneous and human-like speech, showcasing superior performance in capturing diverse speaker timbre and speaking styles of real-world human speech. Furthermore, this work underscores the importance of scaling dataset size to advance speech generation research and validates the effectiveness of Emilia for both multilingual and crosslingual speech generation.