 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Aliasing-Free Neural Audio Synthesis
Dec 23, 2025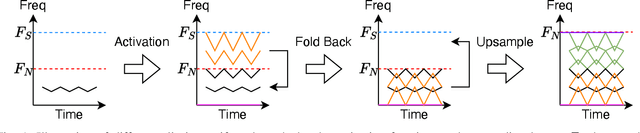
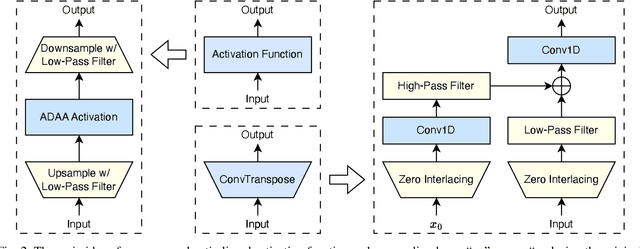
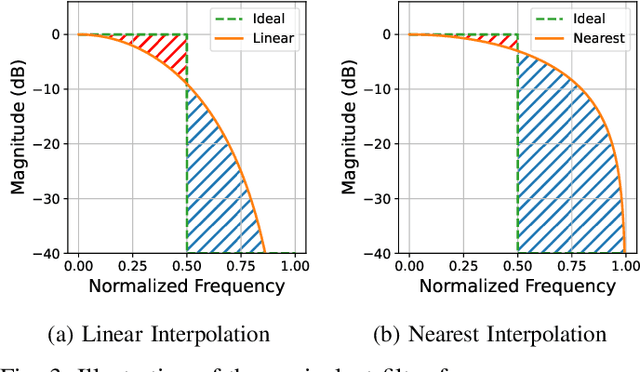
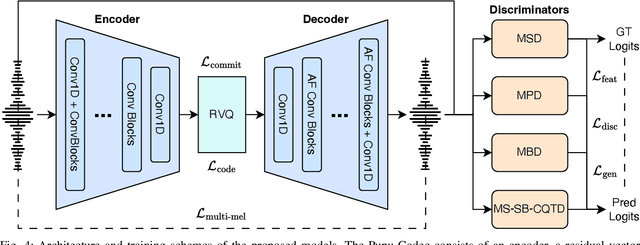
Neural vocoders and codecs reconstruct waveforms from acoustic representations, which directly impact the audio quality. Among existing methods, upsampling-based time-domain models are superior in both inference speed and synthesis quality, achieving state-of-the-art performance. Still, despite their success in producing perceptually natural sound, their synthesis fidelity remains limited due to the aliasing artifacts brought by the inadequately designed model architectures. In particular, the unconstrained nonlinear activation generates an infinite number of harmonics that exceed the Nyquist frequency, resulting in ``folded-back'' aliasing artifacts. The widely used upsampling layer, ConvTranspose, copies the mirrored low-frequency parts to fill the empty high-frequency region, resulting in ``mirrored'' aliasing artifacts. Meanwhile, the combination of its inherent periodicity and the mirrored DC bias also brings ``tonal artifact,'' resulting in constant-frequency ringing. This paper aims to solve these issues from a signal processing perspective. Specifically, we apply oversampling and anti-derivative anti-aliasing to the activation function to obtain its anti-aliased form, and replace the problematic ConvTranspose layer with resampling to avoid the ``tonal artifact'' and eliminate aliased components. Based on our proposed anti-aliased modules, we introduce Pupu-Vocoder and Pupu-Codec, and release high-quality pre-trained checkpoints to facilitate audio generation research. We build a test signal benchmark to illustrate the effectiveness of the anti-aliased modules, and conduct experiments on speech, singing voice, music, and audio to validate our proposed models. Experimental results confirm that our lightweight Pupu-Vocoder and Pupu-Codec models can easily outperform existing systems on singing voice, music, and audio, while achieving comparable performance on speech.
Neurodyne: Neural Pitch Manipulation with Representation Learning and Cycle-Consistency GAN
May 21, 2025Pitch manipulation is the process of producers adjusting the pitch of an audio segment to a specific key and intonation, which is essential in music production. Neural-network-based pitch-manipulation systems have been popular in recent years due to their superior synthesis quality compared to classical DSP methods. However, their performance is still limited due to their inaccurate feature disentanglement using source-filter models and the lack of paired in- and out-of-tune training data. This work proposes Neurodyne to address these issues. Specifically, Neurodyne uses adversarial representation learning to learn a pitch-independent latent representation to avoid inaccurate disentanglement and cycle-consistency training to create paired training data implicitly. Experimental results on global-key and template-based pitch manipulation demonstrate the effectiveness of the proposed system, marking improved synthesis quality while maintaining the original singer identity.
SingNet: Towards a Large-Scale, Diverse, and In-the-Wild Singing Voice Dataset
May 14, 2025The lack of a publicly-available large-scale and diverse dataset has long been a significant bottleneck for singing voice applications like Singing Voice Synthesis (SVS) and Singing Voice Conversion (SVC). To tackle this problem, we present SingNet, an extensive, diverse, and in-the-wild singing voice dataset. Specifically, we propose a data processing pipeline to extract ready-to-use training data from sample packs and songs on the internet, forming 3000 hours of singing voices in various languages and styles. Furthermore, to facilitate the use and demonstrate the effectiveness of SingNet, we pre-train and open-source various state-of-the-art (SOTA) models on Wav2vec2, BigVGAN, and NSF-HiFiGAN based on our collected singing voice data. We also conduct benchmark experiments on Automatic Lyric Transcription (ALT), Neural Vocoder, and Singing Voice Conversion (SVC). Audio demos are available at: https://singnet-dataset.github.io/.
Diff-SSL-G-Comp: Towards a Large-Scale and Diverse Dataset for Virtual Analog Modeling
Apr 06, 2025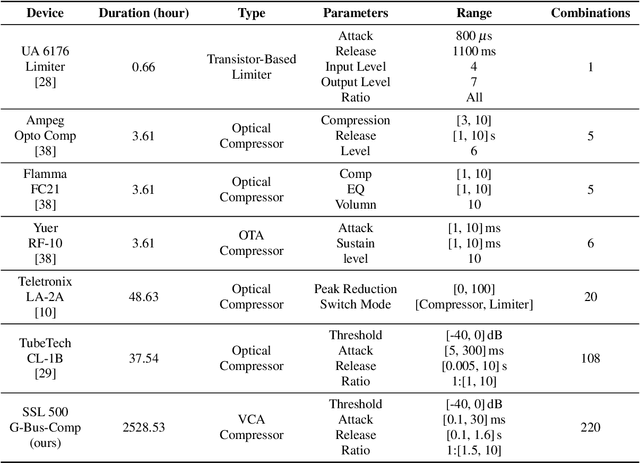
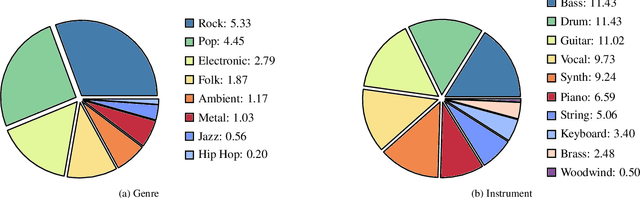
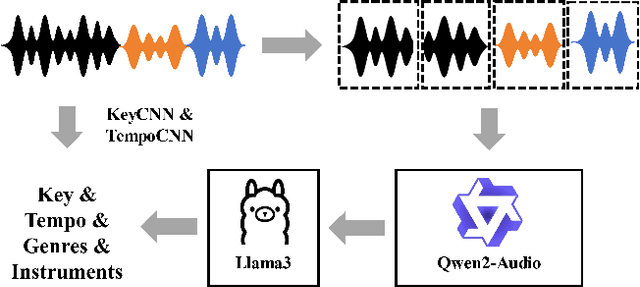
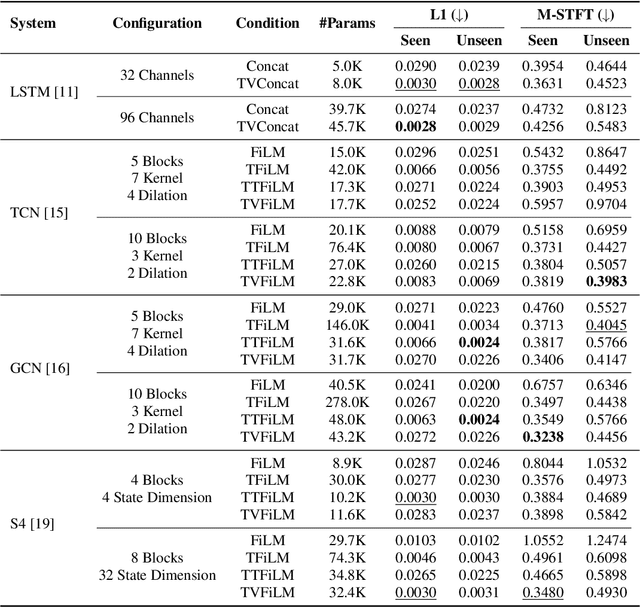
Virtual Analog (VA) modeling aims to simulate the behavior of hardware circuits via algorithms to replicate their tone digitally. Dynamic Range Compressor (DRC) is an audio processing module that controls the dynamics of a track by reducing and amplifying the volumes of loud and quiet sounds, which is essential in music production. In recent years, neural-network-based VA modeling has shown great potential in producing high-fidelity models. However, due to the lack of data quantity and diversity, their generalization ability in different parameter settings and input sounds is still limited. To tackle this problem, we present Diff-SSL-G-Comp, the first large-scale and diverse dataset for modeling the SSL 500 G-Bus Compressor. Specifically, we manually collected 175 unmastered songs from the Cambridge Multitrack Library. We recorded the compressed audio in 220 parameter combinations, resulting in an extensive 2528-hour dataset with diverse genres, instruments, tempos, and keys. Moreover, to facilitate the use of our proposed dataset, we conducted benchmark experiments in various open-sourced black-box and grey-box models, as well as white-box plugins. We also conducted ablation studies in different data subsets to illustrate the effectiveness of improved data diversity and quantity. The dataset and demos are on our project page: http://www.yichenggu.com/DiffSSLGComp/.
Emilia: A Large-Scale, Extensive, Multilingual, and Diverse Dataset for Speech Generation
Jan 27, 2025Recent advancements in speech generation have been driven by the large-scale training datasets. However, current models fall short of capturing the spontaneity and variability inherent in real-world human speech, due to their reliance on audiobook datasets limited to formal read-aloud speech styles. To bridge this gap, we introduce Emilia-Pipe, an open-source preprocessing pipeline to extract high-quality training data from valuable yet underexplored in-the-wild data that capture spontaneous human speech in real-world contexts. By leveraging Emilia-Pipe, we construct Emilia, the first multilingual speech generation dataset derived from in-the-wild speech data. This dataset comprises over 101k hours of speech across six languages: English, Chinese, German, French, Japanese, and Korean. Besides, we expand Emilia to Emilia-Large, a dataset exceeding 216k hours, making it the largest open-source speech generation dataset available. Extensive experiments demonstrate that Emilia significantly outperforms traditional audiobook datasets in generating spontaneous and human-like speech, showcasing superior performance in capturing diverse speaker timbre and speaking styles of real-world human speech. Furthermore, this work underscores the importance of scaling dataset size to advance speech generation research and validates the effectiveness of Emilia for both multilingual and crosslingual speech generation.
Emilia: An Extensive, Multilingual, and Diverse Speech Dataset for Large-Scale Speech Generation
Jul 07, 2024



Recently, speech generation models have made significant progress by using large-scale training data. However, the research community struggle to produce highly spontaneous and human-like speech due to the lack of large-scale, diverse, and spontaneous speech data. This paper presents \textit{Emilia}, the first multilingual speech generation dataset from in-the-wild speech data, and Emilia-Pipe, the first open-source preprocessing pipeline designed to transform in-the-wild speech data into high-quality training data with annotations for speech generation. Emilia starts with over 101k hours of speech in six languages and features diverse speech with varied speaking styles. To facilitate the scale-up of Emilia, the open-source pipeline Emilia-Pipe can process one hour of raw speech data ready for model training in a few mins, which enables the research community to collaborate on large-scale speech generation research. Experimental results validate the effectiveness of Emilia. Demos are available at: https://emilia-dataset.github.io/Emilia-Demo-Page/.
FoleyCrafter: Bring Silent Videos to Life with Lifelike and Synchronized Sounds
Jul 01, 2024
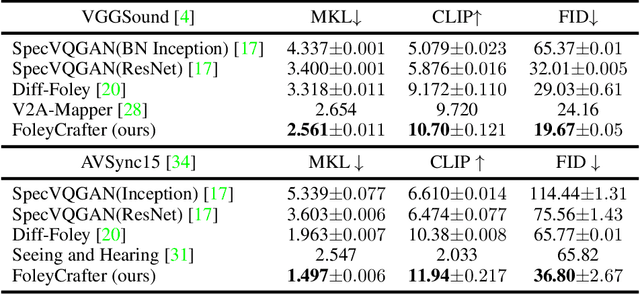
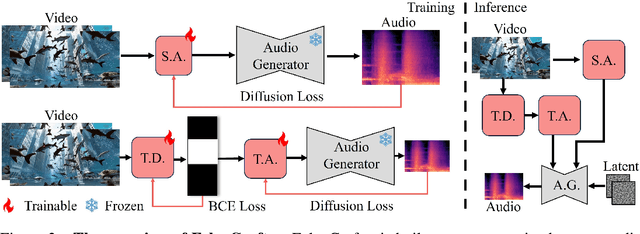

We study Neural Foley, the automatic generation of high-quality sound effects synchronizing with videos, enabling an immersive audio-visual experience. Despite its wide range of applications, existing approaches encounter limitations when it comes to simultaneously synthesizing high-quality and video-aligned (i.e.,, semantic relevant and temporal synchronized) sounds. To overcome these limitations, we propose FoleyCrafter, a novel framework that leverages a pre-trained text-to-audio model to ensure high-quality audio generation. FoleyCrafter comprises two key components: the semantic adapter for semantic alignment and the temporal controller for precise audio-video synchronization. The semantic adapter utilizes parallel cross-attention layers to condition audio generation on video features, producing realistic sound effects that are semantically relevant to the visual content. Meanwhile, the temporal controller incorporates an onset detector and a timestampbased adapter to achieve precise audio-video alignment. One notable advantage of FoleyCrafter is its compatibility with text prompts, enabling the use of text descriptions to achieve controllable and diverse video-to-audio generation according to user intents. We conduct extensive quantitative and qualitative experiments on standard benchmarks to verify the effectiveness of FoleyCrafter. Models and codes are available at https://github.com/open-mmlab/FoleyCrafter.
An Investigation of Time-Frequency Representation Discriminators for High-Fidelity Vocoder
Apr 26, 2024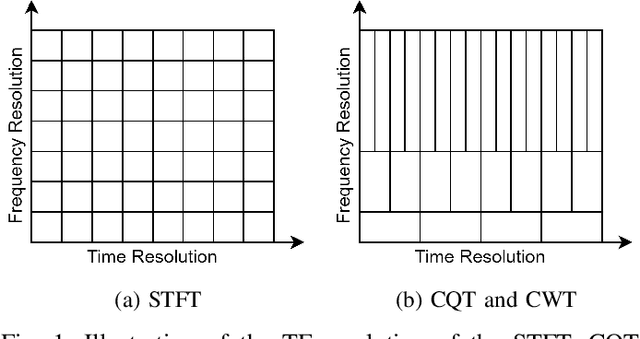
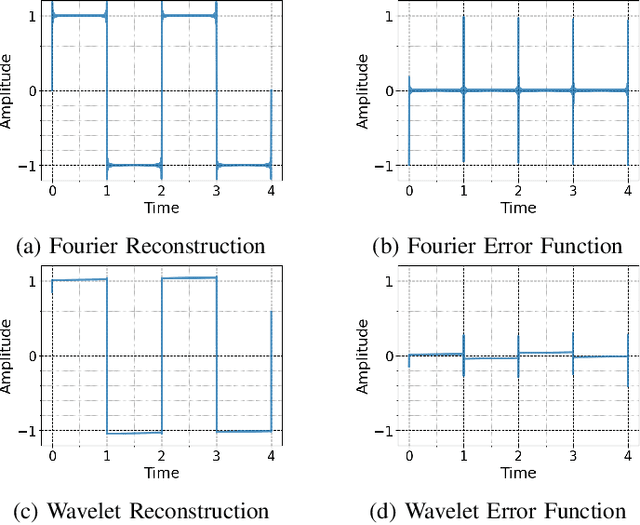
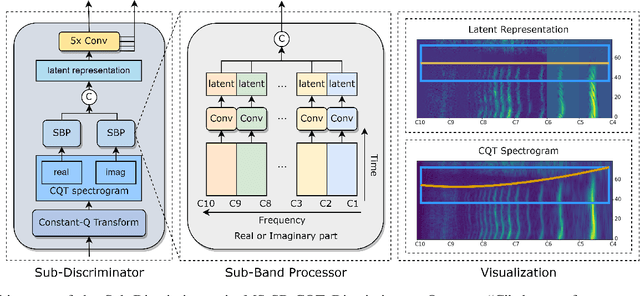
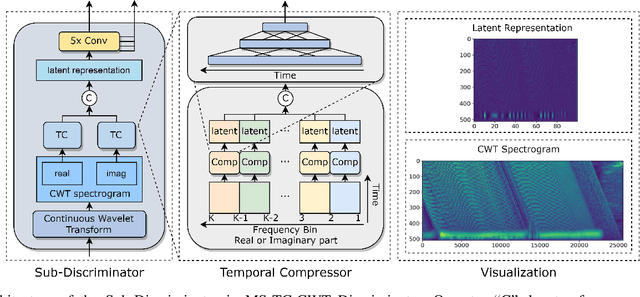
Generative Adversarial Network (GAN) based vocoders are superior in both inference speed and synthesis quality when reconstructing an audible waveform from an acoustic representation. This study focuses on improving the discriminator for GAN-based vocoders. Most existing Time-Frequency Representation (TFR)-based discriminators are rooted in Short-Time Fourier Transform (STFT), which owns a constant Time-Frequency (TF) resolution, linearly scaled center frequencies, and a fixed decomposition basis, making it incompatible with signals like singing voices that require dynamic attention for different frequency bands and different time intervals. Motivated by that, we propose a Multi-Scale Sub-Band Constant-Q Transform CQT (MS-SB-CQT) discriminator and a Multi-Scale Temporal-Compressed Continuous Wavelet Transform CWT (MS-TC-CWT) discriminator. Both CQT and CWT have a dynamic TF resolution for different frequency bands. In contrast, CQT has a better modeling ability in pitch information, and CWT has a better modeling ability in short-time transients. Experiments conducted on both speech and singing voices confirm the effectiveness of our proposed discriminators. Moreover, the STFT, CQT, and CWT-based discriminators can be used jointly for better performance. The proposed discriminators can boost the synthesis quality of various state-of-the-art GAN-based vocoders, including HiFi-GAN, BigVGAN, and APNet.
Amphion: An Open-Source Audio, Music and Speech Generation Toolkit
Dec 15, 2023

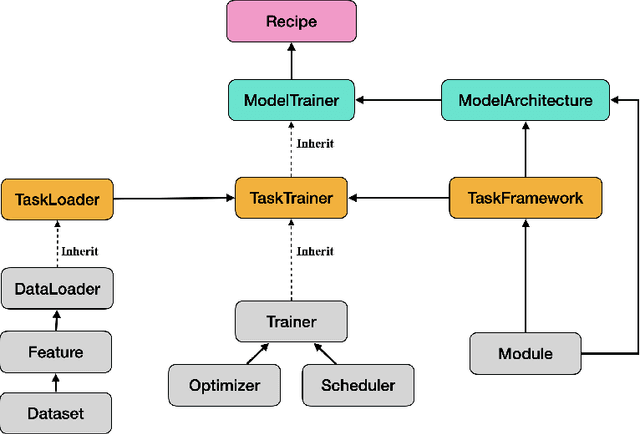

Amphion is a toolkit for Audio, Music, and Speech Generation. Its purpose is to support reproducible research and help junior researchers and engineers get started in the field of audio, music, and speech generation research and development. Amphion offers a unique feature: visualizations of classic models or architectures. We believe that these visualizations are beneficial for junior researchers and engineers who wish to gain a better understanding of the model. The North-Star objective of Amphion is to offer a platform for studying the conversion of any inputs into general audio. Amphion is designed to support individual generation tasks. In addition to the specific generation tasks, Amphion also includes several vocoders and evaluation metrics. A vocoder is an important module for producing high-quality audio signals, while evaluation metrics are critical for ensuring consistent metrics in generation tasks. In this paper, we provide a high-level overview of Amphion.