 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUDAPose: Unsupervised Domain Adaptation for Low-Light Human Pose Estimation
Apr 12, 2026Low-visibility scenarios, such as low-light conditions, pose significant challenges to human pose estimation due to the scarcity of annotated low-light datasets and the loss of visual information under poor illumination. Recent domain adaptation techniques attempt to utilize well-lit labels by augmenting well-lit images to mimic low-light conditions. But handcrafted augmentations oversimplify noise patterns, while learning-based methods often fail to preserve high-frequency low-light characteristics, producing unrealistic images that lead pose models to generalize poorly to real low-light scenes. Moreover, recent pose estimators rely on image cues through image-to-keypoint cross-attention, but these cues become unreliable under low-light conditions. To address these issues, we propose Unsupervised Domain Adaptation for Pose Estimation (UDAPose), a novel framework that synthesizes low-light images and dynamically fuses visual cues with pose priors for improved pose estimation. Specifically, our synthesis method incorporates a Direct-Current-based High-Pass Filter (DHF) and a Low-light Characteristics Injection Module (LCIM) to inject high-frequency details from input low-light images, overcoming rigidity or the detail loss in existing approaches. Furthermore, we introduce a Dynamic Control of Attention (DCA) module that adaptively balances image cues with learned pose priors in the Transformer architecture. Experiments show that UDAPose outperforms state-of-the-art methods, with notable AP gains of 10.1 (56.4%) on the ExLPose-test hard set (LL-H) and 7.4 (31.4%) in cross-dataset validation on EHPT-XC. Code: https://github.com/Vision-and-Multimodal-Intelligence-Lab/UDAPose
Heterogeneous Subgraph Network with Prompt Learning for Interpretable Depression Detection on Social Media
Jul 12, 2024



Massive social media data can reflect people's authentic thoughts, emotions, communication, etc., and therefore can be analyzed for early detection of mental health problems such as depression. Existing works about early depression detection on social media lacked interpretability and neglected the heterogeneity of social media data. Furthermore, they overlooked the global interaction among users. To address these issues, we develop a novel method that leverages a Heterogeneous Subgraph Network with Prompt Learning(HSNPL) and contrastive learning mechanisms. Specifically, prompt learning is employed to map users' implicit psychological symbols with excellent interpretability while deep semantic and diverse behavioral features are incorporated by a heterogeneous information network. Then, the heterogeneous graph network with a dual attention mechanism is constructed to model the relationships among heterogeneous social information at the feature level. Furthermore, the heterogeneous subgraph network integrating subgraph attention and self-supervised contrastive learning is developed to explore complicated interactions among users and groups at the user level. Extensive experimental results demonstrate that our proposed method significantly outperforms state-of-the-art methods for depression detection on social media.
Speak Out of Turn: Safety Vulnerability of Large Language Models in Multi-turn Dialogue
Feb 27, 2024



Large Language Models (LLMs) have been demonstrated to generate illegal or unethical responses, particularly when subjected to "jailbreak." Research on jailbreak has highlighted the safety issues of LLMs. However, prior studies have predominantly focused on single-turn dialogue, ignoring the potential complexities and risks presented by multi-turn dialogue, a crucial mode through which humans derive information from LLMs. In this paper, we argue that humans could exploit multi-turn dialogue to induce LLMs into generating harmful information. LLMs may not intend to reject cautionary or borderline unsafe queries, even if each turn is closely served for one malicious purpose in a multi-turn dialogue. Therefore, by decomposing an unsafe query into several sub-queries for multi-turn dialogue, we induced LLMs to answer harmful sub-questions incrementally, culminating in an overall harmful response. Our experiments, conducted across a wide range of LLMs, indicate current inadequacies in the safety mechanisms of LLMs in multi-turn dialogue. Our findings expose vulnerabilities of LLMs in complex scenarios involving multi-turn dialogue, presenting new challenges for the safety of LLMs.
Amphion: An Open-Source Audio, Music and Speech Generation Toolkit
Dec 15, 2023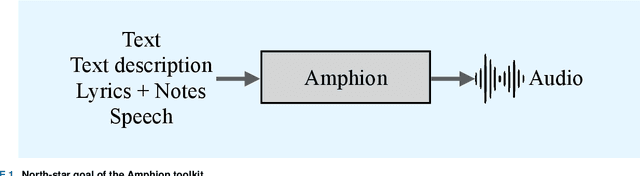

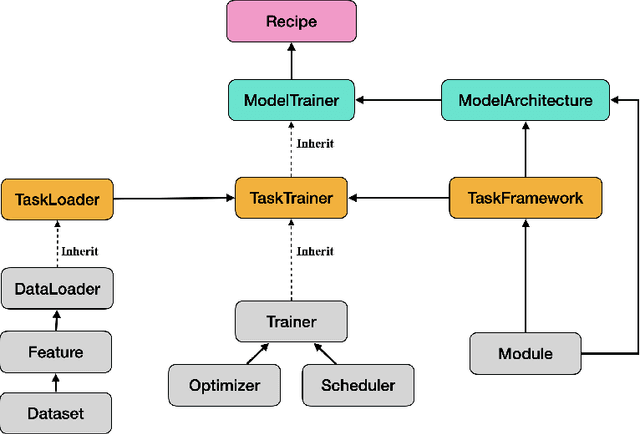

Amphion is a toolkit for Audio, Music, and Speech Generation. Its purpose is to support reproducible research and help junior researchers and engineers get started in the field of audio, music, and speech generation research and development. Amphion offers a unique feature: visualizations of classic models or architectures. We believe that these visualizations are beneficial for junior researchers and engineers who wish to gain a better understanding of the model. The North-Star objective of Amphion is to offer a platform for studying the conversion of any inputs into general audio. Amphion is designed to support individual generation tasks. In addition to the specific generation tasks, Amphion also includes several vocoders and evaluation metrics. A vocoder is an important module for producing high-quality audio signals, while evaluation metrics are critical for ensuring consistent metrics in generation tasks. In this paper, we provide a high-level overview of Amphion.
Leveraging Content-based Features from Multiple Acoustic Models for Singing Voice Conversion
Oct 17, 2023



Singing voice conversion (SVC) is a technique to enable an arbitrary singer to sing an arbitrary song. To achieve that, it is important to obtain speaker-agnostic representations from source audio, which is a challenging task. A common solution is to extract content-based features (e.g., PPGs) from a pretrained acoustic model. However, the choices for acoustic models are vast and varied. It is yet to be explored what characteristics of content features from different acoustic models are, and whether integrating multiple content features can help each other. Motivated by that, this study investigates three distinct content features, sourcing from WeNet, Whisper, and ContentVec, respectively. We explore their complementary roles in intelligibility, prosody, and conversion similarity for SVC. By integrating the multiple content features with a diffusion-based SVC model, our SVC system achieves superior conversion performance on both objective and subjective evaluation in comparison to a single source of content features. Our demo page and code can be available https://www.zhangxueyao.com/data/MultipleContentsSVC/index.html.
Edge-Featured Graph Attention Network
Jan 19, 2021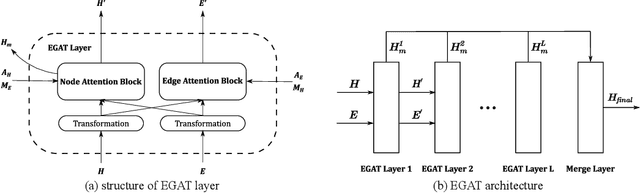

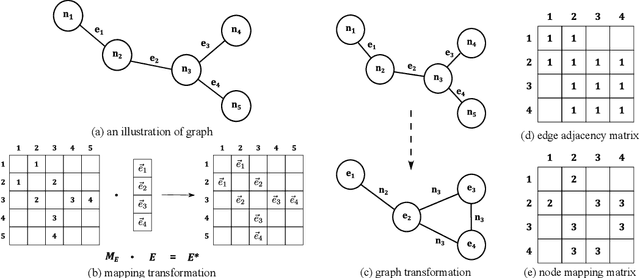
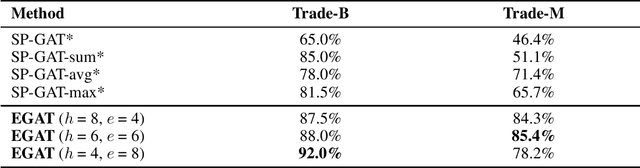
Lots of neural network architectures have been proposed to deal with learning tasks on graph-structured data. However, most of these models concentrate on only node features during the learning process. The edge features, which usually play a similarly important role as the nodes, are often ignored or simplified by these models. In this paper, we present edge-featured graph attention networks, namely EGATs, to extend the use of graph neural networks to those tasks learning on graphs with both node and edge features. These models can be regarded as extensions of graph attention networks (GATs). By reforming the model structure and the learning process, the new models can accept node and edge features as inputs, incorporate the edge information into feature representations, and iterate both node and edge features in a parallel but mutual way. The results demonstrate that our work is highly competitive against other node classification approaches, and can be well applied in edge-featured graph learning tasks.