 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxPrivacy: A Benchmark for Evaluating Interactional Privacy of Speech Language Models
Jan 27, 2026As Speech Language Models (SLMs) transition from personal devices to shared, multi-user environments such as smart homes, a new challenge emerges: the model is expected to distinguish between users to manage information flow appropriately. Without this capability, an SLM could reveal one user's confidential schedule to another, a privacy failure we term interactional privacy. Thus, the ability to generate speaker-aware responses becomes essential for SLM safe deployment. Current SLM benchmarks test dialogue ability but overlook speaker identity. Multi-speaker benchmarks check who said what without assessing whether SLMs adapt their responses. Privacy benchmarks focus on globally sensitive data (e.g., bank passwords) while neglecting contextual privacy-sensitive information (e.g., a user's private appointment). To address this gap, we introduce VoxPrivacy, the first benchmark designed to evaluate interactional privacy in SLMs. VoxPrivacy spans three tiers of increasing difficulty, from following direct secrecy commands to proactively protecting privacy. Our evaluation of nine SLMs on a 32-hour bilingual dataset reveals a widespread vulnerability: most open-source models perform close to random chance (around 50% accuracy) on conditional privacy decisions, while even strong closed-source systems fall short on proactive privacy inference. We further validate these findings on Real-VoxPrivacy, a human-recorded subset, confirming that failures observed on synthetic data persist in real speech. Finally, we demonstrate a viable path forward: by fine-tuning on a new 4,000-hour training set, we improve privacy-preserving abilities while maintaining robustness. To support future work, we release the VoxPrivacy benchmark, the large-scale training set, and the fine-tuned model to foster the development of safer and more context-aware SLMs.
SpeechJudge: Towards Human-Level Judgment for Speech Naturalness
Nov 11, 2025

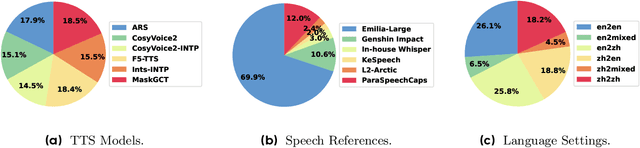
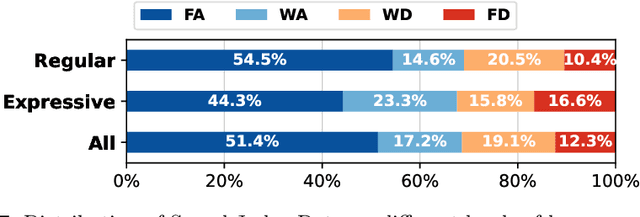
Aligning large generative models with human feedback is a critical challenge. In speech synthesis, this is particularly pronounced due to the lack of a large-scale human preference dataset, which hinders the development of models that truly align with human perception. To address this, we introduce SpeechJudge, a comprehensive suite comprising a dataset, a benchmark, and a reward model centered on naturalness--one of the most fundamental subjective metrics for speech synthesis. First, we present SpeechJudge-Data, a large-scale human feedback corpus of 99K speech pairs. The dataset is constructed using a diverse set of advanced zero-shot text-to-speech (TTS) models across diverse speech styles and multiple languages, with human annotations for both intelligibility and naturalness preference. From this, we establish SpeechJudge-Eval, a challenging benchmark for speech naturalness judgment. Our evaluation reveals that existing metrics and AudioLLMs struggle with this task; the leading model, Gemini-2.5-Flash, achieves less than 70% agreement with human judgment, highlighting a significant gap for improvement. To bridge this gap, we develop SpeechJudge-GRM, a generative reward model (GRM) based on Qwen2.5-Omni-7B. It is trained on SpeechJudge-Data via a two-stage post-training process: Supervised Fine-Tuning (SFT) with Chain-of-Thought rationales followed by Reinforcement Learning (RL) with GRPO on challenging cases. On the SpeechJudge-Eval benchmark, the proposed SpeechJudge-GRM demonstrates superior performance, achieving 77.2% accuracy (and 79.4% after inference-time scaling @10) compared to a classic Bradley-Terry reward model (72.7%). Furthermore, SpeechJudge-GRM can be also employed as a reward function during the post-training of speech generation models to facilitate their alignment with human preferences.
The Singing Voice Conversion Challenge 2025: From Singer Identity Conversion To Singing Style Conversion
Sep 19, 2025We present the findings of the latest iteration of the Singing Voice Conversion Challenge, a scientific event aiming to compare and understand different voice conversion systems in a controlled environment. Compared to previous iterations which solely focused on converting the singer identity, this year we also focused on converting the singing style of the singer. To create a controlled environment and thorough evaluations, we developed a new challenge database, introduced two tasks, open-sourced baselines, and conducted large-scale crowd-sourced listening tests and objective evaluations. The challenge was ran for two months and in total we evaluated 26 different systems. The results of the large-scale crowd-sourced listening test showed that top systems had comparable singer identity scores to ground truth samples. However, modeling the singing style and consequently achieving high naturalness still remains a challenge in this task, primarily due to the difficulty in modeling dynamic information in breathy, glissando, and vibrato singing styles.
AnyAccomp: Generalizable Accompaniment Generation via Quantized Melodic Bottleneck
Sep 17, 2025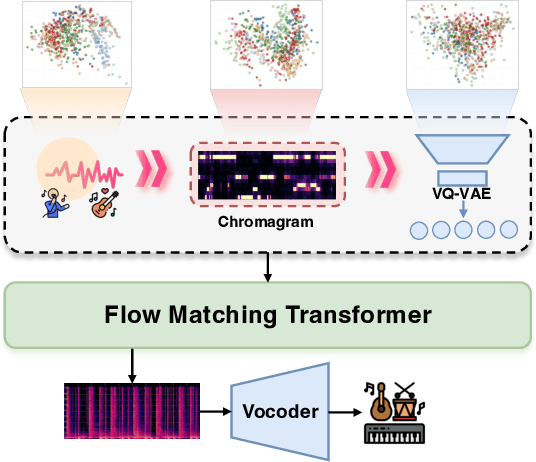
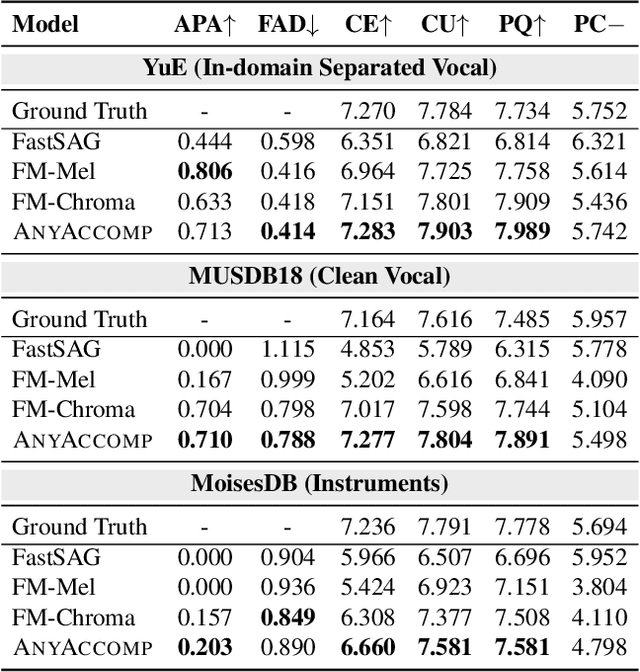
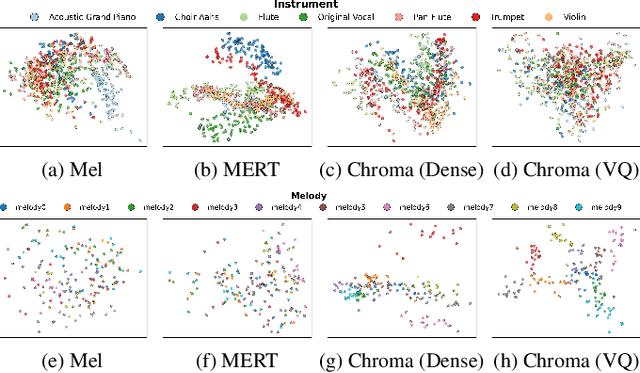
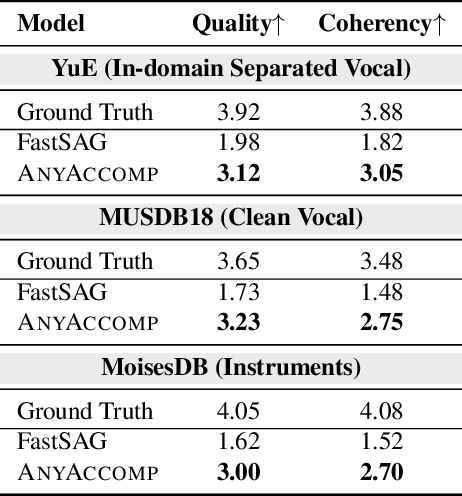
Singing Accompaniment Generation (SAG) is the process of generating instrumental music for a given clean vocal input. However, existing SAG techniques use source-separated vocals as input and overfit to separation artifacts. This creates a critical train-test mismatch, leading to failure on clean, real-world vocal inputs. We introduce AnyAccomp, a framework that resolves this by decoupling accompaniment generation from source-dependent artifacts. AnyAccomp first employs a quantized melodic bottleneck, using a chromagram and a VQ-VAE to extract a discrete and timbre-invariant representation of the core melody. A subsequent flow-matching model then generates the accompaniment conditioned on these robust codes. Experiments show AnyAccomp achieves competitive performance on separated-vocal benchmarks while significantly outperforming baselines on generalization test sets of clean studio vocals and, notably, solo instrumental tracks. This demonstrates a qualitative leap in generalization, enabling robust accompaniment for instruments - a task where existing models completely fail - and paving the way for more versatile music co-creation tools. Demo audio and code: https://anyaccomp.github.io
Audio Deepfake Verification
Sep 10, 2025With the rapid development of deepfake technology, simply making a binary judgment of true or false on audio is no longer sufficient to meet practical needs. Accurately determining the specific deepfake method has become crucial. This paper introduces the Audio Deepfake Verification (ADV) task, effectively addressing the limitations of existing deepfake source tracing methods in closed-set scenarios, aiming to achieve open-set deepfake source tracing. Meanwhile, the Audity dual-branch architecture is proposed, extracting deepfake features from two dimensions: audio structure and generation artifacts. Experimental results show that the dual-branch Audity architecture outperforms any single-branch configuration, and it can simultaneously achieve excellent performance in both deepfake detection and verification tasks.
Multi-Metric Preference Alignment for Generative Speech Restoration
Aug 24, 2025Recent generative models have significantly advanced speech restoration tasks, yet their training objectives often misalign with human perceptual preferences, resulting in suboptimal quality. While post-training alignment has proven effective in other generative domains like text and image generation, its application to generative speech restoration remains largely under-explored. This work investigates the challenges of applying preference-based post-training to this task, focusing on how to define a robust preference signal and curate high-quality data to avoid reward hacking. To address these challenges, we propose a multi-metric preference alignment strategy. We construct a new dataset, GenSR-Pref, comprising 80K preference pairs, where each chosen sample is unanimously favored by a complementary suite of metrics covering perceptual quality, signal fidelity, content consistency, and timbre preservation. This principled approach ensures a holistic preference signal. Applying Direct Preference Optimization (DPO) with our dataset, we observe consistent and significant performance gains across three diverse generative paradigms: autoregressive models (AR), masked generative models (MGM), and flow-matching models (FM) on various restoration benchmarks, in both objective and subjective evaluations. Ablation studies confirm the superiority of our multi-metric strategy over single-metric approaches in mitigating reward hacking. Furthermore, we demonstrate that our aligned models can serve as powerful ''data annotators'', generating high-quality pseudo-labels to serve as a supervision signal for traditional discriminative models in data-scarce scenarios like singing voice restoration. Demo Page:https://gensr-pref.github.io
From Judgment to Interference: Early Stopping LLM Harmful Outputs via Streaming Content Monitoring
Jun 11, 2025Though safety alignment has been applied to most large language models (LLMs), LLM service providers generally deploy a subsequent moderation as the external safety guardrail in real-world products. Existing moderators mainly practice a conventional full detection, which determines the harmfulness based on the complete LLM output, causing high service latency. Recent works pay more attention to partial detection where moderators oversee the generation midway and early stop the output if harmfulness is detected, but they directly apply moderators trained with the full detection paradigm to incomplete outputs, introducing a training-inference gap that lowers the performance. In this paper, we explore how to form a data-and-model solution that natively supports partial detection. For the data, we construct FineHarm, a dataset consisting of 29K prompt-response pairs with fine-grained annotations to provide reasonable supervision for token-level training. Then, we propose the streaming content monitor, which is trained with dual supervision of response- and token-level labels and can follow the output stream of LLM to make a timely judgment of harmfulness. Experiments show that SCM gains 0.95+ in macro F1 score that is comparable to full detection, by only seeing the first 18% of tokens in responses on average. Moreover, the SCM can serve as a pseudo-harmfulness annotator for improving safety alignment and lead to a higher harmlessness score than DPO.
SingNet: Towards a Large-Scale, Diverse, and In-the-Wild Singing Voice Dataset
May 14, 2025The lack of a publicly-available large-scale and diverse dataset has long been a significant bottleneck for singing voice applications like Singing Voice Synthesis (SVS) and Singing Voice Conversion (SVC). To tackle this problem, we present SingNet, an extensive, diverse, and in-the-wild singing voice dataset. Specifically, we propose a data processing pipeline to extract ready-to-use training data from sample packs and songs on the internet, forming 3000 hours of singing voices in various languages and styles. Furthermore, to facilitate the use and demonstrate the effectiveness of SingNet, we pre-train and open-source various state-of-the-art (SOTA) models on Wav2vec2, BigVGAN, and NSF-HiFiGAN based on our collected singing voice data. We also conduct benchmark experiments on Automatic Lyric Transcription (ALT), Neural Vocoder, and Singing Voice Conversion (SVC). Audio demos are available at: https://singnet-dataset.github.io/.
Advancing Zero-shot Text-to-Speech Intelligibility across Diverse Domains via Preference Alignment
May 07, 2025Modern zero-shot text-to-speech (TTS) systems, despite using extensive pre-training, often struggle in challenging scenarios such as tongue twisters, repeated words, code-switching, and cross-lingual synthesis, leading to intelligibility issues. To address these limitations, this paper leverages preference alignment techniques, which enable targeted construction of out-of-pretraining-distribution data to enhance performance. We introduce a new dataset, named the Intelligibility Preference Speech Dataset (INTP), and extend the Direct Preference Optimization (DPO) framework to accommodate diverse TTS architectures. After INTP alignment, in addition to intelligibility, we observe overall improvements including naturalness, similarity, and audio quality for multiple TTS models across diverse domains. Based on that, we also verify the weak-to-strong generalization ability of INTP for more intelligible models such as CosyVoice 2 and Ints. Moreover, we showcase the potential for further improvements through iterative alignment based on Ints. Audio samples are available at https://intalign.github.io/.
Vevo: Controllable Zero-Shot Voice Imitation with Self-Supervised Disentanglement
Feb 11, 2025The imitation of voice, targeted on specific speech attributes such as timbre and speaking style, is crucial in speech generation. However, existing methods rely heavily on annotated data, and struggle with effectively disentangling timbre and style, leading to challenges in achieving controllable generation, especially in zero-shot scenarios. To address these issues, we propose Vevo, a versatile zero-shot voice imitation framework with controllable timbre and style. Vevo operates in two core stages: (1) Content-Style Modeling: Given either text or speech's content tokens as input, we utilize an autoregressive transformer to generate the content-style tokens, which is prompted by a style reference; (2) Acoustic Modeling: Given the content-style tokens as input, we employ a flow-matching transformer to produce acoustic representations, which is prompted by a timbre reference. To obtain the content and content-style tokens of speech, we design a fully self-supervised approach that progressively decouples the timbre, style, and linguistic content of speech. Specifically, we adopt VQ-VAE as the tokenizer for the continuous hidden features of HuBERT. We treat the vocabulary size of the VQ-VAE codebook as the information bottleneck, and adjust it carefully to obtain the disentangled speech representations. Solely self-supervised trained on 60K hours of audiobook speech data, without any fine-tuning on style-specific corpora, Vevo matches or surpasses existing methods in accent and emotion conversion tasks. Additionally, Vevo's effectiveness in zero-shot voice conversion and text-to-speech tasks further demonstrates its strong generalization and versatility. Audio samples are available at https://versavoice.github.io.