 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVevo: Controllable Zero-Shot Voice Imitation with Self-Supervised Disentanglement
Feb 11, 2025The imitation of voice, targeted on specific speech attributes such as timbre and speaking style, is crucial in speech generation. However, existing methods rely heavily on annotated data, and struggle with effectively disentangling timbre and style, leading to challenges in achieving controllable generation, especially in zero-shot scenarios. To address these issues, we propose Vevo, a versatile zero-shot voice imitation framework with controllable timbre and style. Vevo operates in two core stages: (1) Content-Style Modeling: Given either text or speech's content tokens as input, we utilize an autoregressive transformer to generate the content-style tokens, which is prompted by a style reference; (2) Acoustic Modeling: Given the content-style tokens as input, we employ a flow-matching transformer to produce acoustic representations, which is prompted by a timbre reference. To obtain the content and content-style tokens of speech, we design a fully self-supervised approach that progressively decouples the timbre, style, and linguistic content of speech. Specifically, we adopt VQ-VAE as the tokenizer for the continuous hidden features of HuBERT. We treat the vocabulary size of the VQ-VAE codebook as the information bottleneck, and adjust it carefully to obtain the disentangled speech representations. Solely self-supervised trained on 60K hours of audiobook speech data, without any fine-tuning on style-specific corpora, Vevo matches or surpasses existing methods in accent and emotion conversion tasks. Additionally, Vevo's effectiveness in zero-shot voice conversion and text-to-speech tasks further demonstrates its strong generalization and versatility. Audio samples are available at https://versavoice.github.io.
TorchAudio 2.1: Advancing speech recognition, self-supervised learning, and audio processing components for PyTorch
Oct 27, 2023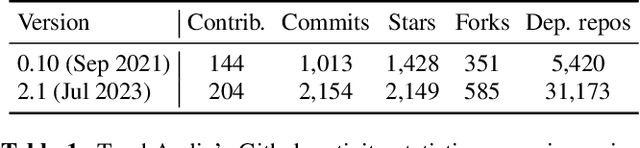


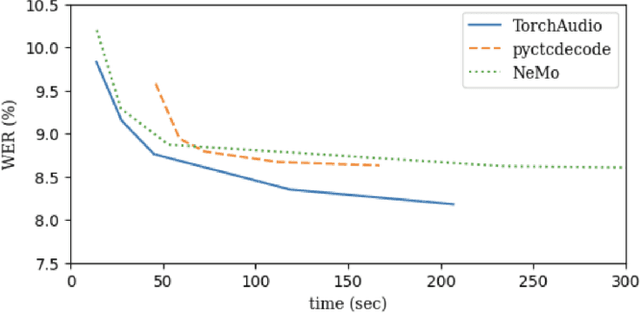
TorchAudio is an open-source audio and speech processing library built for PyTorch. It aims to accelerate the research and development of audio and speech technologies by providing well-designed, easy-to-use, and performant PyTorch components. Its contributors routinely engage with users to understand their needs and fulfill them by developing impactful features. Here, we survey TorchAudio's development principles and contents and highlight key features we include in its latest version (2.1): self-supervised learning pre-trained pipelines and training recipes, high-performance CTC decoders, speech recognition models and training recipes, advanced media I/O capabilities, and tools for performing forced alignment, multi-channel speech enhancement, and reference-less speech assessment. For a selection of these features, through empirical studies, we demonstrate their efficacy and show that they achieve competitive or state-of-the-art performance.
TorchAudio: Building Blocks for Audio and Speech Processing
Oct 28, 2021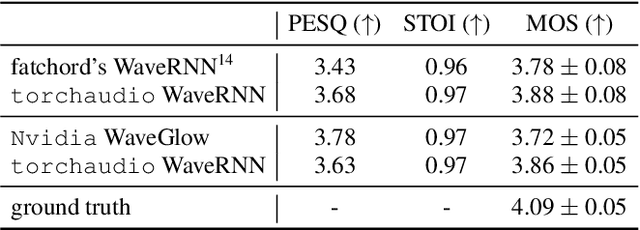
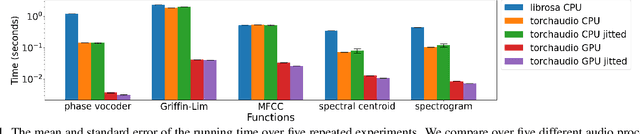


This document describes version 0.10 of torchaudio: building blocks for machine learning applications in the audio and speech processing domain. The objective of torchaudio is to accelerate the development and deployment of machine learning applications for researchers and engineers by providing off-the-shelf building blocks. The building blocks are designed to be GPU-compatible, automatically differentiable, and production-ready. torchaudio can be easily installed from Python Package Index repository and the source code is publicly available under a BSD-2-Clause License (as of September 2021) at https://github.com/pytorch/audio. In this document, we provide an overview of the design principles, functionalities, and benchmarks of torchaudio. We also benchmark our implementation of several audio and speech operations and models. We verify through the benchmarks that our implementations of various operations and models are valid and perform similarly to other publicly available implementations.