 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT-Mimi: A Transformer-based Mimi Decoder for Real-Time On-Phone TTS
Jan 27, 2026Neural audio codecs provide promising acoustic features for speech synthesis, with representative streaming codecs like Mimi providing high-quality acoustic features for real-time Text-to-Speech (TTS) applications. However, Mimi's decoder, which employs a hybrid transformer and convolution architecture, introduces significant latency bottlenecks on edge devices due to the the compute intensive nature of deconvolution layers which are not friendly for mobile-CPUs, such as the most representative framework XNNPACK. This paper introduces T-Mimi, a novel modification of the Mimi codec decoder that replaces its convolutional components with a purely transformer-based decoder, inspired by the TS3-Codec architecture. This change dramatically reduces on-device TTS latency from 42.1ms to just 4.4ms. Furthermore, we conduct quantization aware training and derive a crucial finding: the final two transformer layers and the concluding linear layers of the decoder, which are close to the waveform, are highly sensitive to quantization and must be preserved at full precision to maintain audio quality.
Vevo: Controllable Zero-Shot Voice Imitation with Self-Supervised Disentanglement
Feb 11, 2025The imitation of voice, targeted on specific speech attributes such as timbre and speaking style, is crucial in speech generation. However, existing methods rely heavily on annotated data, and struggle with effectively disentangling timbre and style, leading to challenges in achieving controllable generation, especially in zero-shot scenarios. To address these issues, we propose Vevo, a versatile zero-shot voice imitation framework with controllable timbre and style. Vevo operates in two core stages: (1) Content-Style Modeling: Given either text or speech's content tokens as input, we utilize an autoregressive transformer to generate the content-style tokens, which is prompted by a style reference; (2) Acoustic Modeling: Given the content-style tokens as input, we employ a flow-matching transformer to produce acoustic representations, which is prompted by a timbre reference. To obtain the content and content-style tokens of speech, we design a fully self-supervised approach that progressively decouples the timbre, style, and linguistic content of speech. Specifically, we adopt VQ-VAE as the tokenizer for the continuous hidden features of HuBERT. We treat the vocabulary size of the VQ-VAE codebook as the information bottleneck, and adjust it carefully to obtain the disentangled speech representations. Solely self-supervised trained on 60K hours of audiobook speech data, without any fine-tuning on style-specific corpora, Vevo matches or surpasses existing methods in accent and emotion conversion tasks. Additionally, Vevo's effectiveness in zero-shot voice conversion and text-to-speech tasks further demonstrates its strong generalization and versatility. Audio samples are available at https://versavoice.github.io.
On lattice-free boosted MMI training of HMM and CTC-based full-context ASR models
Jul 09, 2021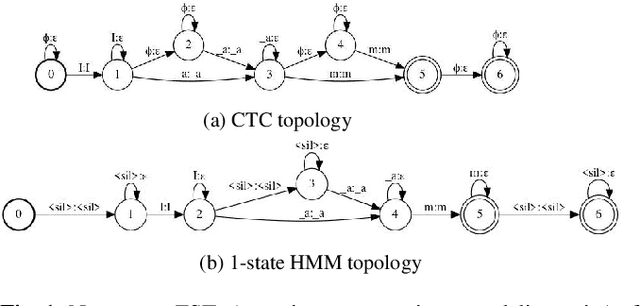
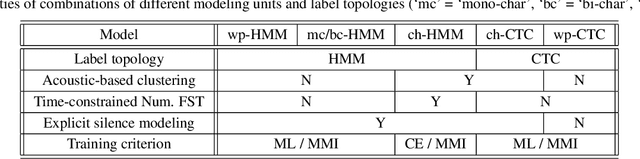
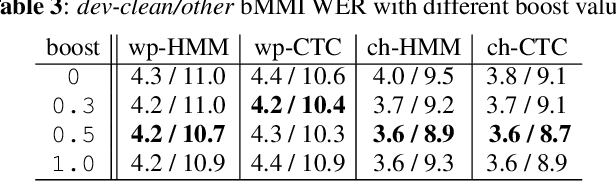
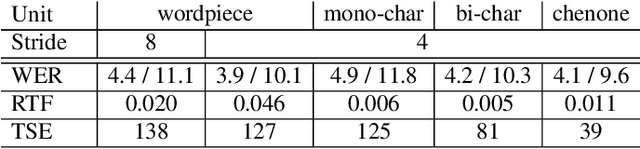
Hybrid automatic speech recognition (ASR) models are typically sequentially trained with CTC or LF-MMI criteria. However, they have vastly different legacies and are usually implemented in different frameworks. In this paper, by decoupling the concepts of modeling units and label topologies and building proper numerator/denominator graphs accordingly, we establish a generalized framework for hybrid acoustic modeling (AM). In this framework, we show that LF-MMI is a powerful training criterion applicable to both limited-context and full-context models, for wordpiece/mono-char/bi-char/chenone units, with both HMM/CTC topologies. From this framework, we propose three novel training schemes: chenone(ch)/wordpiece(wp)-CTC-bMMI, and wordpiece(wp)-HMM-bMMI with different advantages in training performance, decoding efficiency and decoding time-stamp accuracy. The advantages of different training schemes are evaluated comprehensively on Librispeech, and wp-CTC-bMMI and ch-CTC-bMMI are evaluated on two real world ASR tasks to show their effectiveness. Besides, we also show bi-char(bc) HMM-MMI models can serve as better alignment models than traditional non-neural GMM-HMMs.
Contextualized Streaming End-to-End Speech Recognition with Trie-Based Deep Biasing and Shallow Fusion
Apr 05, 2021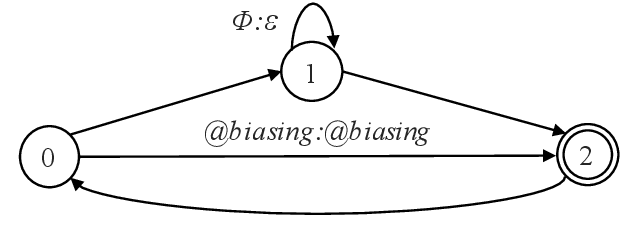
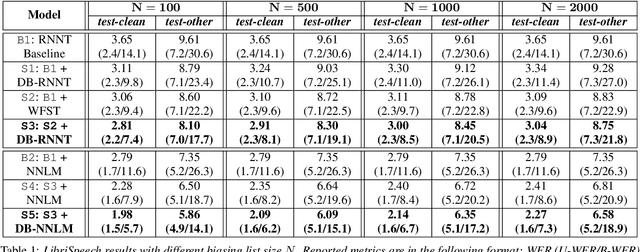
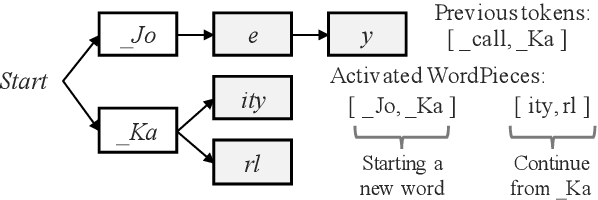
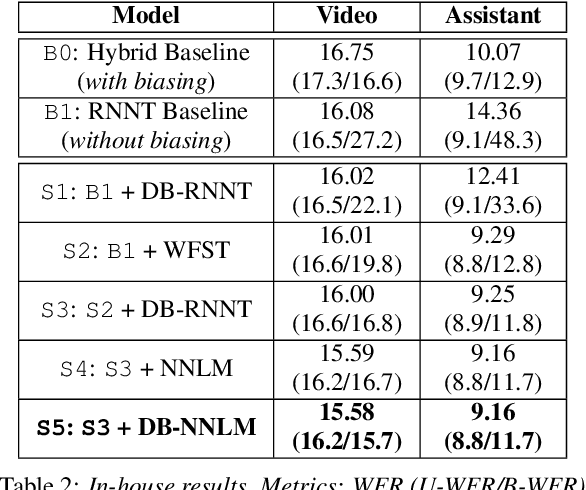
How to leverage dynamic contextual information in end-to-end speech recognition has remained an active research area. Previous solutions to this problem were either designed for specialized use cases that did not generalize well to open-domain scenarios, did not scale to large biasing lists, or underperformed on rare long-tail words. We address these limitations by proposing a novel solution that combines shallow fusion, trie-based deep biasing, and neural network language model contextualization. These techniques result in significant 19.5% relative Word Error Rate improvement over existing contextual biasing approaches and 5.4%-9.3% improvement compared to a strong hybrid baseline on both open-domain and constrained contextualization tasks, where the targets consist of mostly rare long-tail words. Our final system remains lightweight and modular, allowing for quick modification without model re-training.
Dynamic Encoder Transducer: A Flexible Solution For Trading Off Accuracy For Latency
Apr 05, 2021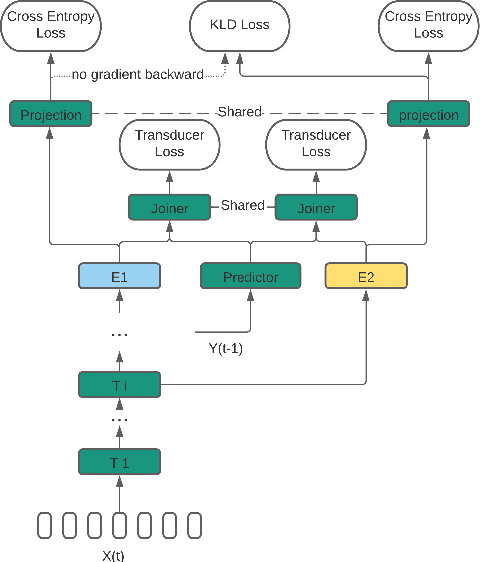
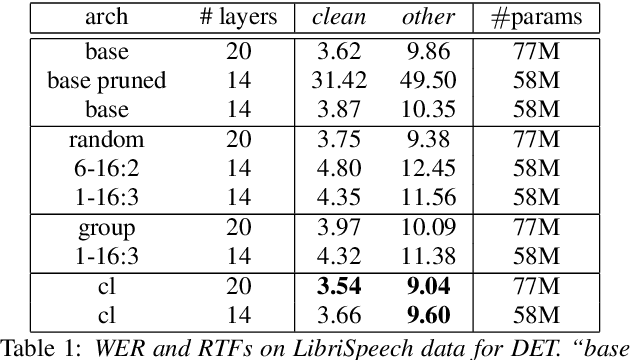
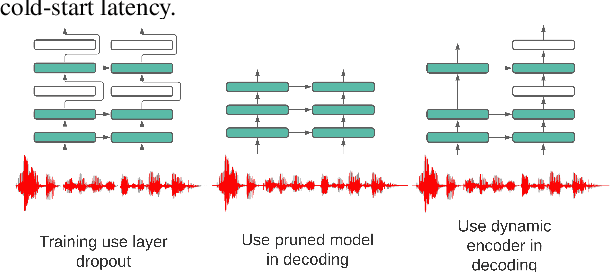
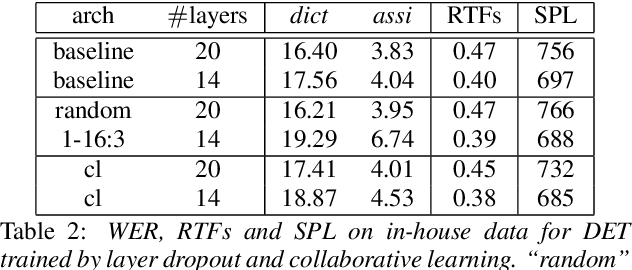
We propose a dynamic encoder transducer (DET) for on-device speech recognition. One DET model scales to multiple devices with different computation capacities without retraining or finetuning. To trading off accuracy and latency, DET assigns different encoders to decode different parts of an utterance. We apply and compare the layer dropout and the collaborative learning for DET training. The layer dropout method that randomly drops out encoder layers in the training phase, can do on-demand layer dropout in decoding. Collaborative learning jointly trains multiple encoders with different depths in one single model. Experiment results on Librispeech and in-house data show that DET provides a flexible accuracy and latency trade-off. Results on Librispeech show that the full-size encoder in DET relatively reduces the word error rate of the same size baseline by over 8%. The lightweight encoder in DET trained with collaborative learning reduces the model size by 25% but still gets similar WER as the full-size baseline. DET gets similar accuracy as a baseline model with better latency on a large in-house data set by assigning a lightweight encoder for the beginning part of one utterance and a full-size encoder for the rest.
Deep Shallow Fusion for RNN-T Personalization
Nov 16, 2020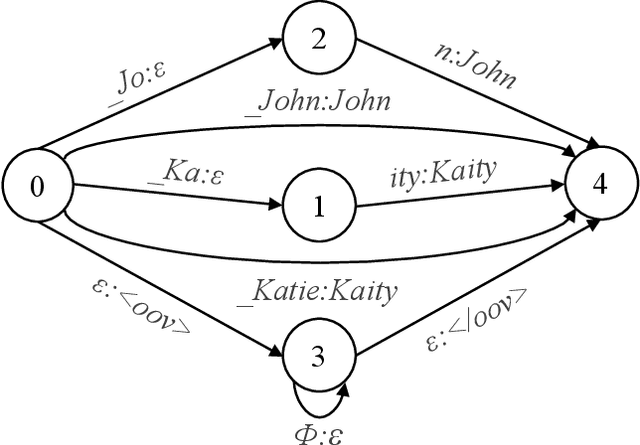
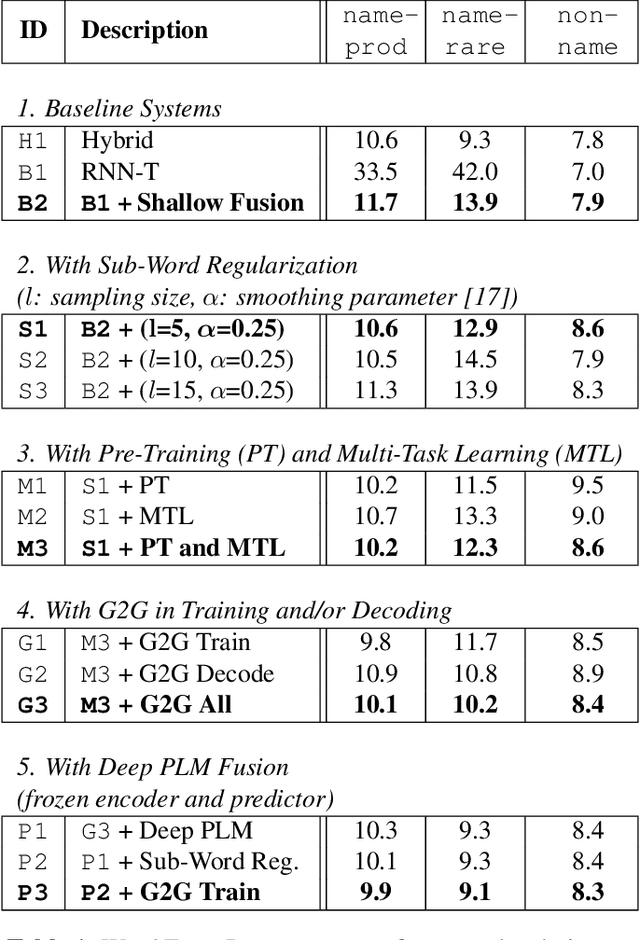
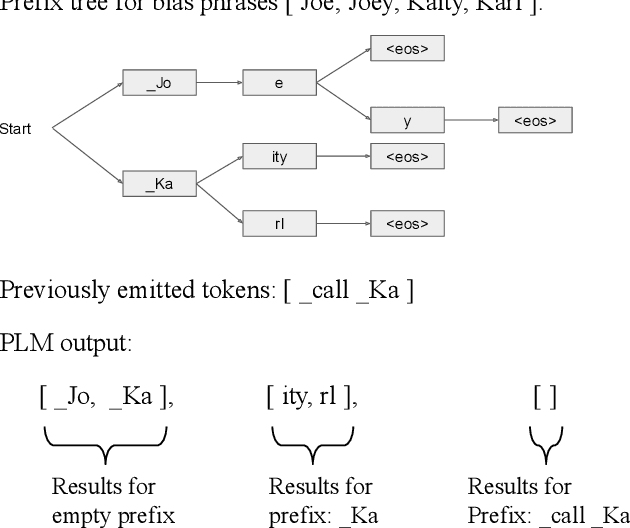
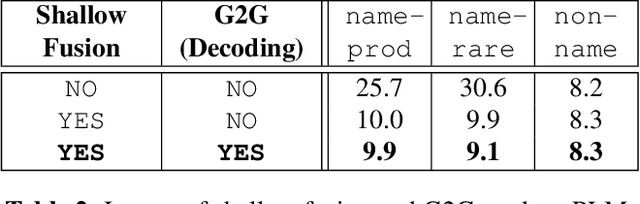
End-to-end models in general, and Recurrent Neural Network Transducer (RNN-T) in particular, have gained significant traction in the automatic speech recognition community in the last few years due to their simplicity, compactness, and excellent performance on generic transcription tasks. However, these models are more challenging to personalize compared to traditional hybrid systems due to the lack of external language models and difficulties in recognizing rare long-tail words, specifically entity names. In this work, we present novel techniques to improve RNN-T's ability to model rare WordPieces, infuse extra information into the encoder, enable the use of alternative graphemic pronunciations, and perform deep fusion with personalized language models for more robust biasing. We show that these combined techniques result in 15.4%-34.5% relative Word Error Rate improvement compared to a strong RNN-T baseline which uses shallow fusion and text-to-speech augmentation. Our work helps push the boundary of RNN-T personalization and close the gap with hybrid systems on use cases where biasing and entity recognition are crucial.
Streaming Attention-Based Models with Augmented Memory for End-to-End Speech Recognition
Nov 03, 2020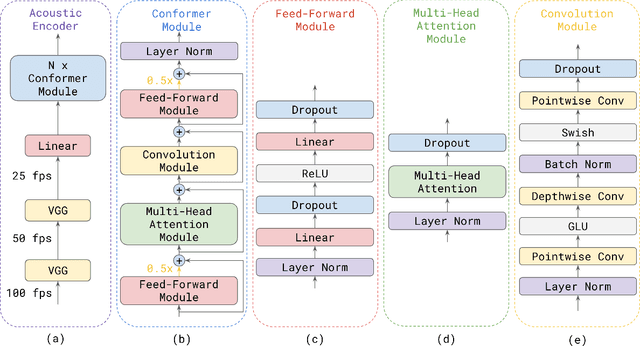
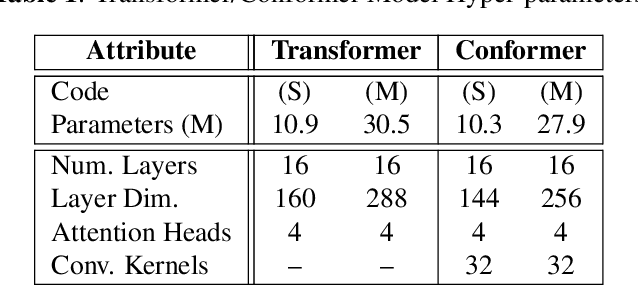
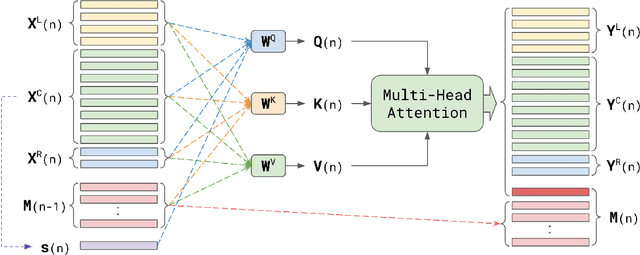
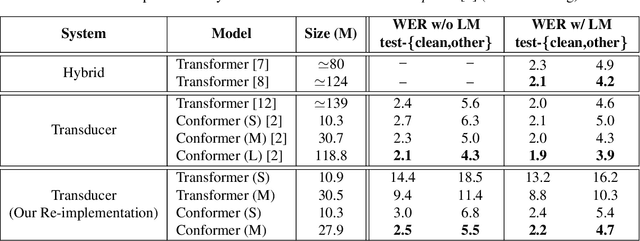
Attention-based models have been gaining popularity recently for their strong performance demonstrated in fields such as machine translation and automatic speech recognition. One major challenge of attention-based models is the need of access to the full sequence and the quadratically growing computational cost concerning the sequence length. These characteristics pose challenges, especially for low-latency scenarios, where the system is often required to be streaming. In this paper, we build a compact and streaming speech recognition system on top of the end-to-end neural transducer architecture with attention-based modules augmented with convolution. The proposed system equips the end-to-end models with the streaming capability and reduces the large footprint from the streaming attention-based model using augmented memory. On the LibriSpeech dataset, our proposed system achieves word error rates 2.7% on test-clean and 5.8% on test-other, to our best knowledge the lowest among streaming approaches reported so far.
Transformer in action: a comparative study of transformer-based acoustic models for large scale speech recognition applications
Oct 29, 2020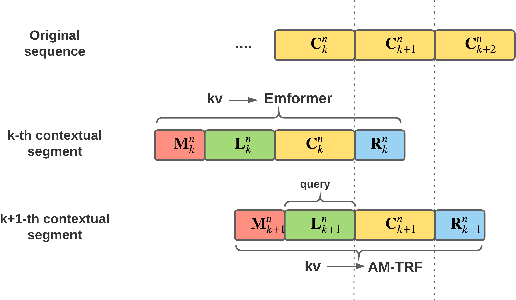
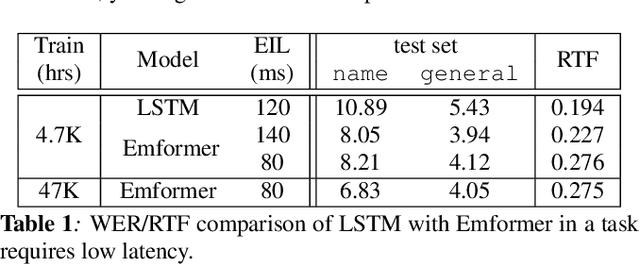
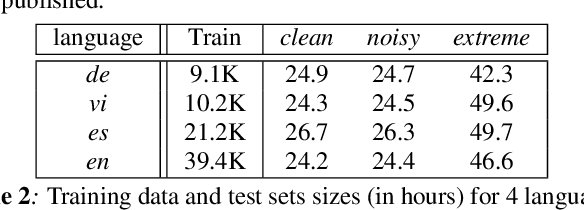
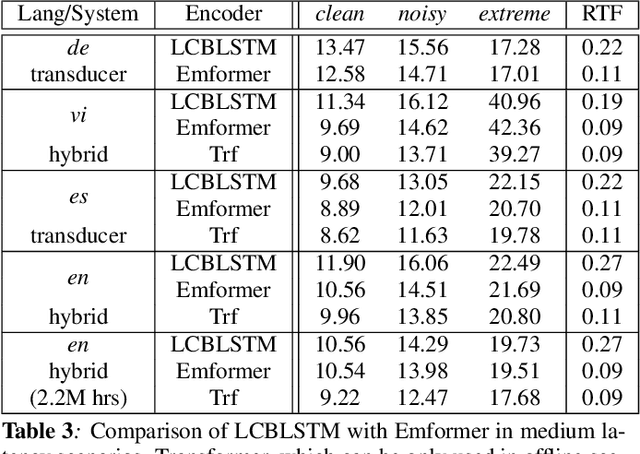
In this paper, we summarize the application of transformer and its streamable variant, Emformer based acoustic model for large scale speech recognition applications. We compare the transformer based acoustic models with their LSTM counterparts on industrial scale tasks. Specifically, we compare Emformer with latency-controlled BLSTM (LCBLSTM) on medium latency tasks and LSTM on low latency tasks. On a low latency voice assistant task, Emformer gets 24% to 26% relative word error rate reductions (WERRs). For medium latency scenarios, comparing with LCBLSTM with similar model size and latency, Emformer gets significant WERR across four languages in video captioning datasets with 2-3 times inference real-time factors reduction.
Emformer: Efficient Memory Transformer Based Acoustic Model For Low Latency Streaming Speech Recognition
Oct 29, 2020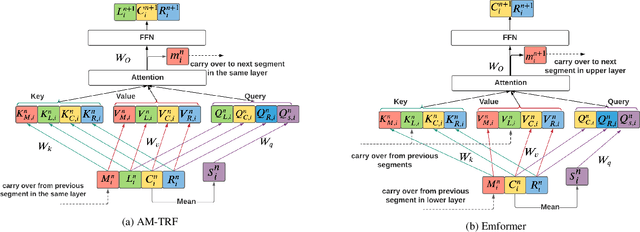
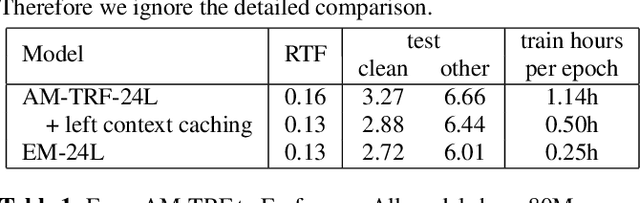
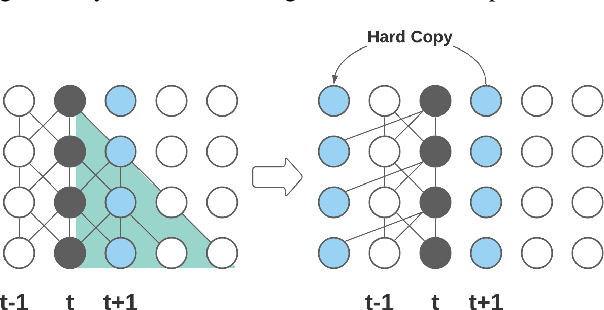
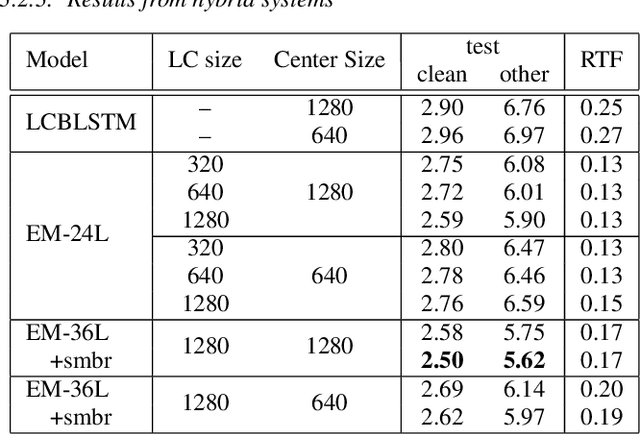
This paper proposes an efficient memory transformer Emformer for low latency streaming speech recognition. In Emformer, the long-range history context is distilled into an augmented memory bank to reduce self-attention's computation complexity. A cache mechanism saves the computation for the key and value in self-attention for the left context. Emformer applies a parallelized block processing in training to support low latency models. We carry out experiments on benchmark LibriSpeech data. Under average latency of 960 ms, Emformer gets WER $2.50\%$ on test-clean and $5.62\%$ on test-other. Comparing with a strong baseline augmented memory transformer (AM-TRF), Emformer gets $4.6$ folds training speedup and $18\%$ relative real-time factor (RTF) reduction in decoding with relative WER reduction $17\%$ on test-clean and $9\%$ on test-other. For a low latency scenario with an average latency of 80 ms, Emformer achieves WER $3.01\%$ on test-clean and $7.09\%$ on test-other. Comparing with the LSTM baseline with the same latency and model size, Emformer gets relative WER reduction $9\%$ and $16\%$ on test-clean and test-other, respectively.
Just ASK: Building an Architecture for Extensible Self-Service Spoken Language Understanding
Mar 02, 2018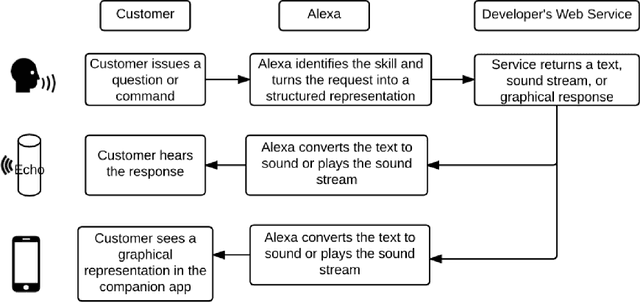
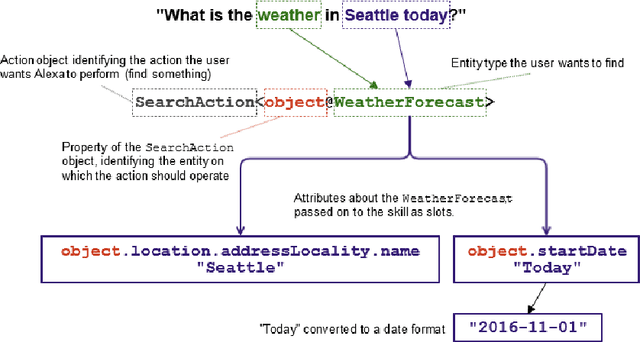
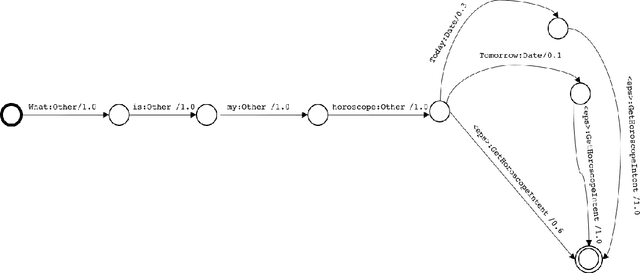
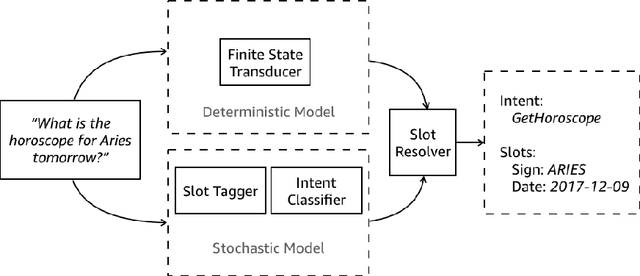
This paper presents the design of the machine learning architecture that underlies the Alexa Skills Kit (ASK) a large scale Spoken Language Understanding (SLU) Software Development Kit (SDK) that enables developers to extend the capabilities of Amazon's virtual assistant, Alexa. At Amazon, the infrastructure powers over 25,000 skills deployed through the ASK, as well as AWS's Amazon Lex SLU Service. The ASK emphasizes flexibility, predictability and a rapid iteration cycle for third party developers. It imposes inductive biases that allow it to learn robust SLU models from extremely small and sparse datasets and, in doing so, removes significant barriers to entry for software developers and dialogue systems researchers.