 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeATLAS: Actor-Critic Task-Completion with Look-ahead Action Simulation
Oct 26, 2025We observe that current state-of-the-art web-agents are unable to effectively adapt to new environments without neural network fine-tuning, without which they produce inefficient execution plans due to a lack of awareness of the structure and dynamics of the new environment. To address this limitation, we introduce ATLAS (Actor-Critic Task-completion with Look-ahead Action Simulation), a memory-augmented agent that is able to make plans grounded in a model of the environment by simulating the consequences of those actions in cognitive space. Our agent starts by building a "cognitive map" by performing a lightweight curiosity driven exploration of the environment. The planner proposes candidate actions; the simulator predicts their consequences in cognitive space; a critic analyzes the options to select the best roll-out and update the original plan; and a browser executor performs the chosen action. On the WebArena-Lite Benchmark, we achieve a 63% success rate compared to 53.9% success rate for the previously published state-of-the-art. Unlike previous systems, our modular architecture requires no website-specific LLM fine-tuning. Ablations show sizable drops without the world-model, hierarchical planner, and look-ahead-based replanner confirming their complementary roles within the design of our system
Learning to Retrieve Engaging Follow-Up Queries
Feb 21, 2023



Open domain conversational agents can answer a broad range of targeted queries. However, the sequential nature of interaction with these systems makes knowledge exploration a lengthy task which burdens the user with asking a chain of well phrased questions. In this paper, we present a retrieval based system and associated dataset for predicting the next questions that the user might have. Such a system can proactively assist users in knowledge exploration leading to a more engaging dialog. The retrieval system is trained on a dataset which contains ~14K multi-turn information-seeking conversations with a valid follow-up question and a set of invalid candidates. The invalid candidates are generated to simulate various syntactic and semantic confounders such as paraphrases, partial entity match, irrelevant entity, and ASR errors. We use confounder specific techniques to simulate these negative examples on the OR-QuAC dataset and develop a dataset called the Follow-up Query Bank (FQ-Bank). Then, we train ranking models on FQ-Bank and present results comparing supervised and unsupervised approaches. The results suggest that we can retrieve the valid follow-ups by ranking them in higher positions compared to confounders, but further knowledge grounding can improve ranking performance.
Large Scale Question Paraphrase Retrieval with Smoothed Deep Metric Learning
May 29, 2019
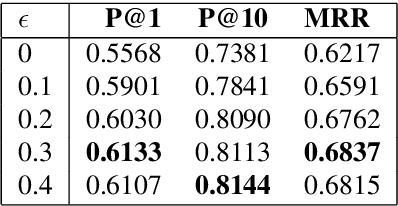
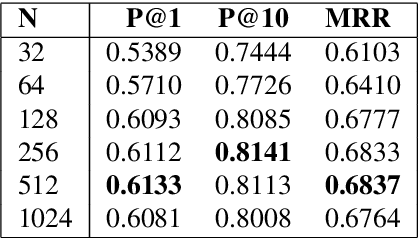
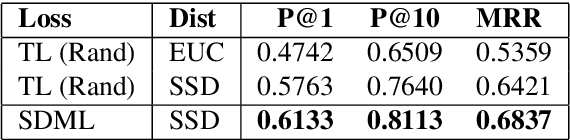
The goal of a Question Paraphrase Retrieval (QPR) system is to retrieve equivalent questions that result in the same answer as the original question. Such a system can be used to understand and answer rare and noisy reformulations of common questions by mapping them to a set of canonical forms. This has large-scale applications for community Question Answering (cQA) and open-domain spoken language question answering systems. In this paper we describe a new QPR system implemented as a Neural Information Retrieval (NIR) system consisting of a neural network sentence encoder and an approximate k-Nearest Neighbour index for efficient vector retrieval. We also describe our mechanism to generate an annotated dataset for question paraphrase retrieval experiments automatically from question-answer logs via distant supervision. We show that the standard loss function in NIR, triplet loss, does not perform well with noisy labels. We propose smoothed deep metric loss (SDML) and with our experiments on two QPR datasets we show that it significantly outperforms triplet loss in the noisy label setting.
Learning When Not to Answer: A Ternary Reward Structure for Reinforcement Learning based Question Answering
Apr 03, 2019



In this paper, we investigate the challenges of using reinforcement learning agents for question-answering over knowledge graphs for real-world applications. We examine the performance metrics used by state-of-the-art systems and determine that they are inadequate for such settings. More specifically, they do not evaluate the systems correctly for situations when there is no answer available and thus agents optimized for these metrics are poor at modeling confidence. We introduce a simple new performance metric for evaluating question-answering agents that is more representative of practical usage conditions, and optimize for this metric by extending the binary reward structure used in prior work to a ternary reward structure which also rewards an agent for not answering a question rather than giving an incorrect answer. We show that this can drastically improve the precision of answered questions while only not answering a limited number of previously correctly answered questions. Employing a supervised learning strategy using depth-first-search paths to bootstrap the reinforcement learning algorithm further improves performance.
Efficient Large-Scale Domain Classification with Personalized Attention
Apr 22, 2018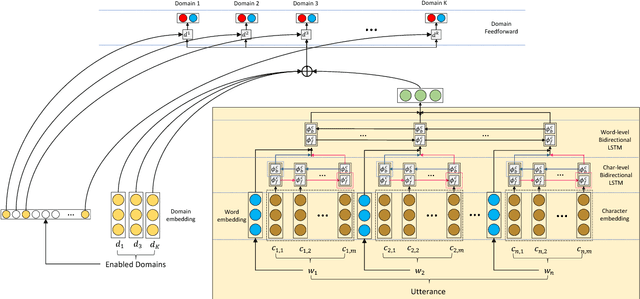
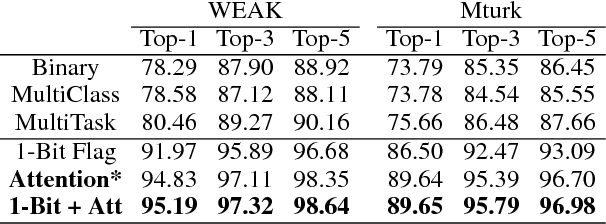
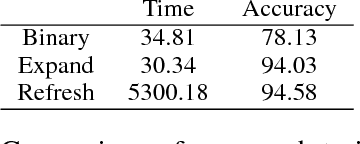
In this paper, we explore the task of mapping spoken language utterances to one of thousands of natural language understanding domains in intelligent personal digital assistants (IPDAs). This scenario is observed for many mainstream IPDAs in industry that allow third parties to develop thousands of new domains to augment built-in ones to rapidly increase domain coverage and overall IPDA capabilities. We propose a scalable neural model architecture with a shared encoder, a novel attention mechanism that incorporates personalization information and domain-specific classifiers that solves the problem efficiently. Our architecture is designed to efficiently accommodate new domains that appear in-between full model retraining cycles with a rapid bootstrapping mechanism two orders of magnitude faster than retraining. We account for practical constraints in real-time production systems, and design to minimize memory footprint and runtime latency. We demonstrate that incorporating personalization results in significantly more accurate domain classification in the setting with thousands of overlapping domains.
Just ASK: Building an Architecture for Extensible Self-Service Spoken Language Understanding
Mar 02, 2018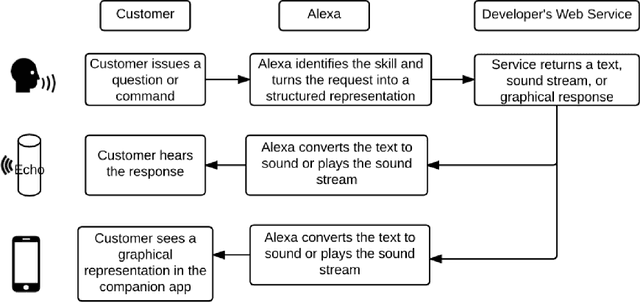
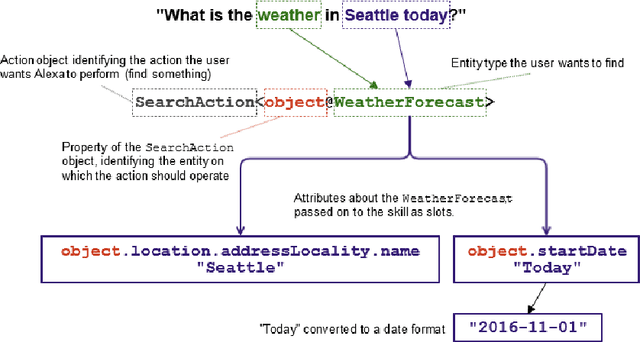
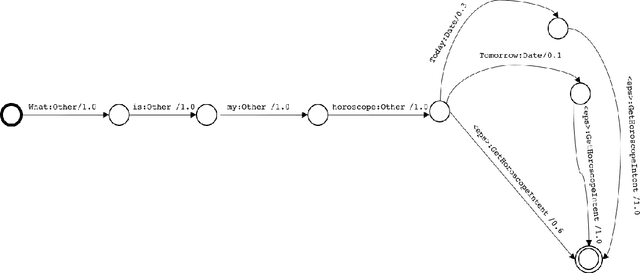
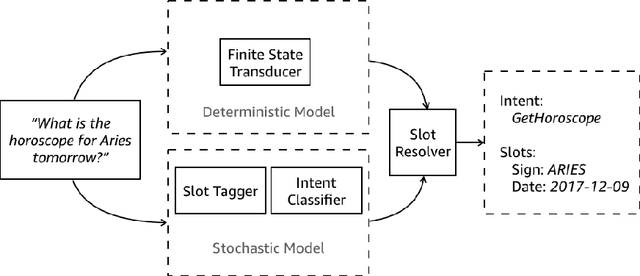
This paper presents the design of the machine learning architecture that underlies the Alexa Skills Kit (ASK) a large scale Spoken Language Understanding (SLU) Software Development Kit (SDK) that enables developers to extend the capabilities of Amazon's virtual assistant, Alexa. At Amazon, the infrastructure powers over 25,000 skills deployed through the ASK, as well as AWS's Amazon Lex SLU Service. The ASK emphasizes flexibility, predictability and a rapid iteration cycle for third party developers. It imposes inductive biases that allow it to learn robust SLU models from extremely small and sparse datasets and, in doing so, removes significant barriers to entry for software developers and dialogue systems researchers.