 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Distillation with Training Wheels
Feb 24, 2025Knowledge distillation is used, in generative language modeling, to train a smaller student model using the help of a larger teacher model, resulting in improved capabilities for the student model. In this paper, we formulate a more general framework for knowledge distillation where the student learns from the teacher during training, and also learns to ask for the teacher's help at test-time following rules specifying test-time restrictions. Towards this, we first formulate knowledge distillation as an entropy-regularized value optimization problem. Adopting Path Consistency Learning to solve this, leads to a new knowledge distillation algorithm using on-policy and off-policy demonstrations. We extend this using constrained reinforcement learning to a framework that incorporates the use of the teacher model as a test-time reference, within constraints. In this situation, akin to a human learner, the model needs to learn not only the learning material, but also the relative difficulty of different sections to prioritize for seeking teacher help. We examine the efficacy of our method through experiments in translation and summarization tasks, observing trends in accuracy and teacher use, noting that our approach unlocks operating points not available to the popular Speculative Decoding approach.
Chain-of-Instructions: Compositional Instruction Tuning on Large Language Models
Feb 18, 2024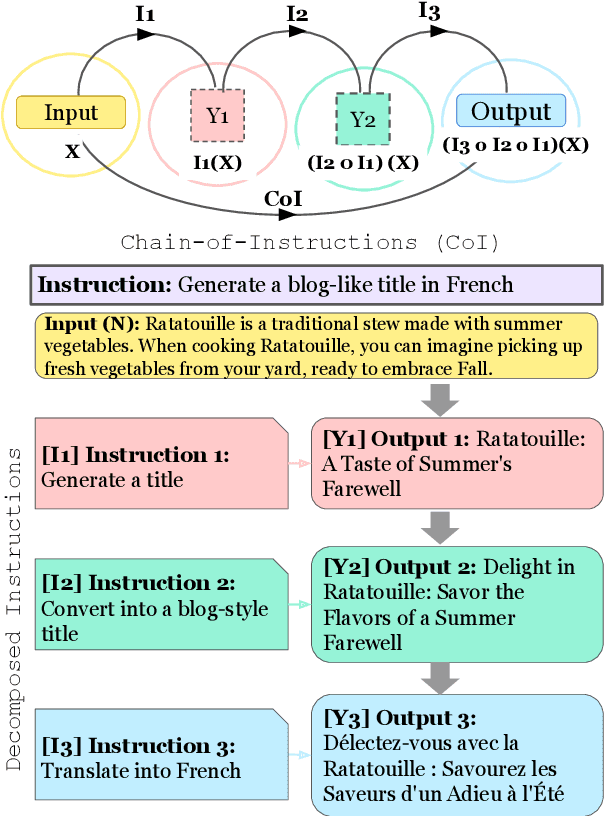
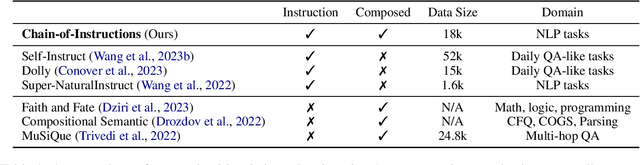

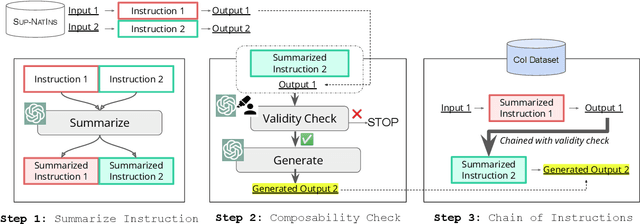
Fine-tuning large language models (LLMs) with a collection of large and diverse instructions has improved the model's generalization to different tasks, even for unseen tasks. However, most existing instruction datasets include only single instructions, and they struggle to follow complex instructions composed of multiple subtasks (Wang et al., 2023a). In this work, we propose a novel concept of compositional instructions called chain-of-instructions (CoI), where the output of one instruction becomes an input for the next like a chain. Unlike the conventional practice of solving single instruction tasks, our proposed method encourages a model to solve each subtask step by step until the final answer is reached. CoI-tuning (i.e., fine-tuning with CoI instructions) improves the model's ability to handle instructions composed of multiple subtasks. CoI-tuned models also outperformed baseline models on multilingual summarization, demonstrating the generalizability of CoI models on unseen composite downstream tasks.
Integrating Summarization and Retrieval for Enhanced Personalization via Large Language Models
Oct 30, 2023



Personalization, the ability to tailor a system to individual users, is an essential factor in user experience with natural language processing (NLP) systems. With the emergence of Large Language Models (LLMs), a key question is how to leverage these models to better personalize user experiences. To personalize a language model's output, a straightforward approach is to incorporate past user data into the language model prompt, but this approach can result in lengthy inputs exceeding limitations on input length and incurring latency and cost issues. Existing approaches tackle such challenges by selectively extracting relevant user data (i.e. selective retrieval) to construct a prompt for downstream tasks. However, retrieval-based methods are limited by potential information loss, lack of more profound user understanding, and cold-start challenges. To overcome these limitations, we propose a novel summary-augmented approach by extending retrieval-augmented personalization with task-aware user summaries generated by LLMs. The summaries can be generated and stored offline, enabling real-world systems with runtime constraints like voice assistants to leverage the power of LLMs. Experiments show our method with 75% less of retrieved user data is on-par or outperforms retrieval augmentation on most tasks in the LaMP personalization benchmark. We demonstrate that offline summarization via LLMs and runtime retrieval enables better performance for personalization on a range of tasks under practical constraints.
Learning to Retrieve Engaging Follow-Up Queries
Feb 21, 2023



Open domain conversational agents can answer a broad range of targeted queries. However, the sequential nature of interaction with these systems makes knowledge exploration a lengthy task which burdens the user with asking a chain of well phrased questions. In this paper, we present a retrieval based system and associated dataset for predicting the next questions that the user might have. Such a system can proactively assist users in knowledge exploration leading to a more engaging dialog. The retrieval system is trained on a dataset which contains ~14K multi-turn information-seeking conversations with a valid follow-up question and a set of invalid candidates. The invalid candidates are generated to simulate various syntactic and semantic confounders such as paraphrases, partial entity match, irrelevant entity, and ASR errors. We use confounder specific techniques to simulate these negative examples on the OR-QuAC dataset and develop a dataset called the Follow-up Query Bank (FQ-Bank). Then, we train ranking models on FQ-Bank and present results comparing supervised and unsupervised approaches. The results suggest that we can retrieve the valid follow-ups by ranking them in higher positions compared to confounders, but further knowledge grounding can improve ranking performance.
Improving Device Directedness Classification of Utterances with Semantic Lexical Features
Sep 29, 2020
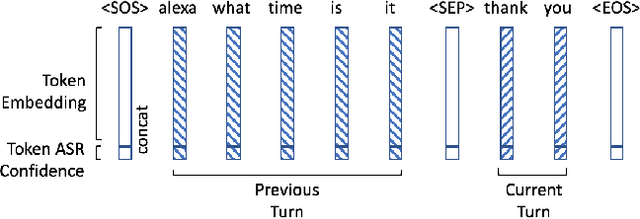

User interactions with personal assistants like Alexa, Google Home and Siri are typically initiated by a wake term or wakeword. Several personal assistants feature "follow-up" modes that allow users to make additional interactions without the need of a wakeword. For the system to only respond when appropriate, and to ignore speech not intended for it, utterances must be classified as device-directed or non-device-directed. State-of-the-art systems have largely used acoustic features for this task, while others have used only lexical features or have added LM-based lexical features. We propose a directedness classifier that combines semantic lexical features with a lightweight acoustic feature and show it is effective in classifying directedness. The mixed-domain lexical and acoustic feature model is able to achieve 14% relative reduction of EER over a state-of-the-art acoustic-only baseline model. Finally, we successfully apply transfer learning and semi-supervised learning to the model to improve accuracy even further.
* Accepted and Published at ICASSP 2020
Label Dependent Deep Variational Paraphrase Generation
Nov 27, 2019
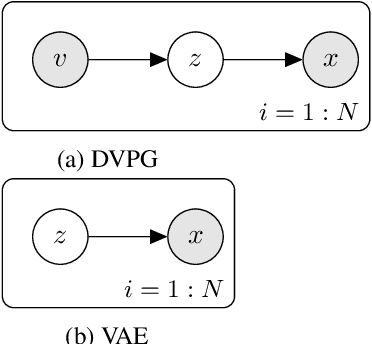
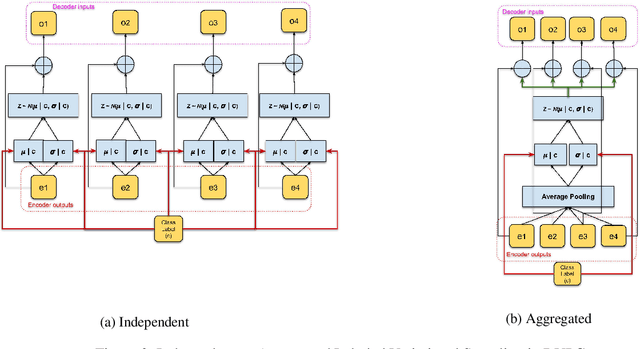
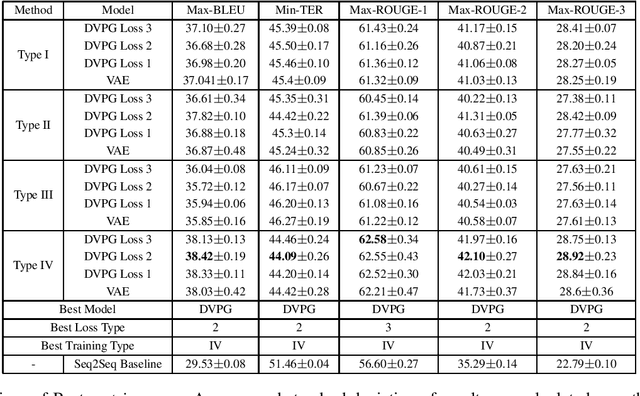
Generating paraphrases that are lexically similar but semantically different is a challenging task. Paraphrases of this form can be used to augment data sets for various NLP tasks such as machine reading comprehension and question answering with non-trivial negative examples. In this article, we propose a deep variational model to generate paraphrases conditioned on a label that specifies whether the paraphrases are semantically related or not. We also present new training recipes and KL regularization techniques that improve the performance of variational paraphrasing models. Our proposed model demonstrates promising results in enhancing the generative power of the model by employing label-dependent generation on paraphrasing datasets.
Semi-Supervised Learning for Text Classification by Layer Partitioning
Nov 26, 2019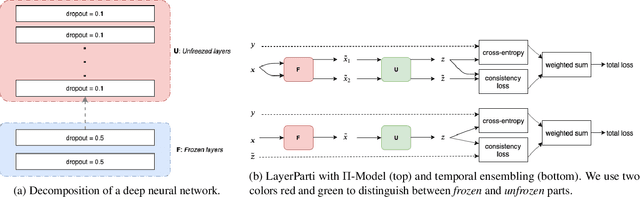
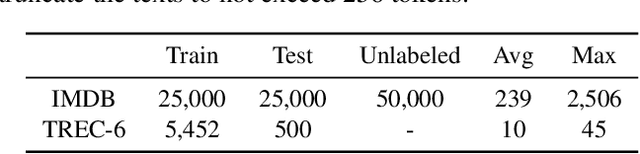
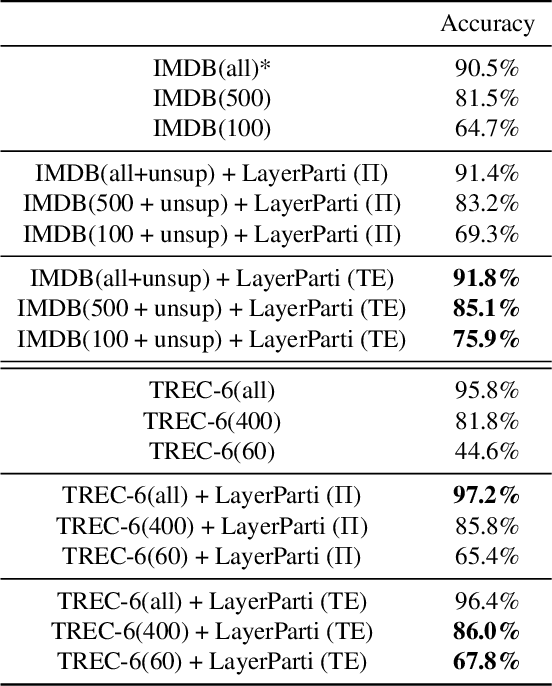
Most recent neural semi-supervised learning algorithms rely on adding small perturbation to either the input vectors or their representations. These methods have been successful on computer vision tasks as the images form a continuous manifold, but are not appropriate for discrete input such as sentence. To adapt these methods to text input, we propose to decompose a neural network $M$ into two components $F$ and $U$ so that $M = U\circ F$. The layers in $F$ are then frozen and only the layers in $U$ will be updated during most time of the training. In this way, $F$ serves as a feature extractor that maps the input to high-level representation and adds systematical noise using dropout. We can then train $U$ using any state-of-the-art SSL algorithms such as $\Pi$-model, temporal ensembling, mean teacher, etc. Furthermore, this gradually unfreezing schedule also prevents a pretrained model from catastrophic forgetting. The experimental results demonstrate that our approach provides improvements when compared to state of the art methods especially on short texts.
Knowledge Distillation in Document Retrieval
Nov 11, 2019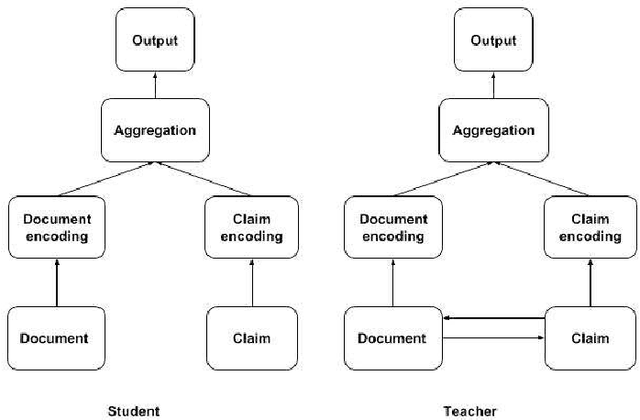
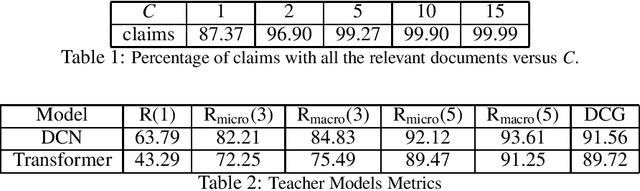

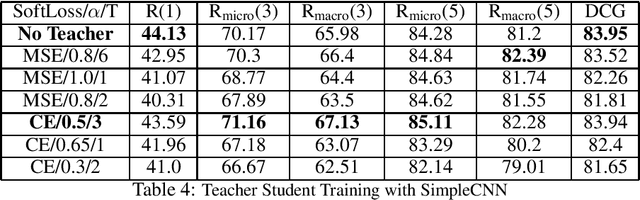
Complex deep learning models now achieve state of the art performance for many document retrieval tasks. The best models process the query or claim jointly with the document. However for fast scalable search it is desirable to have document embeddings which are independent of the claim. In this paper we show that knowledge distillation can be used to encourage a model that generates claim independent document encodings to mimic the behavior of a more complex model which generates claim dependent encodings. We explore this approach in document retrieval for a fact extraction and verification task. We show that by using the soft labels from a complex cross attention teacher model, the performance of claim independent student LSTM or CNN models is improved across all the ranking metrics. The student models we use are 12x faster in runtime and 20x smaller in number of parameters than the teacher
Knowledge Enhanced Attention for Robust Natural Language Inference
Aug 31, 2019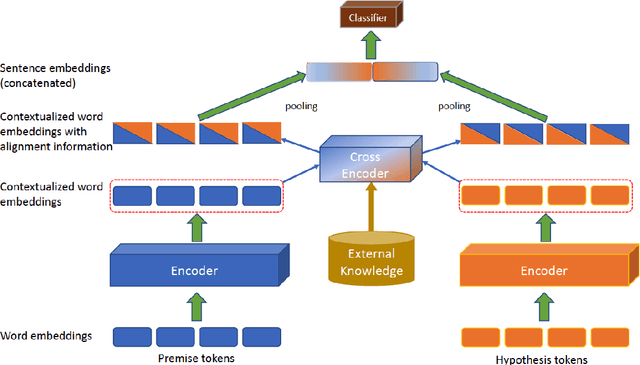
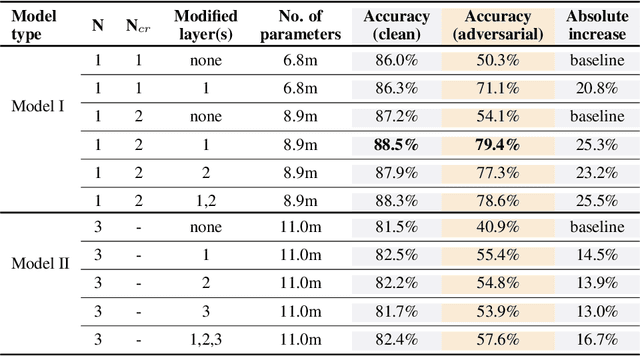
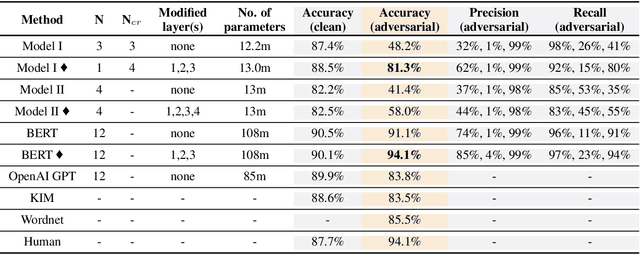
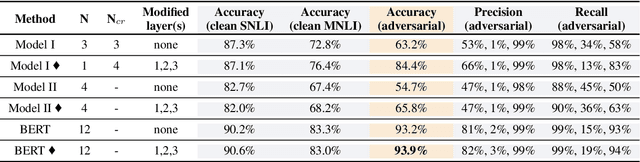
Neural network models have been very successful at achieving high accuracy on natural language inference (NLI) tasks. However, as demonstrated in recent literature, when tested on some simple adversarial examples, most of the models suffer a significant drop in performance. This raises the concern about the robustness of NLI models. In this paper, we propose to make NLI models robust by incorporating external knowledge to the attention mechanism using a simple transformation. We apply the new attention to two popular types of NLI models: one is Transformer encoder, and the other is a decomposable model, and show that our method can significantly improve their robustness. Moreover, when combined with BERT pretraining, our method achieves the human-level performance on the adversarial SNLI data set.
Differentiable Greedy Networks
Oct 30, 2018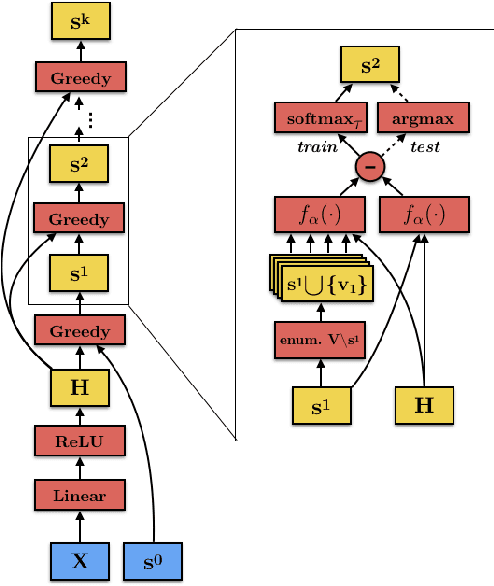
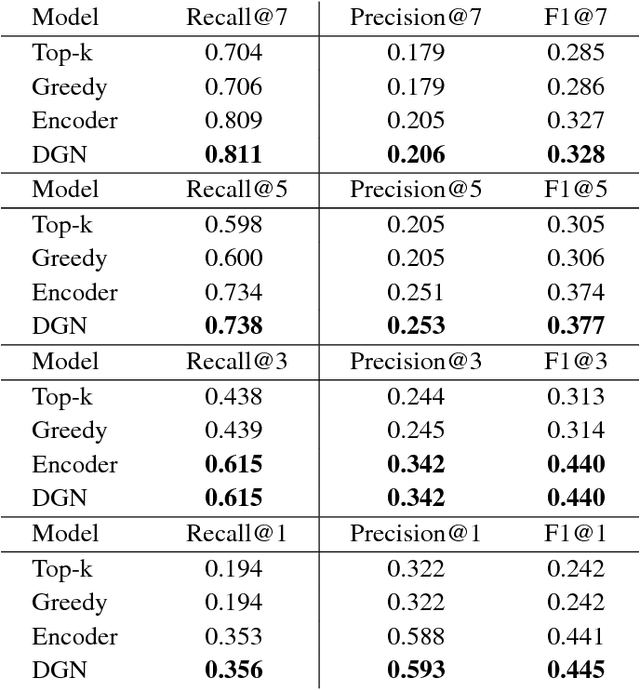
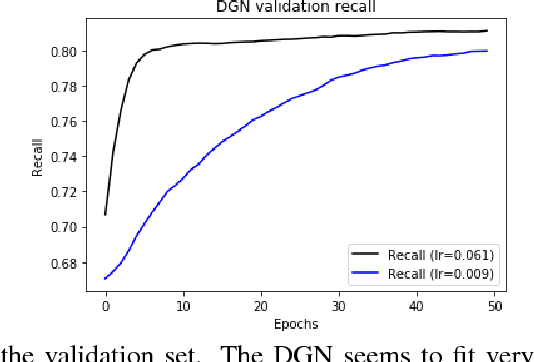

Optimal selection of a subset of items from a given set is a hard problem that requires combinatorial optimization. In this paper, we propose a subset selection algorithm that is trainable with gradient-based methods yet achieves near-optimal performance via submodular optimization. We focus on the task of identifying a relevant set of sentences for claim verification in the context of the FEVER task. Conventional methods for this task look at sentences on their individual merit and thus do not optimize the informativeness of sentences as a set. We show that our proposed method which builds on the idea of unfolding a greedy algorithm into a computational graph allows both interpretability and gradient-based training. The proposed differentiable greedy network (DGN) outperforms discrete optimization algorithms as well as other baseline methods in terms of precision and recall.