 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRewardRank: Optimizing True Learning-to-Rank Utility
Aug 19, 2025
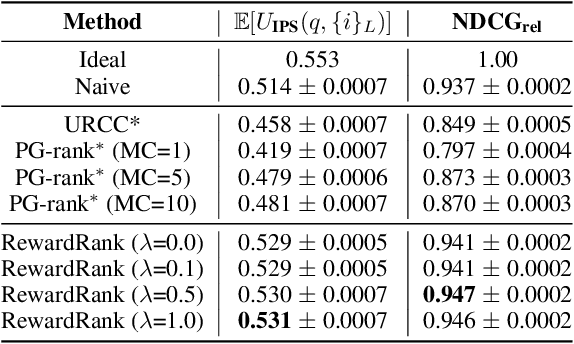
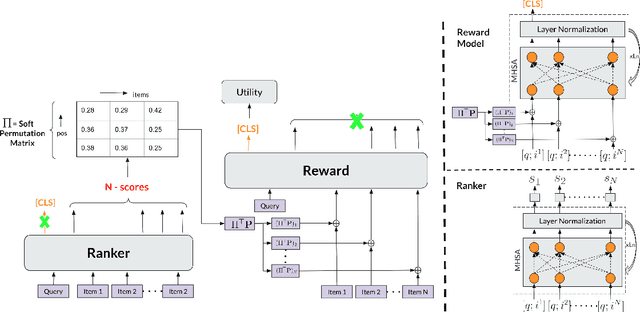
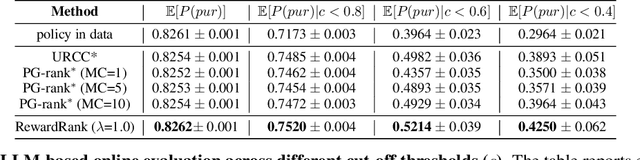
Traditional ranking systems rely on proxy loss functions that assume simplistic user behavior, such as users preferring a rank list where items are sorted by hand-crafted relevance. However, real-world user interactions are influenced by complex behavioral biases, including position bias, brand affinity, decoy effects, and similarity aversion, which these objectives fail to capture. As a result, models trained on such losses often misalign with actual user utility, such as the probability of any click or purchase across the ranked list. In this work, we propose a data-driven framework for modeling user behavior through counterfactual reward learning. Our method, RewardRank, first trains a deep utility model to estimate user engagement for entire item permutations using logged data. Then, a ranking policy is optimized to maximize predicted utility via differentiable soft permutation operators, enabling end-to-end training over the space of factual and counterfactual rankings. To address the challenge of evaluation without ground-truth for unseen permutations, we introduce two automated protocols: (i) $\textit{KD-Eval}$, using a position-aware oracle for counterfactual reward estimation, and (ii) $\textit{LLM-Eval}$, which simulates user preferences via large language models. Experiments on large-scale benchmarks, including Baidu-ULTR and the Amazon KDD Cup datasets, demonstrate that our approach consistently outperforms strong baselines, highlighting the effectiveness of modeling user behavior dynamics for utility-optimized ranking. Our code is available at: https://github.com/GauravBh1010tt/RewardRank
Knowledge Distillation with Training Wheels
Feb 24, 2025Knowledge distillation is used, in generative language modeling, to train a smaller student model using the help of a larger teacher model, resulting in improved capabilities for the student model. In this paper, we formulate a more general framework for knowledge distillation where the student learns from the teacher during training, and also learns to ask for the teacher's help at test-time following rules specifying test-time restrictions. Towards this, we first formulate knowledge distillation as an entropy-regularized value optimization problem. Adopting Path Consistency Learning to solve this, leads to a new knowledge distillation algorithm using on-policy and off-policy demonstrations. We extend this using constrained reinforcement learning to a framework that incorporates the use of the teacher model as a test-time reference, within constraints. In this situation, akin to a human learner, the model needs to learn not only the learning material, but also the relative difficulty of different sections to prioritize for seeking teacher help. We examine the efficacy of our method through experiments in translation and summarization tasks, observing trends in accuracy and teacher use, noting that our approach unlocks operating points not available to the popular Speculative Decoding approach.
Multi-Objective Optimization via Wasserstein-Fisher-Rao Gradient Flow
Nov 22, 2023



Multi-objective optimization (MOO) aims to optimize multiple, possibly conflicting objectives with widespread applications. We introduce a novel interacting particle method for MOO inspired by molecular dynamics simulations. Our approach combines overdamped Langevin and birth-death dynamics, incorporating a "dominance potential" to steer particles toward global Pareto optimality. In contrast to previous methods, our method is able to relocate dominated particles, making it particularly adept at managing Pareto fronts of complicated geometries. Our method is also theoretically grounded as a Wasserstein-Fisher-Rao gradient flow with convergence guarantees. Extensive experiments confirm that our approach outperforms state-of-the-art methods on challenging synthetic and real-world datasets.
Selective Uncertainty Propagation in Offline RL
Feb 01, 2023We study the finite-horizon offline reinforcement learning (RL) problem. Since actions at any state can affect next-state distributions, the related distributional shift challenges can make this problem far more statistically complex than offline policy learning for a finite sequence of stochastic contextual bandit environments. We formalize this insight by showing that the statistical hardness of offline RL instances can be measured by estimating the size of actions' impact on next-state distributions. Furthermore, this estimated impact allows us to propagate just enough value function uncertainty from future steps to avoid model exploitation, enabling us to develop algorithms that improve upon traditional pessimistic approaches for offline RL on statistically simple instances. Our approach is supported by theory and simulations.
Imitation Learning from Observations under Transition Model Disparity
Apr 25, 2022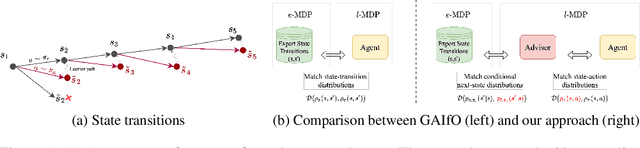
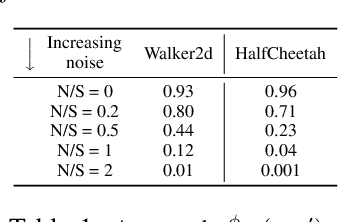
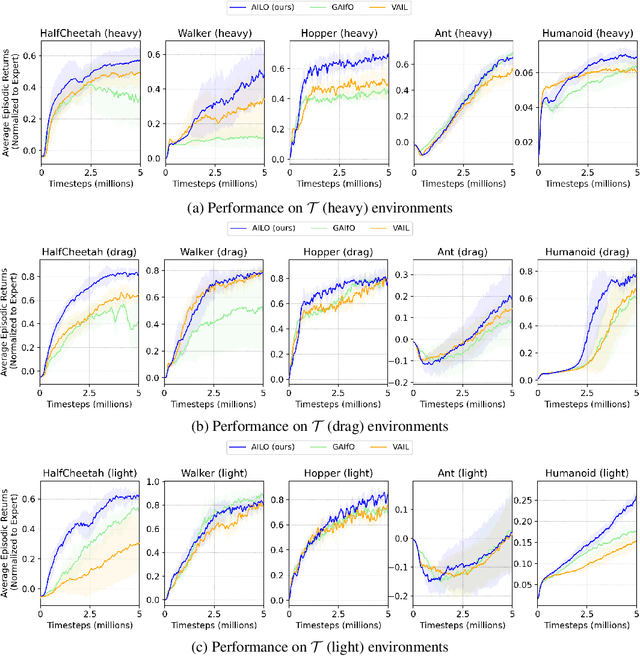

Learning to perform tasks by leveraging a dataset of expert observations, also known as imitation learning from observations (ILO), is an important paradigm for learning skills without access to the expert reward function or the expert actions. We consider ILO in the setting where the expert and the learner agents operate in different environments, with the source of the discrepancy being the transition dynamics model. Recent methods for scalable ILO utilize adversarial learning to match the state-transition distributions of the expert and the learner, an approach that becomes challenging when the dynamics are dissimilar. In this work, we propose an algorithm that trains an intermediary policy in the learner environment and uses it as a surrogate expert for the learner. The intermediary policy is learned such that the state transitions generated by it are close to the state transitions in the expert dataset. To derive a practical and scalable algorithm, we employ concepts from prior work on estimating the support of a probability distribution. Experiments using MuJoCo locomotion tasks highlight that our method compares favorably to the baselines for ILO with transition dynamics mismatch.
Hindsight Foresight Relabeling for Meta-Reinforcement Learning
Sep 18, 2021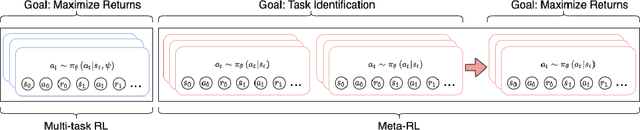
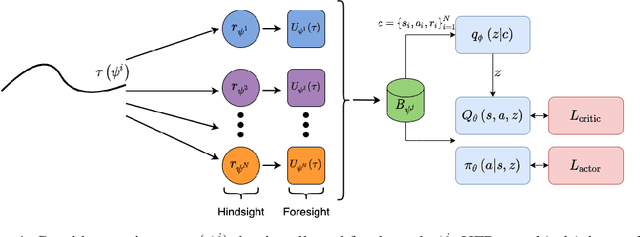
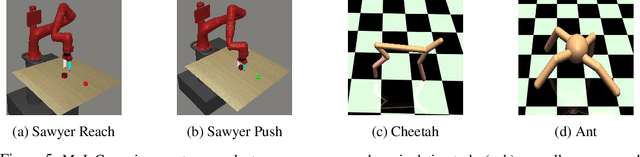

Meta-reinforcement learning (meta-RL) algorithms allow for agents to learn new behaviors from small amounts of experience, mitigating the sample inefficiency problem in RL. However, while meta-RL agents can adapt quickly to new tasks at test time after experiencing only a few trajectories, the meta-training process is still sample-inefficient. Prior works have found that in the multi-task RL setting, relabeling past transitions and thus sharing experience among tasks can improve sample efficiency and asymptotic performance. We apply this idea to the meta-RL setting and devise a new relabeling method called Hindsight Foresight Relabeling (HFR). We construct a relabeling distribution using the combination of "hindsight", which is used to relabel trajectories using reward functions from the training task distribution, and "foresight", which takes the relabeled trajectories and computes the utility of each trajectory for each task. HFR is easy to implement and readily compatible with existing meta-RL algorithms. We find that HFR improves performance when compared to other relabeling methods on a variety of meta-RL tasks.
Harnessing Distribution Ratio Estimators for Learning Agents with Quality and Diversity
Nov 05, 2020


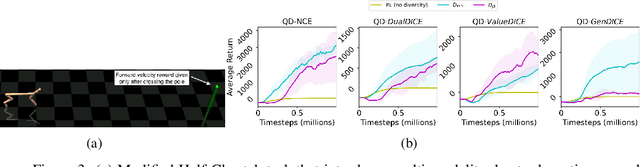
Quality-Diversity (QD) is a concept from Neuroevolution with some intriguing applications to Reinforcement Learning. It facilitates learning a population of agents where each member is optimized to simultaneously accumulate high task-returns and exhibit behavioral diversity compared to other members. In this paper, we build on a recent kernel-based method for training a QD policy ensemble with Stein variational gradient descent. With kernels based on $f$-divergence between the stationary distributions of policies, we convert the problem to that of efficient estimation of the ratio of these stationary distributions. We then study various distribution ratio estimators used previously for off-policy evaluation and imitation and re-purpose them to compute the gradients for policies in an ensemble such that the resultant population is diverse and of high-quality.
Learning Guidance Rewards with Trajectory-space Smoothing
Oct 23, 2020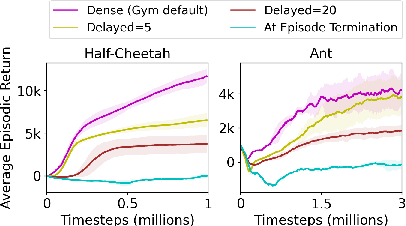

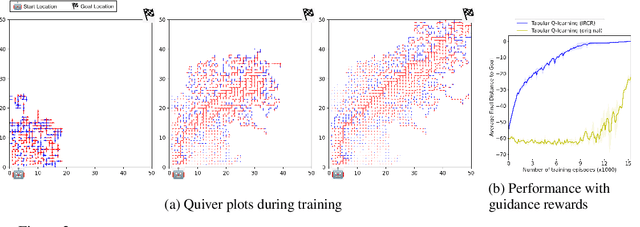
Long-term temporal credit assignment is an important challenge in deep reinforcement learning (RL). It refers to the ability of the agent to attribute actions to consequences that may occur after a long time interval. Existing policy-gradient and Q-learning algorithms typically rely on dense environmental rewards that provide rich short-term supervision and help with credit assignment. However, they struggle to solve tasks with delays between an action and the corresponding rewarding feedback. To make credit assignment easier, recent works have proposed algorithms to learn dense "guidance" rewards that could be used in place of the sparse or delayed environmental rewards. This paper is in the same vein -- starting with a surrogate RL objective that involves smoothing in the trajectory-space, we arrive at a new algorithm for learning guidance rewards. We show that the guidance rewards have an intuitive interpretation, and can be obtained without training any additional neural networks. Due to the ease of integration, we use the guidance rewards in a few popular algorithms (Q-learning, Actor-Critic, Distributional-RL) and present results in single-agent and multi-agent tasks that elucidate the benefit of our approach when the environmental rewards are sparse or delayed.
Mutual Information Based Knowledge Transfer Under State-Action Dimension Mismatch
Jun 12, 2020


Deep reinforcement learning (RL) algorithms have achieved great success on a wide variety of sequential decision-making tasks. However, many of these algorithms suffer from high sample complexity when learning from scratch using environmental rewards, due to issues such as credit-assignment and high-variance gradients, among others. Transfer learning, in which knowledge gained on a source task is applied to more efficiently learn a different but related target task, is a promising approach to improve the sample complexity in RL. Prior work has considered using pre-trained teacher policies to enhance the learning of the student policy, albeit with the constraint that the teacher and the student MDPs share the state-space or the action-space. In this paper, we propose a new framework for transfer learning where the teacher and the student can have arbitrarily different state- and action-spaces. To handle this mismatch, we produce embeddings which can systematically extract knowledge from the teacher policy and value networks, and blend it into the student networks. To train the embeddings, we use a task-aligned loss and show that the representations could be enriched further by adding a mutual information loss. Using a set of challenging simulated robotic locomotion tasks involving many-legged centipedes, we demonstrate successful transfer learning in situations when the teacher and student have different state- and action-spaces.
State-only Imitation with Transition Dynamics Mismatch
Feb 27, 2020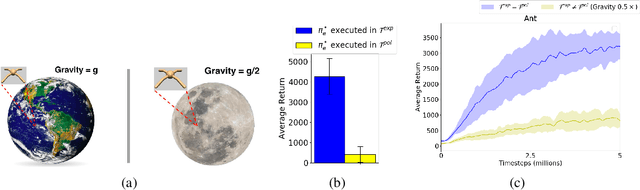


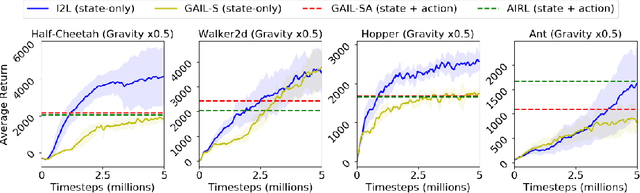
Imitation Learning (IL) is a popular paradigm for training agents to achieve complicated goals by leveraging expert behavior, rather than dealing with the hardships of designing a correct reward function. With the environment modeled as a Markov Decision Process (MDP), most of the existing IL algorithms are contingent on the availability of expert demonstrations in the same MDP as the one in which a new imitator policy is to be learned. This is uncharacteristic of many real-life scenarios where discrepancies between the expert and the imitator MDPs are common, especially in the transition dynamics function. Furthermore, obtaining expert actions may be costly or infeasible, making the recent trend towards state-only IL (where expert demonstrations constitute only states or observations) ever so promising. Building on recent adversarial imitation approaches that are motivated by the idea of divergence minimization, we present a new state-only IL algorithm in this paper. It divides the overall optimization objective into two subproblems by introducing an indirection step and solves the subproblems iteratively. We show that our algorithm is particularly effective when there is a transition dynamics mismatch between the expert and imitator MDPs, while the baseline IL methods suffer from performance degradation. To analyze this, we construct several interesting MDPs by modifying the configuration parameters for the MuJoCo locomotion tasks from OpenAI Gym.