 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Post-Training for Generative Recommenders: Why Exponential Reward-Weighted SFT Outperforms RLHF
Mar 10, 2026Aligning generative recommender systems to user preferences via post-training is critical for closing the gap between next-item prediction and actual recommendation quality. Existing post-training methods are ill-suited for production-scale systems: RLHF methods reward hack due to noisy user feedback and unreliable reward models, offline RL alternatives require propensity scores that are unavailable, and online interaction is infeasible. We identify exponential reward-weighted SFT with weights $w = \exp(r/λ)$ as uniquely suited to this setting, and provide the theoretical and empirical foundations that explain why. By optimizing directly on observed rewards without querying a learned reward model, the method is immune to reward hacking, requires no propensity scores, and is fully offline. We prove the first policy improvement guarantees for this setting under noisy rewards, showing that the gap scales only logarithmically with catalog size and remains informative even for large item catalogs. Crucially, we show that temperature $λ$ explicitly and quantifiably controls the robustness-improvement tradeoff, providing practitioners with a single interpretable regularization hyperparameter with theoretical grounding. Experiments on three open-source and one proprietary dataset against four baselines confirm that exponential reward weighting is simple, scalable, and consistently outperforms RLHF-based alternatives.
Adaptive Exploration for Latent-State Bandits
Feb 04, 2026The multi-armed bandit problem is a core framework for sequential decision-making under uncertainty, but classical algorithms often fail in environments with hidden, time-varying states that confound reward estimation and optimal action selection. We address key challenges arising from unobserved confounders, such as biased reward estimates and limited state information, by introducing a family of state-model-free bandit algorithms that leverage lagged contextual features and coordinated probing strategies. These implicitly track latent states and disambiguate state-dependent reward patterns. Our methods and their adaptive variants can learn optimal policies without explicit state modeling, combining computational efficiency with robust adaptation to non-stationary rewards. Empirical results across diverse settings demonstrate superior performance over classical approaches, and we provide practical recommendations for algorithm selection in real-world applications.
Data-driven Error Estimation: Upper Bounding Multiple Errors with No Technical Debt
May 07, 2024We formulate the problem of constructing multiple simultaneously valid confidence intervals (CIs) as estimating a high probability upper bound on the maximum error for a class/set of estimate-estimand-error tuples, and refer to this as the error estimation problem. For a single such tuple, data-driven confidence intervals can often be used to bound the error in our estimate. However, for a class of estimate-estimand-error tuples, nontrivial high probability upper bounds on the maximum error often require class complexity as input -- limiting the practicality of such methods and often resulting in loose bounds. Rather than deriving theoretical class complexity-based bounds, we propose a completely data-driven approach to estimate an upper bound on the maximum error. The simple and general nature of our solution to this fundamental challenge lends itself to several applications including: multiple CI construction, multiple hypothesis testing, estimating excess risk bounds (a fundamental measure of uncertainty in machine learning) for any training/fine-tuning algorithm, and enabling the development of a contextual bandit pipeline that can leverage any reward model estimation procedure as input (without additional mathematical analysis).
Proportional Response: Contextual Bandits for Simple and Cumulative Regret Minimization
Jul 05, 2023
Simple regret minimization is a critical problem in learning optimal treatment assignment policies across various domains, including healthcare and e-commerce. However, it remains understudied in the contextual bandit setting. We propose a new family of computationally efficient bandit algorithms for the stochastic contextual bandit settings, with the flexibility to be adapted for cumulative regret minimization (with near-optimal minimax guarantees) and simple regret minimization (with SOTA guarantees). Furthermore, our algorithms adapt to model misspecification and extend to the continuous arm settings. These advantages come from constructing and relying on "conformal arm sets" (CASs), which provide a set of arms at every context that encompass the context-specific optimal arm with some probability across the context distribution. Our positive results on simple and cumulative regret guarantees are contrasted by a negative result, which shows that an algorithm can't achieve instance-dependent simple regret guarantees while simultaneously achieving minimax optimal cumulative regret guarantees.
Selective Uncertainty Propagation in Offline RL
Feb 01, 2023We study the finite-horizon offline reinforcement learning (RL) problem. Since actions at any state can affect next-state distributions, the related distributional shift challenges can make this problem far more statistically complex than offline policy learning for a finite sequence of stochastic contextual bandit environments. We formalize this insight by showing that the statistical hardness of offline RL instances can be measured by estimating the size of actions' impact on next-state distributions. Furthermore, this estimated impact allows us to propagate just enough value function uncertainty from future steps to avoid model exploitation, enabling us to develop algorithms that improve upon traditional pessimistic approaches for offline RL on statistically simple instances. Our approach is supported by theory and simulations.
Contextual Bandits in a Survey Experiment on Charitable Giving: Within-Experiment Outcomes versus Policy Learning
Nov 22, 2022We design and implement an adaptive experiment (a ``contextual bandit'') to learn a targeted treatment assignment policy, where the goal is to use a participant's survey responses to determine which charity to expose them to in a donation solicitation. The design balances two competing objectives: optimizing the outcomes for the subjects in the experiment (``cumulative regret minimization'') and gathering data that will be most useful for policy learning, that is, for learning an assignment rule that will maximize welfare if used after the experiment (``simple regret minimization''). We evaluate alternative experimental designs by collecting pilot data and then conducting a simulation study. Next, we implement our selected algorithm. Finally, we perform a second simulation study anchored to the collected data that evaluates the benefits of the algorithm we chose. Our first result is that the value of a learned policy in this setting is higher when data is collected via a uniform randomization rather than collected adaptively using standard cumulative regret minimization or policy learning algorithms. We propose a simple heuristic for adaptive experimentation that improves upon uniform randomization from the perspective of policy learning at the expense of increasing cumulative regret relative to alternative bandit algorithms. The heuristic modifies an existing contextual bandit algorithm by (i) imposing a lower bound on assignment probabilities that decay slowly so that no arm is discarded too quickly, and (ii) after adaptively collecting data, restricting policy learning to select from arms where sufficient data has been gathered.
Flexible and Efficient Contextual Bandits with Heterogeneous Treatment Effect Oracle
Mar 30, 2022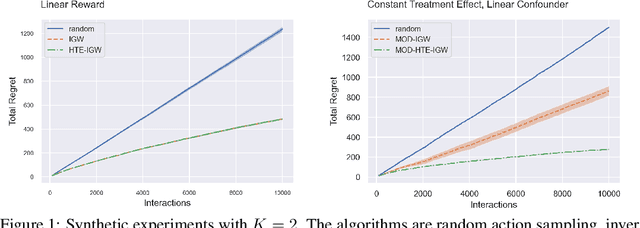
Many popular contextual bandit algorithms estimate reward models to inform decision making. However, true rewards can contain action-independent redundancies that are not relevant for decision making and only increase the statistical complexity of accurate estimation. It is sufficient and more data-efficient to estimate the simplest function that explains the reward differences between actions, that is, the heterogeneous treatment effect, commonly understood to be more structured and simpler than the reward. Motivated by this observation, building on recent work on oracle-based algorithms, we design a statistically optimal and computationally efficient algorithm using heterogeneous treatment effect estimation oracles. Our results provide the first universal reduction of contextual bandits to a general-purpose heterogeneous treatment effect estimation method. We show that our approach is more robust to model misspecification than reward estimation methods based on squared error regression oracles. Experimentally, we show the benefits of heterogeneous treatment effect estimation in contextual bandits over reward estimation.
Optimal Model Selection in Contextual Bandits with Many Classes via Offline Oracles
Jun 11, 2021
We study the problem of model selection for contextual bandits, in which the algorithm must balance the bias-variance trade-off for model estimation while also balancing the exploration-exploitation trade-off. In this paper, we propose the first reduction of model selection in contextual bandits to offline model selection oracles, allowing for flexible general purpose algorithms with computational requirements no worse than those for model selection for regression. Our main result is a new model selection guarantee for stochastic contextual bandits. When one of the classes in our set is realizable, up to a logarithmic dependency on the number of classes, our algorithm attains optimal realizability-based regret bounds for that class under one of two conditions: if the time-horizon is large enough, or if an assumption that helps with detecting misspecification holds. Hence our algorithm adapts to the complexity of this unknown class. Even when this realizable class is known, we prove improved regret guarantees in early rounds by relying on simpler model classes for those rounds and hence further establish the importance of model selection in contextual bandits.
Adapting to misspecification in contextual bandits with offline regression oracles
Feb 26, 2021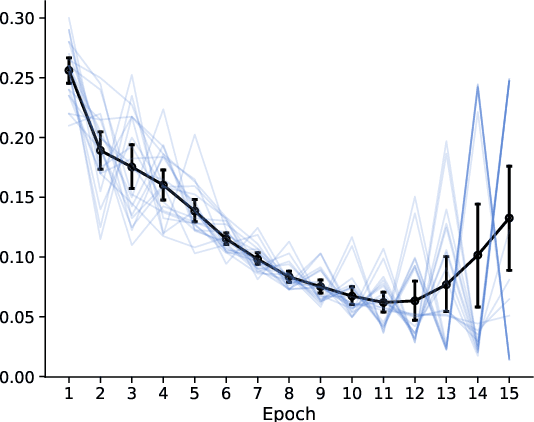
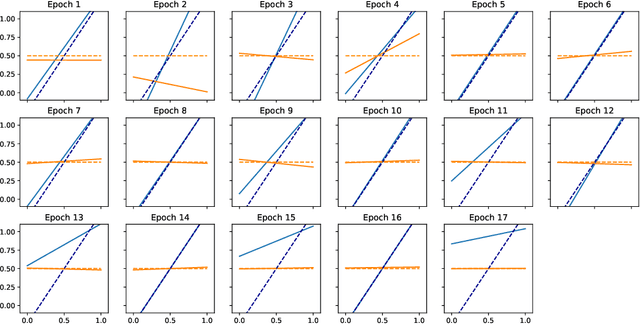
Computationally efficient contextual bandits are often based on estimating a predictive model of rewards given contexts and arms using past data. However, when the reward model is not well-specified, the bandit algorithm may incur unexpected regret, so recent work has focused on algorithms that are robust to misspecification. We propose a simple family of contextual bandit algorithms that adapt to misspecification error by reverting to a good safe policy when there is evidence that misspecification is causing a regret increase. Our algorithm requires only an offline regression oracle to ensure regret guarantees that gracefully degrade in terms of a measure of the average misspecification level. Compared to prior work, we attain similar regret guarantees, but we do no rely on a master algorithm, and do not require more robust oracles like online or constrained regression oracles (e.g., Foster et al. (2020a); Krishnamurthy et al. (2020)). This allows us to design algorithms for more general function approximation classes.
Tractable contextual bandits beyond realizability
Oct 25, 2020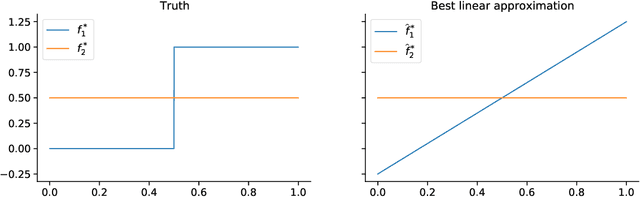
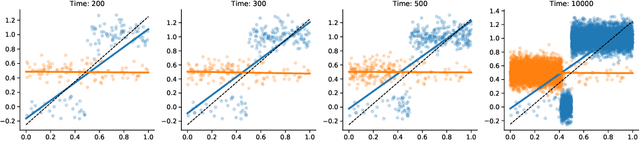
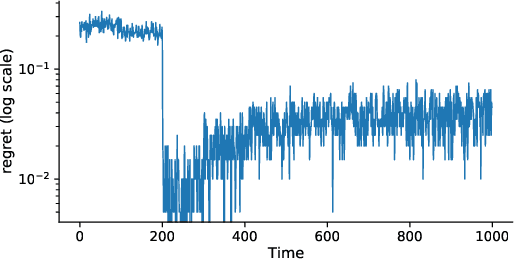
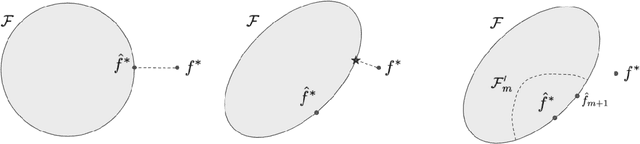
Tractable contextual bandit algorithms often rely on the realizability assumption -- i.e., that the true expected reward model belongs to a known class, such as linear functions. We investigate issues that arise in the absence of realizability and note that the dynamics of adaptive data collection can lead commonly used bandit algorithms to learn a suboptimal policy. In this work, we present a tractable bandit algorithm that is not sensitive to the realizability assumption and computationally reduces to solving a constrained regression problem in every epoch. When realizability does not hold, our algorithm ensures the same guarantees on regret achieved by realizability-based algorithms under realizability, up to an additive term that accounts for the misspecification error. This extra term is proportional to T times the (2/5)-root of the mean squared error between the best model in the class and the true model, where T is the total number of time-steps. Our work sheds light on the bias-variance trade-off for tractable contextual bandits. This trade-off is not captured by algorithms that assume realizability, since under this assumption there exists an estimator in the class that attains zero bias.