 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCo-Writing with AI, on Human Terms: Aligning Research with User Demands Across the Writing Process
Apr 16, 2025



As generative AI tools like ChatGPT become integral to everyday writing, critical questions arise about how to preserve writers' sense of agency and ownership when using these tools. Yet, a systematic understanding of how AI assistance affects different aspects of the writing process - and how this shapes writers' agency - remains underexplored. To address this gap, we conducted a systematic review of 109 HCI papers using the PRISMA approach. From this literature, we identify four overarching design strategies for AI writing support: structured guidance, guided exploration, active co-writing, and critical feedback - mapped across the four key cognitive processes in writing: planning, translating, reviewing, and monitoring. We complement this analysis with interviews of 15 writers across diverse domains. Our findings reveal that writers' desired levels of AI intervention vary across the writing process: content-focused writers (e.g., academics) prioritize ownership during planning, while form-focused writers (e.g., creatives) value control over translating and reviewing. Writers' preferences are also shaped by contextual goals, values, and notions of originality and authorship. By examining when ownership matters, what writers want to own, and how AI interactions shape agency, we surface both alignment and gaps between research and user needs. Our findings offer actionable design guidance for developing human-centered writing tools for co-writing with AI, on human terms.
WAPTS: A Weighted Allocation Probability Adjusted Thompson Sampling Algorithm for High-Dimensional and Sparse Experiment Settings
Jan 07, 2025Aiming for more effective experiment design, such as in video content advertising where different content options compete for user engagement, these scenarios can be modeled as multi-arm bandit problems. In cases where limited interactions are available due to external factors, such as the cost of conducting experiments, recommenders often face constraints due to the small number of user interactions. In addition, there is a trade-off between selecting the best treatment and the ability to personalize and contextualize based on individual factors. A popular solution to this dilemma is the Contextual Bandit framework. It aims to maximize outcomes while incorporating personalization (contextual) factors, customizing treatments such as a user's profile to individual preferences. Despite their advantages, Contextual Bandit algorithms face challenges like measurement bias and the 'curse of dimensionality.' These issues complicate the management of numerous interventions and often lead to data sparsity through participant segmentation. To address these problems, we introduce the Weighted Allocation Probability Adjusted Thompson Sampling (WAPTS) algorithm. WAPTS builds on the contextual Thompson Sampling method by using a dynamic weighting parameter. This improves the allocation process for interventions and enables rapid optimization in data-sparse environments. We demonstrate the performance of our approach on different numbers of arms and effect sizes.
Opportunities for Adaptive Experiments to Enable Continuous Improvement that Trades-off Instructor and Researcher Incentives
Oct 18, 2023



Randomized experimental comparisons of alternative pedagogical strategies could provide useful empirical evidence in instructors' decision-making. However, traditional experiments do not have a clear and simple pathway to using data rapidly to try to increase the chances that students in an experiment get the best conditions. Drawing inspiration from the use of machine learning and experimentation in product development at leading technology companies, we explore how adaptive experimentation might help in continuous course improvement. In adaptive experiments, as different arms/conditions are deployed to students, data is analyzed and used to change the experience for future students. This can be done using machine learning algorithms to identify which actions are more promising for improving student experience or outcomes. This algorithm can then dynamically deploy the most effective conditions to future students, resulting in better support for students' needs. We illustrate the approach with a case study providing a side-by-side comparison of traditional and adaptive experimentation of self-explanation prompts in online homework problems in a CS1 course. This provides a first step in exploring the future of how this methodology can be useful in bridging research and practice in doing continuous improvement.
Using Adaptive Bandit Experiments to Increase and Investigate Engagement in Mental Health
Oct 13, 2023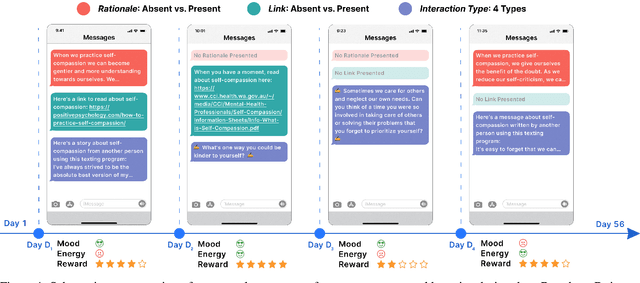

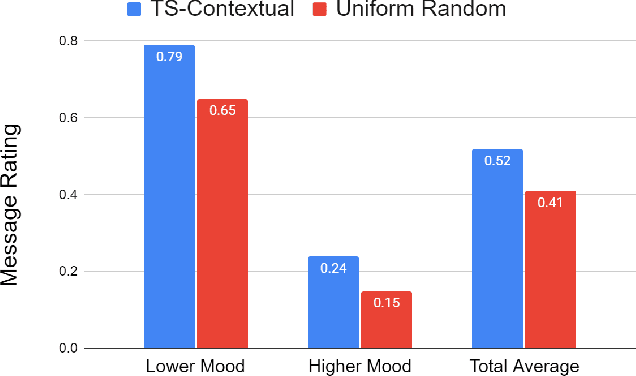

Digital mental health (DMH) interventions, such as text-message-based lessons and activities, offer immense potential for accessible mental health support. While these interventions can be effective, real-world experimental testing can further enhance their design and impact. Adaptive experimentation, utilizing algorithms like Thompson Sampling for (contextual) multi-armed bandit (MAB) problems, can lead to continuous improvement and personalization. However, it remains unclear when these algorithms can simultaneously increase user experience rewards and facilitate appropriate data collection for social-behavioral scientists to analyze with sufficient statistical confidence. Although a growing body of research addresses the practical and statistical aspects of MAB and other adaptive algorithms, further exploration is needed to assess their impact across diverse real-world contexts. This paper presents a software system developed over two years that allows text-messaging intervention components to be adapted using bandit and other algorithms while collecting data for side-by-side comparison with traditional uniform random non-adaptive experiments. We evaluate the system by deploying a text-message-based DMH intervention to 1100 users, recruited through a large mental health non-profit organization, and share the path forward for deploying this system at scale. This system not only enables applications in mental health but could also serve as a model testbed for adaptive experimentation algorithms in other domains.
Impact of Guidance and Interaction Strategies for LLM Use on Learner Performance and Perception
Oct 13, 2023Personalized chatbot-based teaching assistants can be crucial in addressing increasing classroom sizes, especially where direct teacher presence is limited. Large language models (LLMs) offer a promising avenue, with increasing research exploring their educational utility. However, the challenge lies not only in establishing the efficacy of LLMs but also in discerning the nuances of interaction between learners and these models, which impact learners' engagement and results. We conducted a formative study in an undergraduate computer science classroom (N=145) and a controlled experiment on Prolific (N=356) to explore the impact of four pedagogically informed guidance strategies and the interaction between student approaches and LLM responses. Direct LLM answers marginally improved performance, while refining student solutions fostered trust. Our findings suggest a nuanced relationship between the guidance provided and LLM's role in either answering or refining student input. Based on our findings, we provide design recommendations for optimizing learner-LLM interactions.
ABScribe: Rapid Exploration of Multiple Writing Variations in Human-AI Co-Writing Tasks using Large Language Models
Oct 10, 2023Exploring alternative ideas by rewriting text is integral to the writing process. State-of-the-art large language models (LLMs) can simplify writing variation generation. However, current interfaces pose challenges for simultaneous consideration of multiple variations: creating new versions without overwriting text can be difficult, and pasting them sequentially can clutter documents, increasing workload and disrupting writers' flow. To tackle this, we present ABScribe, an interface that supports rapid, yet visually structured, exploration of writing variations in human-AI co-writing tasks. With ABScribe, users can swiftly produce multiple variations using LLM prompts, which are auto-converted into reusable buttons. Variations are stored adjacently within text segments for rapid in-place comparisons using mouse-over interactions on a context toolbar. Our user study with 12 writers shows that ABScribe significantly reduces task workload (d = 1.20, p < 0.001), enhances user perceptions of the revision process (d = 2.41, p < 0.001) compared to a popular baseline workflow, and provides insights into how writers explore variations using LLMs.
Getting too personal(ized): The importance of feature choice in online adaptive algorithms
Sep 06, 2023



Digital educational technologies offer the potential to customize students' experiences and learn what works for which students, enhancing the technology as more students interact with it. We consider whether and when attempting to discover how to personalize has a cost, such as if the adaptation to personal information can delay the adoption of policies that benefit all students. We explore these issues in the context of using multi-armed bandit (MAB) algorithms to learn a policy for what version of an educational technology to present to each student, varying the relation between student characteristics and outcomes and also whether the algorithm is aware of these characteristics. Through simulations, we demonstrate that the inclusion of student characteristics for personalization can be beneficial when those characteristics are needed to learn the optimal action. In other scenarios, this inclusion decreases performance of the bandit algorithm. Moreover, including unneeded student characteristics can systematically disadvantage students with less common values for these characteristics. Our simulations do however suggest that real-time personalization will be helpful in particular real-world scenarios, and we illustrate this through case studies using existing experimental results in ASSISTments. Overall, our simulations show that adaptive personalization in educational technologies can be a double-edged sword: real-time adaptation improves student experiences in some contexts, but the slower adaptation and potentially discriminatory results mean that a more personalized model is not always beneficial.
Contextual Bandits in a Survey Experiment on Charitable Giving: Within-Experiment Outcomes versus Policy Learning
Nov 22, 2022We design and implement an adaptive experiment (a ``contextual bandit'') to learn a targeted treatment assignment policy, where the goal is to use a participant's survey responses to determine which charity to expose them to in a donation solicitation. The design balances two competing objectives: optimizing the outcomes for the subjects in the experiment (``cumulative regret minimization'') and gathering data that will be most useful for policy learning, that is, for learning an assignment rule that will maximize welfare if used after the experiment (``simple regret minimization''). We evaluate alternative experimental designs by collecting pilot data and then conducting a simulation study. Next, we implement our selected algorithm. Finally, we perform a second simulation study anchored to the collected data that evaluates the benefits of the algorithm we chose. Our first result is that the value of a learned policy in this setting is higher when data is collected via a uniform randomization rather than collected adaptively using standard cumulative regret minimization or policy learning algorithms. We propose a simple heuristic for adaptive experimentation that improves upon uniform randomization from the perspective of policy learning at the expense of increasing cumulative regret relative to alternative bandit algorithms. The heuristic modifies an existing contextual bandit algorithm by (i) imposing a lower bound on assignment probabilities that decay slowly so that no arm is discarded too quickly, and (ii) after adaptively collecting data, restricting policy learning to select from arms where sufficient data has been gathered.
Using Adaptive Experiments to Rapidly Help Students
Aug 10, 2022Adaptive experiments can increase the chance that current students obtain better outcomes from a field experiment of an instructional intervention. In such experiments, the probability of assigning students to conditions changes while more data is being collected, so students can be assigned to interventions that are likely to perform better. Digital educational environments lower the barrier to conducting such adaptive experiments, but they are rarely applied in education. One reason might be that researchers have access to few real-world case studies that illustrate the advantages and disadvantages of these experiments in a specific context. We evaluate the effect of homework email reminders in students by conducting an adaptive experiment using the Thompson Sampling algorithm and compare it to a traditional uniform random experiment. We present this as a case study on how to conduct such experiments, and we raise a range of open questions about the conditions under which adaptive randomized experiments may be more or less useful.
Increasing Students' Engagement to Reminder Emails Through Multi-Armed Bandits
Aug 10, 2022
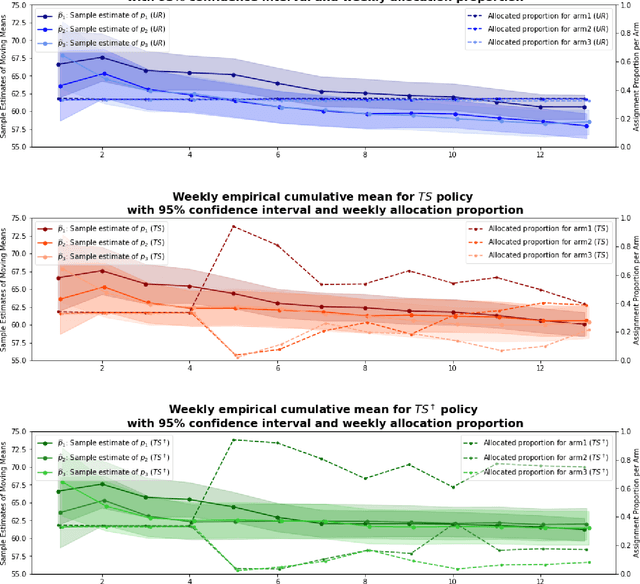


Conducting randomized experiments in education settings raises the question of how we can use machine learning techniques to improve educational interventions. Using Multi-Armed Bandits (MAB) algorithms like Thompson Sampling (TS) in adaptive experiments can increase students' chances of obtaining better outcomes by increasing the probability of assignment to the most optimal condition (arm), even before an intervention completes. This is an advantage over traditional A/B testing, which may allocate an equal number of students to both optimal and non-optimal conditions. The problem is the exploration-exploitation trade-off. Even though adaptive policies aim to collect enough information to allocate more students to better arms reliably, past work shows that this may not be enough exploration to draw reliable conclusions about whether arms differ. Hence, it is of interest to provide additional uniform random (UR) exploration throughout the experiment. This paper shows a real-world adaptive experiment on how students engage with instructors' weekly email reminders to build their time management habits. Our metric of interest is open email rates which tracks the arms represented by different subject lines. These are delivered following different allocation algorithms: UR, TS, and what we identified as TS{\dag} - which combines both TS and UR rewards to update its priors. We highlight problems with these adaptive algorithms - such as possible exploitation of an arm when there is no significant difference - and address their causes and consequences. Future directions includes studying situations where the early choice of the optimal arm is not ideal and how adaptive algorithms can address them.