 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTreeWriter: AI-Assisted Hierarchical Planning and Writing for Long-Form Documents
Jan 19, 2026Long documents pose many challenges to current intelligent writing systems. These include maintaining consistency across sections, sustaining efficient planning and writing as documents become more complex, and effectively providing and integrating AI assistance to the user. Existing AI co-writing tools offer either inline suggestions or limited structured planning, but rarely support the entire writing process that begins with high-level ideas and ends with polished prose, in which many layers of planning and outlining are needed. Here, we introduce TreeWriter, a hierarchical writing system that represents documents as trees and integrates contextual AI support. TreeWriter allows authors to create, save, and refine document outlines at multiple levels, facilitating drafting, understanding, and iterative editing of long documents. A built-in AI agent can dynamically load relevant content, navigate the document hierarchy, and provide context-aware editing suggestions. A within-subject study (N=12) comparing TreeWriter with Google Docs + Gemini on long-document editing and creative writing tasks shows that TreeWriter improves idea exploration/development, AI helpfulness, and perceived authorial control. A two-month field deployment (N=8) further demonstrated that hierarchical organization supports collaborative writing. Our findings highlight the potential of hierarchical, tree-structured editors with integrated AI support and provide design guidelines for future AI-assisted writing tools that balance automation with user agency.
Long and Short-Term Constraints Driven Safe Reinforcement Learning for Autonomous Driving
Mar 27, 2024



Reinforcement learning (RL) has been widely used in decision-making tasks, but it cannot guarantee the agent's safety in the training process due to the requirements of interaction with the environment, which seriously limits its industrial applications such as autonomous driving. Safe RL methods are developed to handle this issue by constraining the expected safety violation costs as a training objective, but they still permit unsafe state occurrence, which is unacceptable in autonomous driving tasks. Moreover, these methods are difficult to achieve a balance between the cost and return expectations, which leads to learning performance degradation for the algorithms. In this paper, we propose a novel algorithm based on the long and short-term constraints (LSTC) for safe RL. The short-term constraint aims to guarantee the short-term state safety that the vehicle explores, while the long-term constraint ensures the overall safety of the vehicle throughout the decision-making process. In addition, we develop a safe RL method with dual-constraint optimization based on the Lagrange multiplier to optimize the training process for end-to-end autonomous driving. Comprehensive experiments were conducted on the MetaDrive simulator. Experimental results demonstrate that the proposed method achieves higher safety in continuous state and action tasks, and exhibits higher exploration performance in long-distance decision-making tasks compared with state-of-the-art methods.
P2M2-Net: Part-Aware Prompt-Guided Multimodal Point Cloud Completion
Dec 29, 2023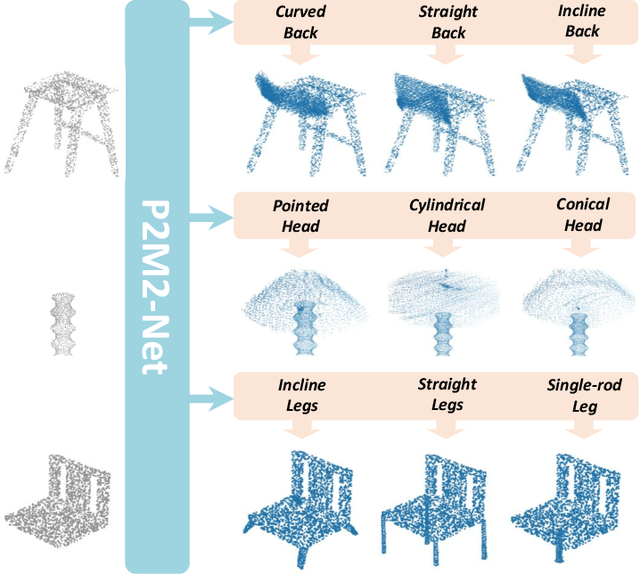
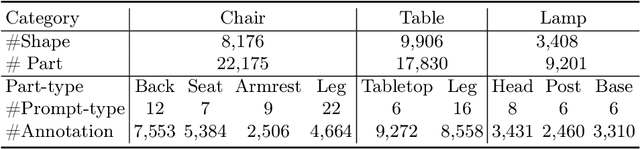
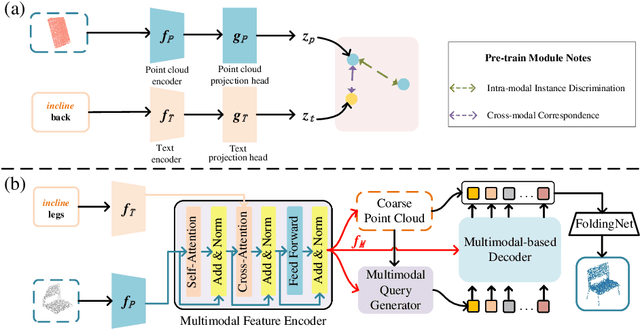
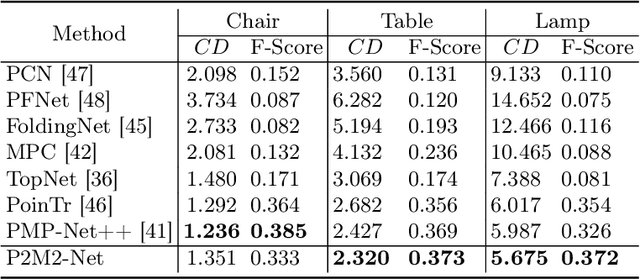
Inferring missing regions from severely occluded point clouds is highly challenging. Especially for 3D shapes with rich geometry and structure details, inherent ambiguities of the unknown parts are existing. Existing approaches either learn a one-to-one mapping in a supervised manner or train a generative model to synthesize the missing points for the completion of 3D point cloud shapes. These methods, however, lack the controllability for the completion process and the results are either deterministic or exhibiting uncontrolled diversity. Inspired by the prompt-driven data generation and editing, we propose a novel prompt-guided point cloud completion framework, coined P2M2-Net, to enable more controllable and more diverse shape completion. Given an input partial point cloud and a text prompt describing the part-aware information such as semantics and structure of the missing region, our Transformer-based completion network can efficiently fuse the multimodal features and generate diverse results following the prompt guidance. We train the P2M2-Net on a new large-scale PartNet-Prompt dataset and conduct extensive experiments on two challenging shape completion benchmarks. Quantitative and qualitative results show the efficacy of incorporating prompts for more controllable part-aware point cloud completion and generation. Code and data are available at https://github.com/JLU-ICL/P2M2-Net.
Opportunities for Adaptive Experiments to Enable Continuous Improvement that Trades-off Instructor and Researcher Incentives
Oct 18, 2023



Randomized experimental comparisons of alternative pedagogical strategies could provide useful empirical evidence in instructors' decision-making. However, traditional experiments do not have a clear and simple pathway to using data rapidly to try to increase the chances that students in an experiment get the best conditions. Drawing inspiration from the use of machine learning and experimentation in product development at leading technology companies, we explore how adaptive experimentation might help in continuous course improvement. In adaptive experiments, as different arms/conditions are deployed to students, data is analyzed and used to change the experience for future students. This can be done using machine learning algorithms to identify which actions are more promising for improving student experience or outcomes. This algorithm can then dynamically deploy the most effective conditions to future students, resulting in better support for students' needs. We illustrate the approach with a case study providing a side-by-side comparison of traditional and adaptive experimentation of self-explanation prompts in online homework problems in a CS1 course. This provides a first step in exploring the future of how this methodology can be useful in bridging research and practice in doing continuous improvement.
Parameter efficient dendritic-tree neurons outperform perceptrons
Jul 02, 2022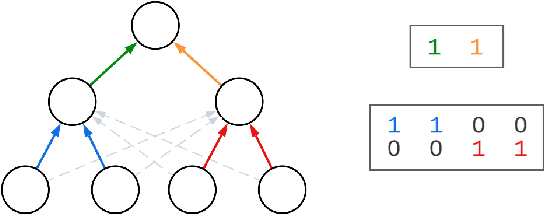


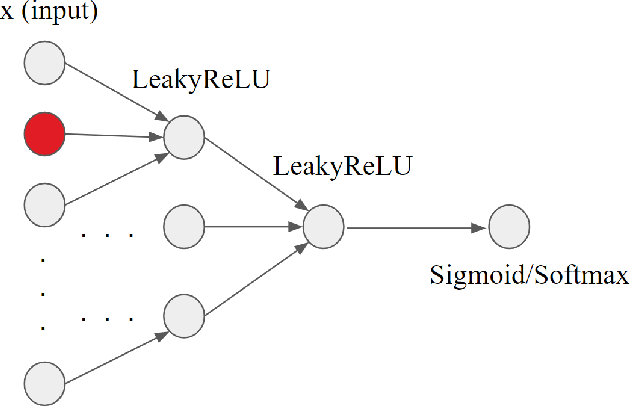
Biological neurons are more powerful than artificial perceptrons, in part due to complex dendritic input computations. Inspired to empower the perceptron with biologically inspired features, we explore the effect of adding and tuning input branching factors along with input dropout. This allows for parameter efficient non-linear input architectures to be discovered and benchmarked. Furthermore, we present a PyTorch module to replace multi-layer perceptron layers in existing architectures. Our initial experiments on MNIST classification demonstrate the accuracy and generalization improvement of dendritic neurons compared to existing perceptron architectures.
Statistical Consequences of Dueling Bandits
Oct 16, 2021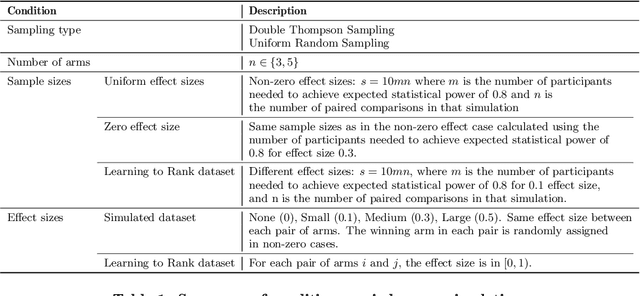
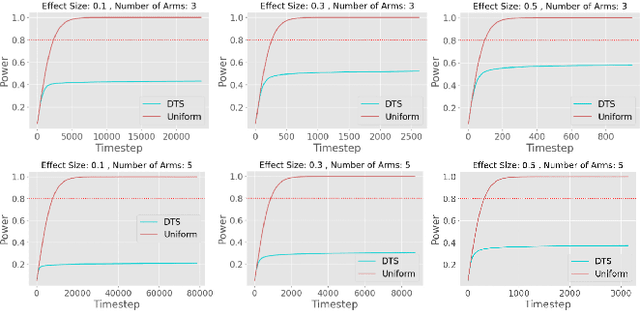
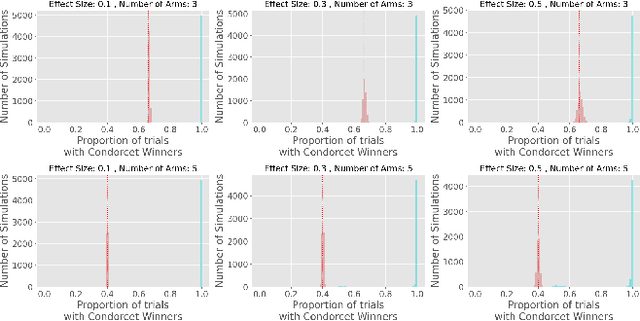
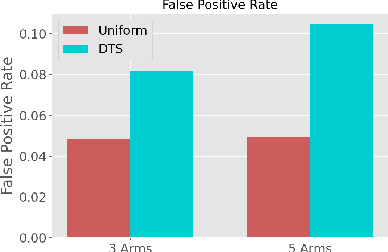
Multi-Armed-Bandit frameworks have often been used by researchers to assess educational interventions, however, recent work has shown that it is more beneficial for a student to provide qualitative feedback through preference elicitation between different alternatives, making a dueling bandits framework more appropriate. In this paper, we explore the statistical quality of data under this framework by comparing traditional uniform sampling to a dueling bandit algorithm and find that dueling bandit algorithms perform well at cumulative regret minimisation, but lead to inflated Type-I error rates and reduced power under certain circumstances. Through these results we provide insight into the challenges and opportunities in using dueling bandit algorithms to run adaptive experiments.
An Attention-Fused Network for Semantic Segmentation of Very-High-Resolution Remote Sensing Imagery
May 28, 2021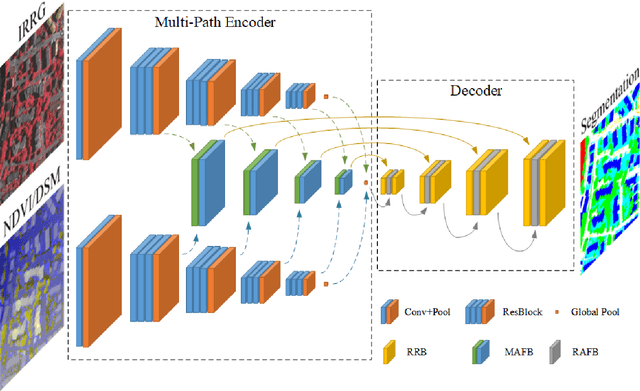
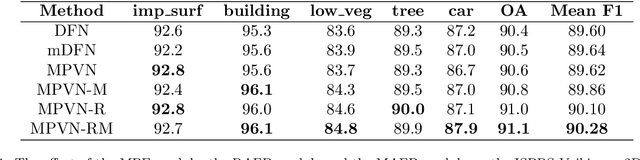
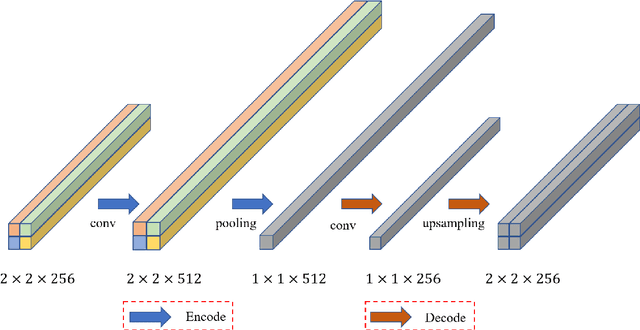
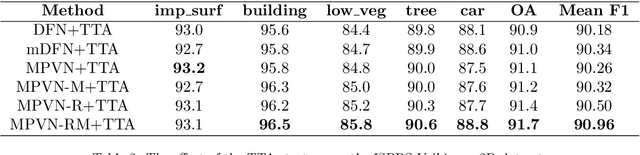
Semantic segmentation is an essential part of deep learning. In recent years, with the development of remote sensing big data, semantic segmentation has been increasingly used in remote sensing. Deep convolutional neural networks (DCNNs) face the challenge of feature fusion: very-high-resolution remote sensing image multisource data fusion can increase the network's learnable information, which is conducive to correctly classifying target objects by DCNNs; simultaneously, the fusion of high-level abstract features and low-level spatial features can improve the classification accuracy at the border between target objects. In this paper, we propose a multipath encoder structure to extract features of multipath inputs, a multipath attention-fused block module to fuse multipath features, and a refinement attention-fused block module to fuse high-level abstract features and low-level spatial features. Furthermore, we propose a novel convolutional neural network architecture, named attention-fused network (AFNet). Based on our AFNet, we achieve state-of-the-art performance with an overall accuracy of 91.7% and a mean F1 score of 90.96% on the ISPRS Vaihingen 2D dataset and an overall accuracy of 92.1% and a mean F1 score of 93.44% on the ISPRS Potsdam 2D dataset.
* 35 pages. Published by ISPRS Journal of Photogrammetry and Remote Sensing
FCCDN: Feature Constraint Network for VHR Image Change Detection
May 23, 2021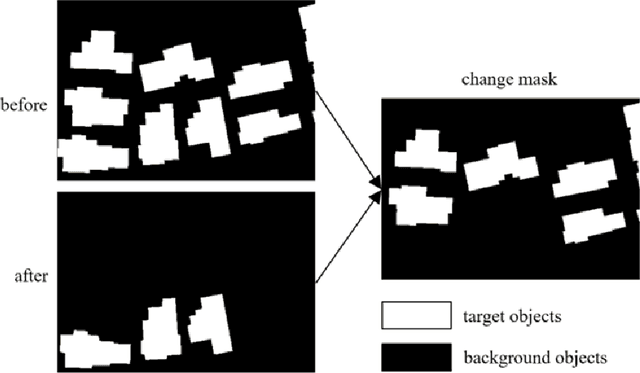

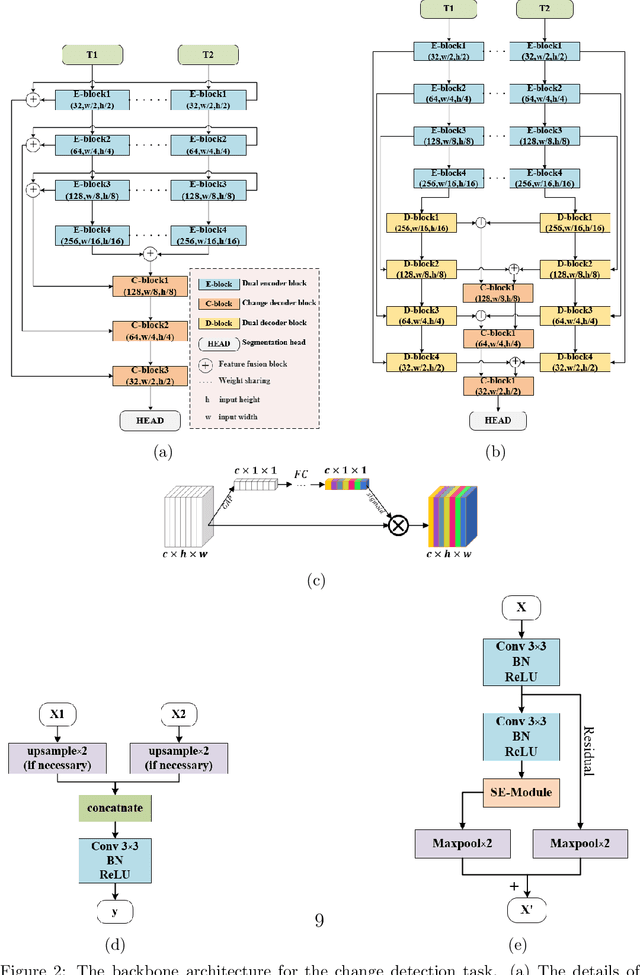
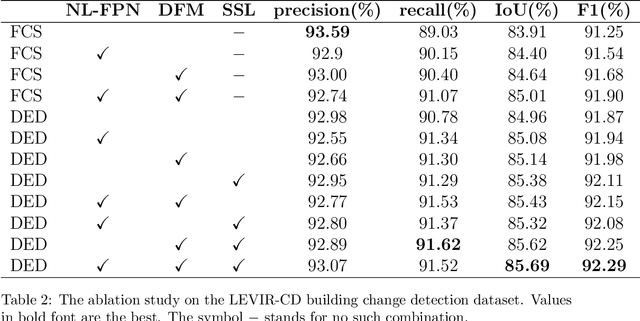
Change detection is the process of identifying pixel-wise differences of bi-temporal co-registered images. It is of great significance to Earth observation. Recently, with the emerging of deep learning (DL), deep convolutional neural networks (CNNs) based methods have shown their power and feasibility in the field of change detection. However, there is still a lack of effective supervision for change feature learning. In this work, a feature constraint change detection network (FCCDN) is proposed. We constrain features both on bi-temporal feature extraction and feature fusion. More specifically, we propose a dual encoder-decoder network backbone for the change detection task. At the center of the backbone, we design a non-local feature pyramid network to extract and fuse multi-scale features. To fuse bi-temporal features in a robust way, we build a dense connection-based feature fusion module. Moreover, a self-supervised learning-based strategy is proposed to constrain feature learning. Based on FCCDN, we achieve state-of-the-art performance on two building change detection datasets (LEVIR-CD and WHU). On the LEVIR-CD dataset, we achieve IoU of 0.8569 and F1 score of 0.9229. On the WHU dataset, we achieve IoU of 0.8820 and F1 score of 0.9373. Moreover, we, for the first time, achieve the acquire of accurate bi-temporal semantic segmentation results without using semantic segmentation labels. It is vital for the application of change detection because it saves the cost of labeling.
Acoustic anomaly detection via latent regularized gaussian mixture generative adversarial networks
Feb 05, 2020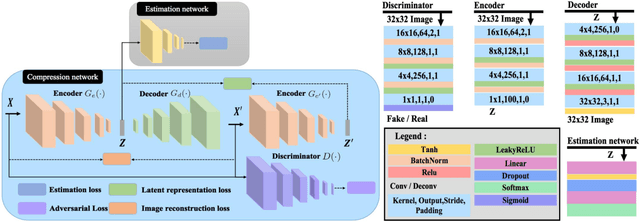
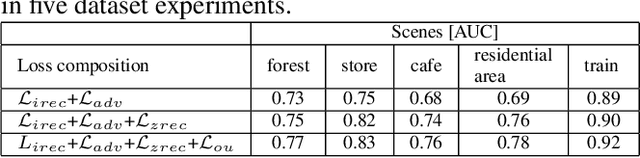
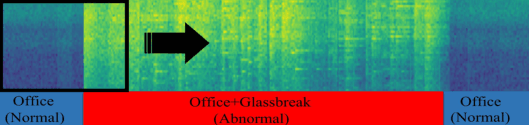
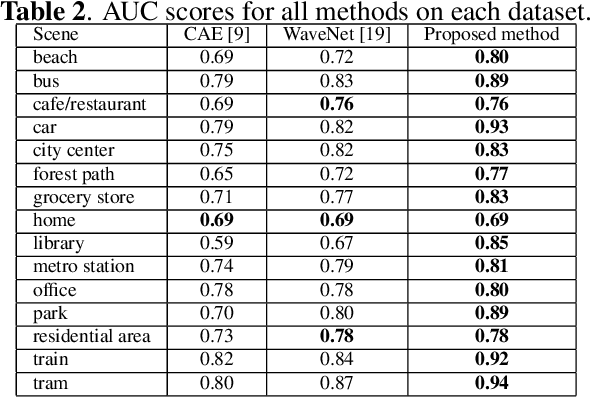
Acoustic anomaly detection aims at distinguishing abnormal acoustic signals from the normal ones. It suffers from the class imbalance issue and the lacking in the abnormal instances. In addition, collecting all kinds of abnormal or unknown samples for training purpose is impractical and timeconsuming. In this paper, a novel Gaussian Mixture Generative Adversarial Network (GMGAN) is proposed under semi-supervised learning framework, in which the underlying structure of training data is not only captured in spectrogram reconstruction space, but also can be further restricted in the space of latent representation in a discriminant manner. Experiments show that our model has clear superiority over previous methods, and achieves the state-of-the-art results on DCASE dataset.
Anomaly Detection by Latent Regularized Dual Adversarial Networks
Feb 05, 2020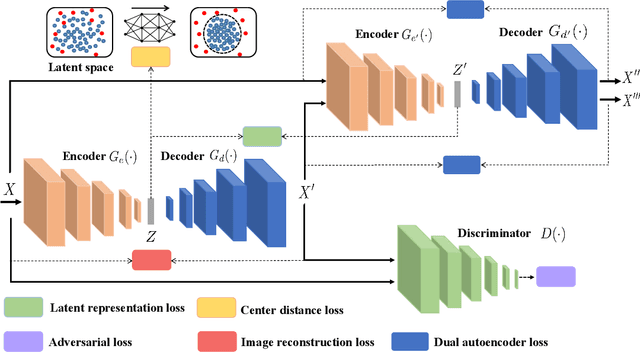
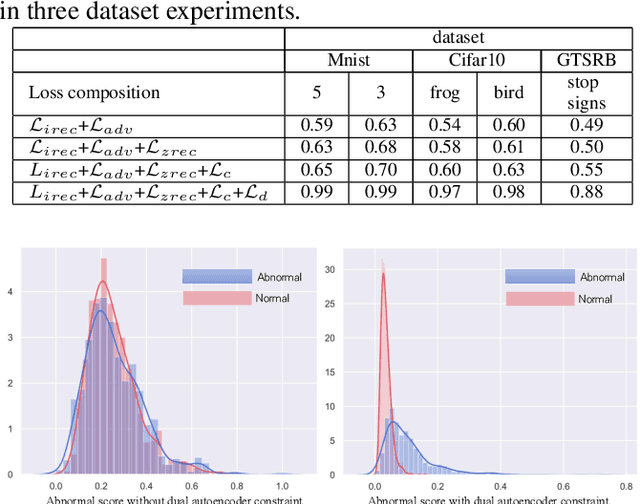
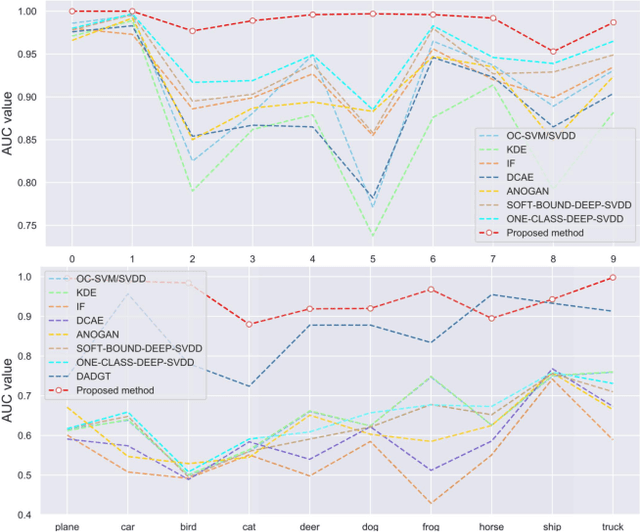
Anomaly detection is a fundamental problem in computer vision area with many real-world applications. Given a wide range of images belonging to the normal class, emerging from some distribution, the objective of this task is to construct the model to detect out-of-distribution images belonging to abnormal instances. Semi-supervised Generative Adversarial Networks (GAN)-based methods have been gaining popularity in anomaly detection task recently. However, the training process of GAN is still unstable and challenging. To solve these issues, a novel adversarial dual autoencoder network is proposed, in which the underlying structure of training data is not only captured in latent feature space, but also can be further restricted in the space of latent representation in a discriminant manner, leading to a more accurate detector. In addition, the auxiliary autoencoder regarded as a discriminator could obtain an more stable training process. Experiments show that our model achieves the state-of-the-art results on MNIST and CIFAR10 datasets as well as GTSRB stop signs dataset.