 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeed We Teach Foundation Models What is a Generative Image? Gradient-Free Generative Artifact Detection via Analytic Spectral Adaptation
Jun 03, 2026Adapting foundation models to detect generative artifacts via gradient-based updates compromises their intrinsic representations. Under optimization on limited samples, models overfit to local domain shortcuts. Fine-tuning massive weights on specialized data introduces erroneous inductive biases, inducing a measurable $\mathcal{L}_2$ norm perturbation in the high-dimensional feature space -- a phenomenon we formalize as anchor drift. Amplified by nonlinear activations, this drift impairs zero-shot forgery detection across unseen domains.We propose a gradient-free methodology reframing detection from binary classification to an out-of-distribution (OOD) anomaly measurement problem. Treating a frozen foundation model as a stable coordinate system, we establish an absolute natural anchor on the real visual manifold by analytically decoupling statistical and semantic deviations, derived from attention-weighted spatial moments and orthogonal projection of perceptual inconsistencies. Evaluated in an extreme zero-shot setting (trained on face forgeries, tested on universal Text-to-Image generations), our method significantly outperforms gradient-optimized paradigms. Backpropagation-free forward passes and linear solvers enable hardware-agnostic, edge-deployable calibration with minimal latency. Furthermore, the Sherman-Morrison formula unlocks instantaneous online learning against novel attacks and enables privacy-preserving federated collaboration via covariance delta transmission.
A Systematic Approach for Large Language Models Debugging
Apr 24, 2026Large language models (LLMs) have become central to modern AI workflows, powering applications from open-ended text generation to complex agent-based reasoning. However, debugging these models remains a persistent challenge due to their opaque and probabilistic nature and the difficulty of diagnosing errors across diverse tasks and settings. This paper introduces a systematic approach for LLM debugging that treats models as observable systems, providing structured, model-agnostic methods from issue detection to model refinement. By unifying evaluation, interpretability, and error-analysis practices, our approach enables practitioners to iteratively diagnose model weaknesses, refine prompts and model parameters, and adapt data for fine-tuning or assessment, while remaining effective in contexts where standardized benchmarks and evaluation criteria are lacking. We argue that such a structured methodology not only accelerates troubleshooting but also fosters reproducibility, transparency, and scalability in the deployment of LLM-based systems.
How Much Reasoning Do Retrieval-Augmented Models Add beyond LLMs? A Benchmarking Framework for Multi-Hop Inference over Hybrid Knowledge
Feb 10, 2026Large language models (LLMs) continue to struggle with knowledge-intensive questions that require up-to-date information and multi-hop reasoning. Augmenting LLMs with hybrid external knowledge, such as unstructured text and structured knowledge graphs, offers a promising alternative to costly continual pretraining. As such, reliable evaluation of their retrieval and reasoning capabilities becomes critical. However, many existing benchmarks increasingly overlap with LLM pretraining data, which means answers or supporting knowledge may already be encoded in model parameters, making it difficult to distinguish genuine retrieval and reasoning from parametric recall. We introduce HybridRAG-Bench, a framework for constructing benchmarks to evaluate retrieval-intensive, multi-hop reasoning over hybrid knowledge. HybridRAG-Bench automatically couples unstructured text and structured knowledge graph representations derived from recent scientific literature on arXiv, and generates knowledge-intensive question-answer pairs grounded in explicit reasoning paths. The framework supports flexible domain and time-frame selection, enabling contamination-aware and customizable evaluation as models and knowledge evolve. Experiments across three domains (artificial intelligence, governance and policy, and bioinformatics) demonstrate that HybridRAG-Bench rewards genuine retrieval and reasoning rather than parametric recall, offering a principled testbed for evaluating hybrid knowledge-augmented reasoning systems. We release our code and data at github.com/junhongmit/HybridRAG-Bench.
KANO: Kolmogorov-Arnold Neural Operator for Image Super-Resolution
Dec 28, 2025The highly nonlinear degradation process, complex physical interactions, and various sources of uncertainty render single-image Super-resolution (SR) a particularly challenging task. Existing interpretable SR approaches, whether based on prior learning or deep unfolding optimization frameworks, typically rely on black-box deep networks to model latent variables, which leaves the degradation process largely unknown and uncontrollable. Inspired by the Kolmogorov-Arnold theorem (KAT), we for the first time propose a novel interpretable operator, termed Kolmogorov-Arnold Neural Operator (KANO), with the application to image SR. KANO provides a transparent and structured representation of the latent degradation fitting process. Specifically, we employ an additive structure composed of a finite number of B-spline functions to approximate continuous spectral curves in a piecewise fashion. By learning and optimizing the shape parameters of these spline functions within defined intervals, our KANO accurately captures key spectral characteristics, such as local linear trends and the peak-valley structures at nonlinear inflection points, thereby endowing SR results with physical interpretability. Furthermore, through theoretical modeling and experimental evaluations across natural images, aerial photographs, and satellite remote sensing data, we systematically compare multilayer perceptrons (MLPs) and Kolmogorov-Arnold networks (KANs) in handling complex sequence fitting tasks. This comparative study elucidates the respective advantages and limitations of these models in characterizing intricate degradation mechanisms, offering valuable insights for the development of interpretable SR techniques.
CangLing-KnowFlow: A Unified Knowledge-and-Flow-fused Agent for Comprehensive Remote Sensing Applications
Dec 17, 2025The automated and intelligent processing of massive remote sensing (RS) datasets is critical in Earth observation (EO). Existing automated systems are normally task-specific, lacking a unified framework to manage diverse, end-to-end workflows--from data preprocessing to advanced interpretation--across diverse RS applications. To address this gap, this paper introduces CangLing-KnowFlow, a unified intelligent agent framework that integrates a Procedural Knowledge Base (PKB), Dynamic Workflow Adjustment, and an Evolutionary Memory Module. The PKB, comprising 1,008 expert-validated workflow cases across 162 practical RS tasks, guides planning and substantially reduces hallucinations common in general-purpose agents. During runtime failures, the Dynamic Workflow Adjustment autonomously diagnoses and replans recovery strategies, while the Evolutionary Memory Module continuously learns from these events, iteratively enhancing the agent's knowledge and performance. This synergy enables CangLing-KnowFlow to adapt, learn, and operate reliably across diverse, complex tasks. We evaluated CangLing-KnowFlow on the KnowFlow-Bench, a novel benchmark of 324 workflows inspired by real-world applications, testing its performance across 13 top Large Language Model (LLM) backbones, from open-source to commercial. Across all complex tasks, CangLing-KnowFlow surpassed the Reflexion baseline by at least 4% in Task Success Rate. As the first most comprehensive validation along this emerging field, this research demonstrates the great potential of CangLing-KnowFlow as a robust, efficient, and scalable automated solution for complex EO challenges by leveraging expert knowledge (Knowledge) into adaptive and verifiable procedures (Flow).
Large Model Empowered Embodied AI: A Survey on Decision-Making and Embodied Learning
Aug 14, 2025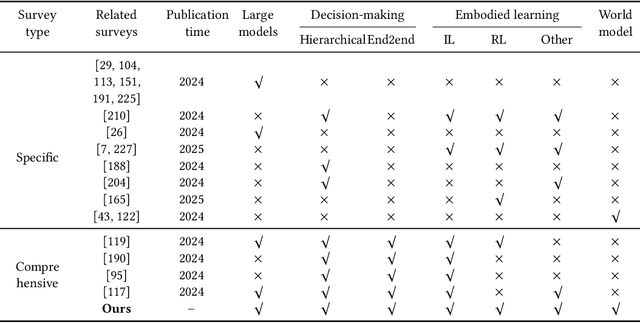
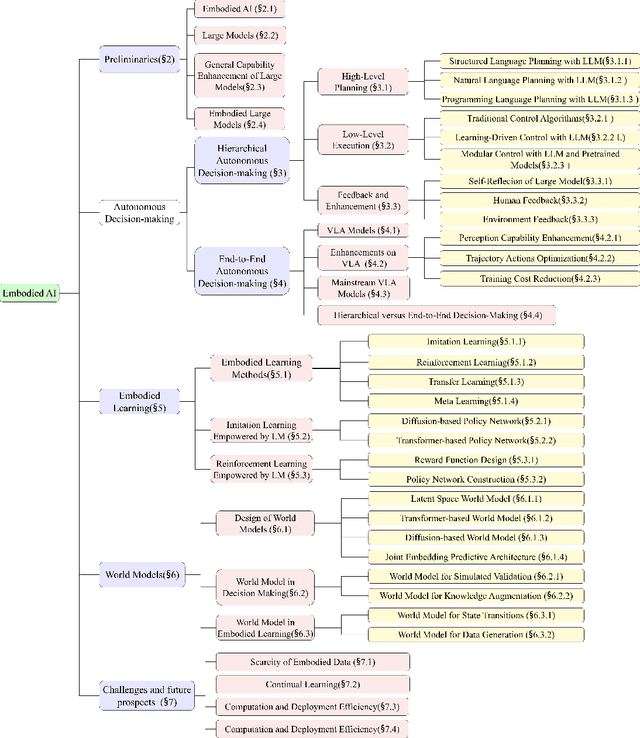
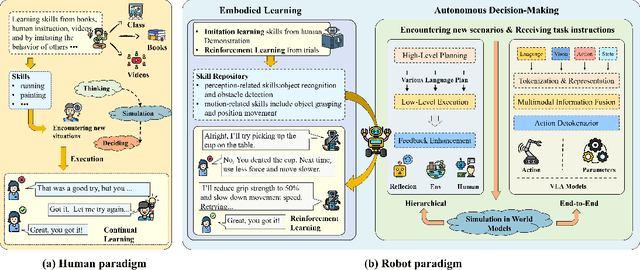
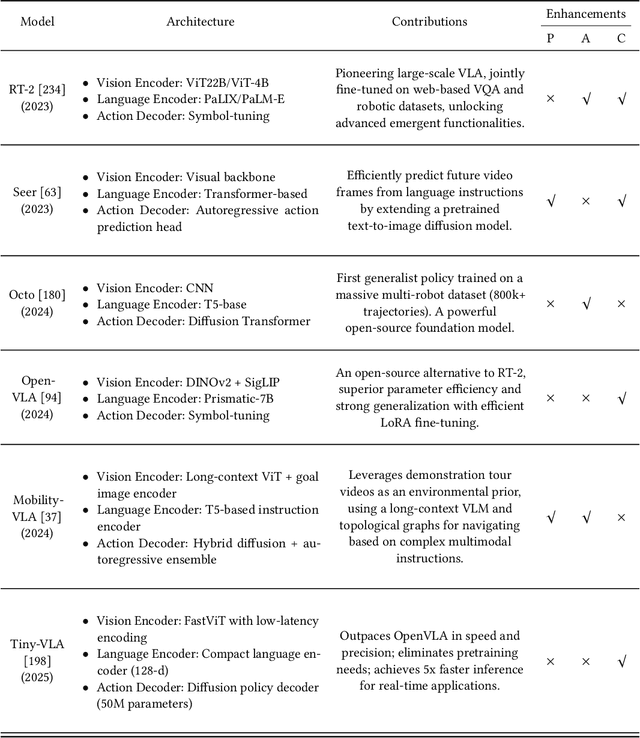
Embodied AI aims to develop intelligent systems with physical forms capable of perceiving, decision-making, acting, and learning in real-world environments, providing a promising way to Artificial General Intelligence (AGI). Despite decades of explorations, it remains challenging for embodied agents to achieve human-level intelligence for general-purpose tasks in open dynamic environments. Recent breakthroughs in large models have revolutionized embodied AI by enhancing perception, interaction, planning and learning. In this article, we provide a comprehensive survey on large model empowered embodied AI, focusing on autonomous decision-making and embodied learning. We investigate both hierarchical and end-to-end decision-making paradigms, detailing how large models enhance high-level planning, low-level execution, and feedback for hierarchical decision-making, and how large models enhance Vision-Language-Action (VLA) models for end-to-end decision making. For embodied learning, we introduce mainstream learning methodologies, elaborating on how large models enhance imitation learning and reinforcement learning in-depth. For the first time, we integrate world models into the survey of embodied AI, presenting their design methods and critical roles in enhancing decision-making and learning. Though solid advances have been achieved, challenges still exist, which are discussed at the end of this survey, potentially as the further research directions.
Hyperspectral Imaging
Aug 11, 2025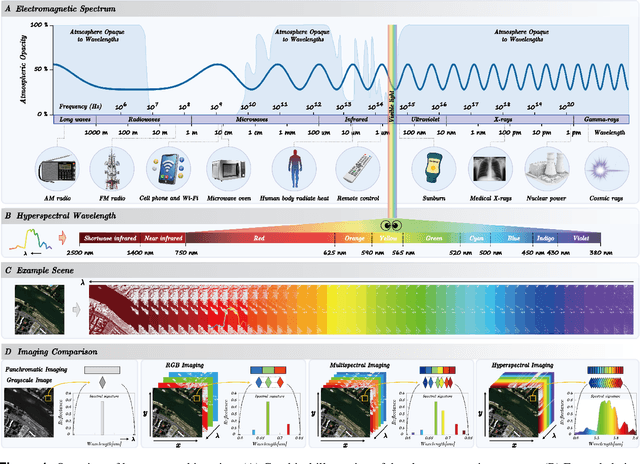
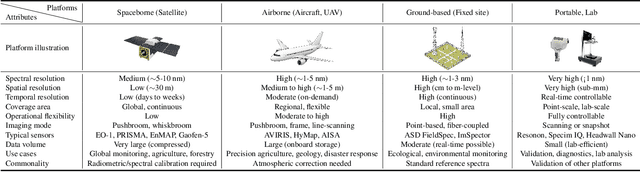
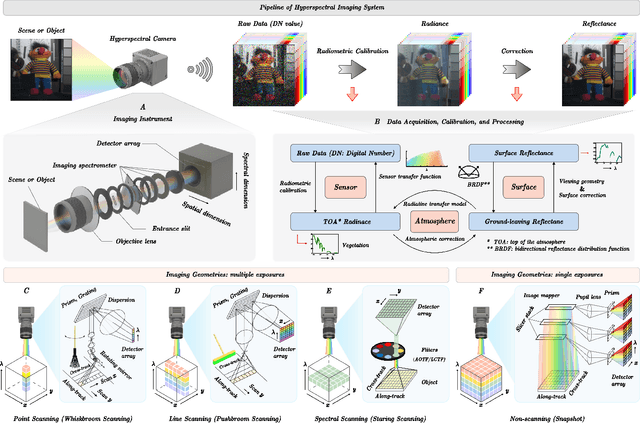

Hyperspectral imaging (HSI) is an advanced sensing modality that simultaneously captures spatial and spectral information, enabling non-invasive, label-free analysis of material, chemical, and biological properties. This Primer presents a comprehensive overview of HSI, from the underlying physical principles and sensor architectures to key steps in data acquisition, calibration, and correction. We summarize common data structures and highlight classical and modern analysis methods, including dimensionality reduction, classification, spectral unmixing, and AI-driven techniques such as deep learning. Representative applications across Earth observation, precision agriculture, biomedicine, industrial inspection, cultural heritage, and security are also discussed, emphasizing HSI's ability to uncover sub-visual features for advanced monitoring, diagnostics, and decision-making. Persistent challenges, such as hardware trade-offs, acquisition variability, and the complexity of high-dimensional data, are examined alongside emerging solutions, including computational imaging, physics-informed modeling, cross-modal fusion, and self-supervised learning. Best practices for dataset sharing, reproducibility, and metadata documentation are further highlighted to support transparency and reuse. Looking ahead, we explore future directions toward scalable, real-time, and embedded HSI systems, driven by sensor miniaturization, self-supervised learning, and foundation models. As HSI evolves into a general-purpose, cross-disciplinary platform, it holds promise for transformative applications in science, technology, and society.
UrbanSAM: Learning Invariance-Inspired Adapters for Segment Anything Models in Urban Construction
Feb 21, 2025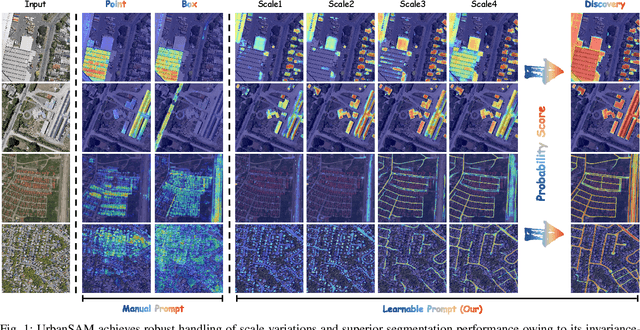
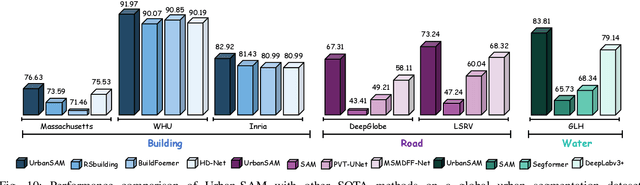
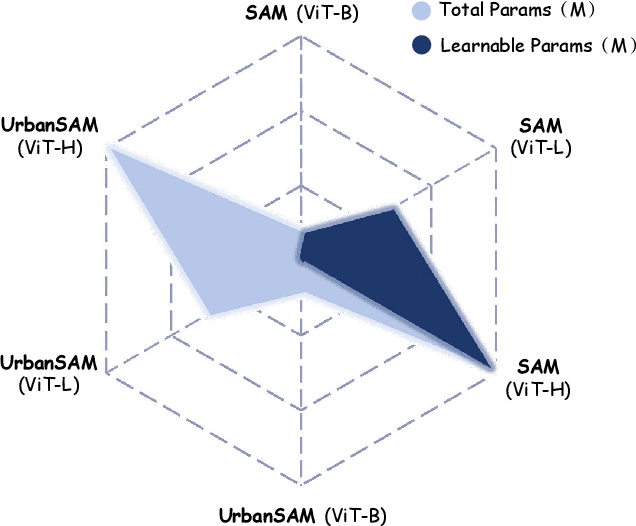
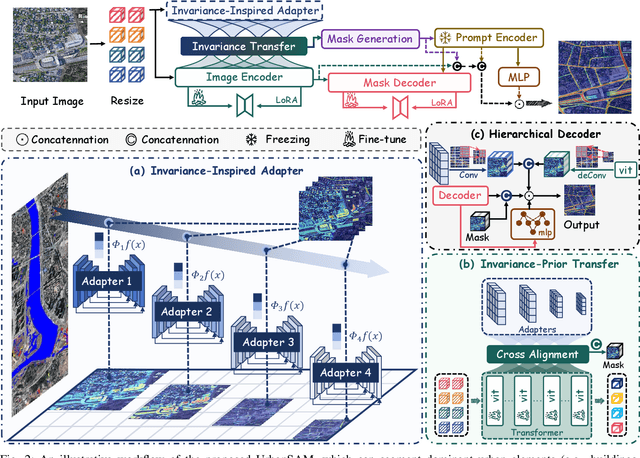
Object extraction and segmentation from remote sensing (RS) images is a critical yet challenging task in urban environment monitoring. Urban morphology is inherently complex, with irregular objects of diverse shapes and varying scales. These challenges are amplified by heterogeneity and scale disparities across RS data sources, including sensors, platforms, and modalities, making accurate object segmentation particularly demanding. While the Segment Anything Model (SAM) has shown significant potential in segmenting complex scenes, its performance in handling form-varying objects remains limited due to manual-interactive prompting. To this end, we propose UrbanSAM, a customized version of SAM specifically designed to analyze complex urban environments while tackling scaling effects from remotely sensed observations. Inspired by multi-resolution analysis (MRA) theory, UrbanSAM incorporates a novel learnable prompter equipped with a Uscaling-Adapter that adheres to the invariance criterion, enabling the model to capture multiscale contextual information of objects and adapt to arbitrary scale variations with theoretical guarantees. Furthermore, features from the Uscaling-Adapter and the trunk encoder are aligned through a masked cross-attention operation, allowing the trunk encoder to inherit the adapter's multiscale aggregation capability. This synergy enhances the segmentation performance, resulting in more powerful and accurate outputs, supported by the learned adapter. Extensive experimental results demonstrate the flexibility and superior segmentation performance of the proposed UrbanSAM on a global-scale dataset, encompassing scale-varying urban objects such as buildings, roads, and water.
Strategic priorities for transformative progress in advancing biology with proteomics and artificial intelligence
Feb 21, 2025

Artificial intelligence (AI) is transforming scientific research, including proteomics. Advances in mass spectrometry (MS)-based proteomics data quality, diversity, and scale, combined with groundbreaking AI techniques, are unlocking new challenges and opportunities in biological discovery. Here, we highlight key areas where AI is driving innovation, from data analysis to new biological insights. These include developing an AI-friendly ecosystem for proteomics data generation, sharing, and analysis; improving peptide and protein identification and quantification; characterizing protein-protein interactions and protein complexes; advancing spatial and perturbation proteomics; integrating multi-omics data; and ultimately enabling AI-empowered virtual cells.
Cloud Removal With PolSAR-Optical Data Fusion Using A Two-Flow Residual Network
Jan 14, 2025Optical remote sensing images play a crucial role in the observation of the Earth's surface. However, obtaining complete optical remote sensing images is challenging due to cloud cover. Reconstructing cloud-free optical images has become a major task in recent years. This paper presents a two-flow Polarimetric Synthetic Aperture Radar (PolSAR)-Optical data fusion cloud removal algorithm (PODF-CR), which achieves the reconstruction of missing optical images. PODF-CR consists of an encoding module and a decoding module. The encoding module includes two parallel branches that extract PolSAR image features and optical image features. To address speckle noise in PolSAR images, we introduce dynamic filters in the PolSAR branch for image denoising. To better facilitate the fusion between multimodal optical images and PolSAR images, we propose fusion blocks based on cross-skip connections to enable interaction of multimodal data information. The obtained fusion features are refined through an attention mechanism to provide better conditions for the subsequent decoding of the fused images. In the decoding module, multi-scale convolution is introduced to obtain multi-scale information. Additionally, to better utilize comprehensive scattering information and polarization characteristics to assist in the restoration of optical images, we use a dataset for cloud restoration called OPT-BCFSAR-PFSAR, which includes backscatter coefficient feature images and polarization feature images obtained from PoLSAR data and optical images. Experimental results demonstrate that this method outperforms existing methods in both qualitative and quantitative evaluations.