 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning multi-phase flow and transport in fractured porous media with auto-regressive and recurrent graph neural networks
Feb 22, 2025In the past three decades, a wide array of computational methodologies and simulation frameworks has emerged to address the complexities of modeling multi-phase flow and transport processes in fractured porous media. The conformal mesh approaches which explicitly align the computational grid with fracture surfaces are considered by many to be the most accurate. However, such methods require excessive fine-scale meshing, rendering them impractical for large or complex fracture networks. In this work, we propose to learn the complex multi-phase flow and transport dynamics in fractured porous media with graph neural networks (GNN). GNNs are well suited for this task due to the unstructured topology of the computation grid resulting from the Embedded Discrete Fracture Model (EDFM) discretization. We propose two deep learning architectures, a GNN and a recurrent GNN. Both networks follow a two-stage training strategy: an autoregressive one step roll-out, followed by a fine-tuning step where the model is supervised using the whole ground-truth sequence. We demonstrate that the two-stage training approach is effective in mitigating error accumulation during autoregressive model rollouts in the testing phase. Our findings indicate that both GNNs generalize well to unseen fracture realizations, with comparable performance in forecasting saturation sequences, and slightly better performance for the recurrent GNN in predicting pressure sequences. While the second stage of training proved to be beneficial for the GNN model, its impact on the recurrent GNN model was less pronounced. Finally, the performance of both GNNs for temporal extrapolation is tested. The recurrent GNN significantly outperformed the GNN in terms of accuracy, thereby underscoring its superior capability in predicting long sequences.
Cloud Removal With PolSAR-Optical Data Fusion Using A Two-Flow Residual Network
Jan 14, 2025Optical remote sensing images play a crucial role in the observation of the Earth's surface. However, obtaining complete optical remote sensing images is challenging due to cloud cover. Reconstructing cloud-free optical images has become a major task in recent years. This paper presents a two-flow Polarimetric Synthetic Aperture Radar (PolSAR)-Optical data fusion cloud removal algorithm (PODF-CR), which achieves the reconstruction of missing optical images. PODF-CR consists of an encoding module and a decoding module. The encoding module includes two parallel branches that extract PolSAR image features and optical image features. To address speckle noise in PolSAR images, we introduce dynamic filters in the PolSAR branch for image denoising. To better facilitate the fusion between multimodal optical images and PolSAR images, we propose fusion blocks based on cross-skip connections to enable interaction of multimodal data information. The obtained fusion features are refined through an attention mechanism to provide better conditions for the subsequent decoding of the fused images. In the decoding module, multi-scale convolution is introduced to obtain multi-scale information. Additionally, to better utilize comprehensive scattering information and polarization characteristics to assist in the restoration of optical images, we use a dataset for cloud restoration called OPT-BCFSAR-PFSAR, which includes backscatter coefficient feature images and polarization feature images obtained from PoLSAR data and optical images. Experimental results demonstrate that this method outperforms existing methods in both qualitative and quantitative evaluations.
RSGaussian:3D Gaussian Splatting with LiDAR for Aerial Remote Sensing Novel View Synthesis
Dec 24, 2024



This study presents RSGaussian, an innovative novel view synthesis (NVS) method for aerial remote sensing scenes that incorporate LiDAR point cloud as constraints into the 3D Gaussian Splatting method, which ensures that Gaussians grow and split along geometric benchmarks, addressing the overgrowth and floaters issues occurs. Additionally, the approach introduces coordinate transformations with distortion parameters for camera models to achieve pixel-level alignment between LiDAR point clouds and 2D images, facilitating heterogeneous data fusion and achieving the high-precision geo-alignment required in aerial remote sensing. Depth and plane consistency losses are incorporated into the loss function to guide Gaussians towards real depth and plane representations, significantly improving depth estimation accuracy. Experimental results indicate that our approach has achieved novel view synthesis that balances photo-realistic visual quality and high-precision geometric estimation under aerial remote sensing datasets. Finally, we have also established and open-sourced a dense LiDAR point cloud dataset along with its corresponding aerial multi-view images, AIR-LONGYAN.
Dissecting users' needs for search result explanations
Jan 29, 2024
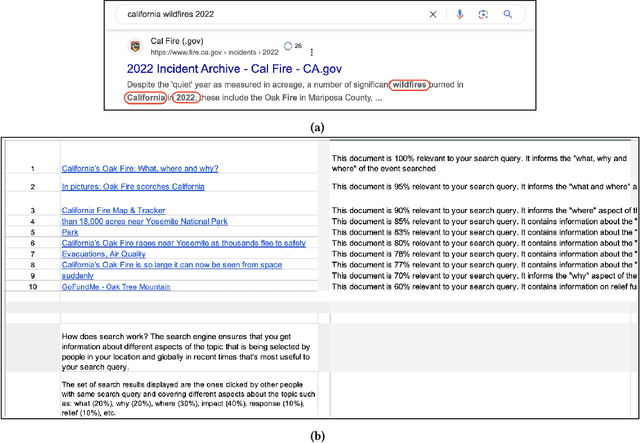
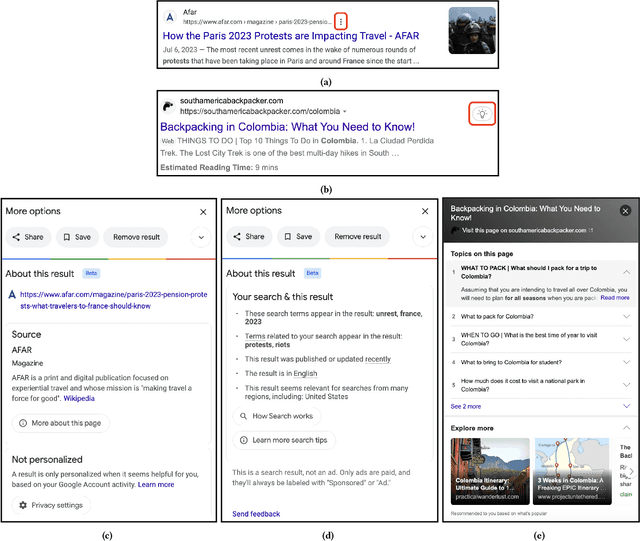
There is a growing demand for transparency in search engines to understand how search results are curated and to enhance users' trust. Prior research has introduced search result explanations with a focus on how to explain, assuming explanations are beneficial. Our study takes a step back to examine if search explanations are needed and when they are likely to provide benefits. Additionally, we summarize key characteristics of helpful explanations and share users' perspectives on explanation features provided by Google and Bing. Interviews with non-technical individuals reveal that users do not always seek or understand search explanations and mostly desire them for complex and critical tasks. They find Google's search explanations too obvious but appreciate the ability to contest search results. Based on our findings, we offer design recommendations for search engines and explanations to help users better evaluate search results and enhance their search experience.
Harnessing the Power of LLMs: Evaluating Human-AI Text Co-Creation through the Lens of News Headline Generation
Oct 18, 2023



To explore how humans can best leverage LLMs for writing and how interacting with these models affects feelings of ownership and trust in the writing process, we compared common human-AI interaction types (e.g., guiding system, selecting from system outputs, post-editing outputs) in the context of LLM-assisted news headline generation. While LLMs alone can generate satisfactory news headlines, on average, human control is needed to fix undesirable model outputs. Of the interaction methods, guiding and selecting model output added the most benefit with the lowest cost (in time and effort). Further, AI assistance did not harm participants' perception of control compared to freeform editing.
An Exploration of Post-Editing Effectiveness in Text Summarization
Jun 13, 2022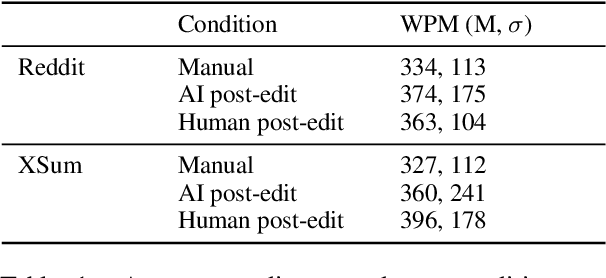
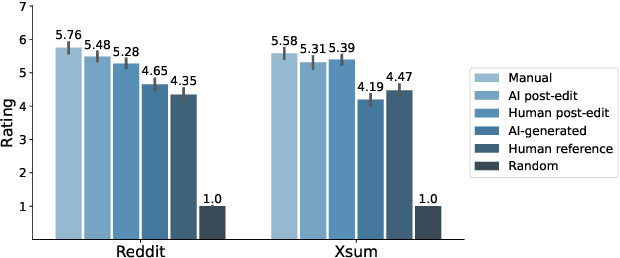

Automatic summarization methods are efficient but can suffer from low quality. In comparison, manual summarization is expensive but produces higher quality. Can humans and AI collaborate to improve summarization performance? In similar text generation tasks (e.g., machine translation), human-AI collaboration in the form of "post-editing" AI-generated text reduces human workload and improves the quality of AI output. Therefore, we explored whether post-editing offers advantages in text summarization. Specifically, we conducted an experiment with 72 participants, comparing post-editing provided summaries with manual summarization for summary quality, human efficiency, and user experience on formal (XSum news) and informal (Reddit posts) text. This study sheds valuable insights on when post-editing is useful for text summarization: it helped in some cases (e.g., when participants lacked domain knowledge) but not in others (e.g., when provided summaries include inaccurate information). Participants' different editing strategies and needs for assistance offer implications for future human-AI summarization systems.