 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-agent rendezvous in fluid flows via reinforcement learning
Jun 09, 2026Rendezvous is a critical task for multi-agent systems, requiring agents to coordinate to meet at an unspecified location. However, achieving this in fluid environments presents a challenge, as it remains unclear how agents can exploit underlying fluid kinematics to facilitate convergence. In this study, we adopt a multi-agent reinforcement learning (MARL) approach to develop physics-informed rendezvous strategies in vortical flows. Compared to a naive strategy, where agents navigate toward their counterparts, MARL strategies significantly improve the rendezvous rate. MARL strategies also show transferability across varying vortex intensities, vortex scales, and swarm sizes. By breaking the symmetry of the state-action map, MARL strategy leverages a non-intuitive mechanism that prevents agents from becoming trapped in separate vortices, thereby enhancing rendezvous success. Additionally, a heuristic strategy is extracted from the learned strategy and also outperforms the naive strategy. Furthermore, a theoretical analysis demonstrates that fluid deformation impedes the rendezvous process. Large finite-time Lyapunov exponents identify where fluid effects separate adjacent agents, suggesting that targets should be planned in weak-deformation regions. Our findings reveal the important role that agent-fluid interactions play in multi-agent tasks and highlight the MARL capability to explore swarm intelligence in complex flow environments.
GEAR: Geography-knowledge Enhanced Analog Recognition Framework in Extreme Environments
Mar 19, 2026The Mariana Trench and the Qinghai-Tibet Plateau exhibit significant similarities in geological origins and microbial metabolic functions. Given that deep-sea biological sampling faces prohibitive costs, recognizing structurally homologous terrestrial analogs of the Mariana Trench on the Qinghai-Tibet Plateau is of great significance. Yet, no existing model adequately addresses cross-domain topographic similarity retrieval, either neglecting geographical knowledge or sacrificing computational efficiency. To address these challenges, we present \underline{\textbf{G}}eography-knowledge \underline{\textbf{E}}nhanced \underline{\textbf{A}}nalog \underline{\textbf{R}}ecognition (\textbf{GEAR}) Framework, a three-stage pipeline designed to efficiently retrieve analogs from 2.5 million square kilometers of the Qinghai-Tibet Plateau: (1) Skeleton guided Screening and Clipping: Recognition of candidate valleys and initial screening based on size and linear morphological criteria. (2) Physics aware Filtering: The Topographic Waveform Comparator (TWC) and Morphological Texture Module (MTM) evaluate the waveform and texture and filter out inconsistent candidate valleys. (3) Graph based Fine Recognition: We design a \underline{\textbf{M}}orphology-integrated \underline{\textbf{S}}iamese \underline{\textbf{G}}raph \underline{\textbf{N}}etwork (\textbf{MSG-Net}) based on geomorphological metrics. Correspondingly, we release an expert-annotated topographic similarity dataset targeting tectonic collision zones. Experiments demonstrate the effectiveness of every stage. Besides, MSG-Net achieved an F1-Score 1.38 percentage points higher than the SOTA baseline. Using features extracted by MSG-Net, we discovered a significant correlation with biological data, providing evidence for future biological analysis.
Learning Native Continuation for Action Chunking Flow Policies
Feb 13, 2026Action chunking enables Vision Language Action (VLA) models to run in real time, but naive chunked execution often exhibits discontinuities at chunk boundaries. Real-Time Chunking (RTC) alleviates this issue but is external to the policy, leading to spurious multimodal switching and trajectories that are not intrinsically smooth. We propose Legato, a training-time continuation method for action-chunked flow-based VLA policies. Specifically, Legato initializes denoising from a schedule-shaped mixture of known actions and noise, exposing the model to partial action information. Moreover, Legato reshapes the learned flow dynamics to ensure that the denoising process remains consistent between training and inference under per-step guidance. Legato further uses randomized schedule condition during training to support varying inference delays and achieve controllable smoothness. Empirically, Legato produces smoother trajectories and reduces spurious multimodal switching during execution, leading to less hesitation and shorter task completion time. Extensive real-world experiments show that Legato consistently outperforms RTC across five manipulation tasks, achieving approximately 10% improvements in both trajectory smoothness and task completion time.
Unifying Continuous and Discrete Text Diffusion with Non-simultaneous Diffusion Processes
May 28, 2025Diffusion models have emerged as a promising approach for text generation, with recent works falling into two main categories: discrete and continuous diffusion models. Discrete diffusion models apply token corruption independently using categorical distributions, allowing for different diffusion progress across tokens but lacking fine-grained control. Continuous diffusion models map tokens to continuous spaces and apply fine-grained noise, but the diffusion progress is uniform across tokens, limiting their ability to capture semantic nuances. To address these limitations, we propose \textbf{\underline{N}}on-simultan\textbf{\underline{e}}ous C\textbf{\underline{o}}ntinuous \textbf{\underline{Diff}}usion Models (NeoDiff), a novel diffusion model that integrates the strengths of both discrete and continuous approaches. NeoDiff introduces a Poisson diffusion process for the forward process, enabling a flexible and fine-grained noising paradigm, and employs a time predictor for the reverse process to adaptively modulate the denoising progress based on token semantics. Furthermore, NeoDiff utilizes an optimized schedule for inference to ensure more precise noise control and improved performance. Our approach unifies the theories of discrete and continuous diffusion models, offering a more principled and effective framework for text generation. Experimental results on several text generation tasks demonstrate NeoDiff's superior performance compared to baselines of non-autoregressive continuous and discrete diffusion models, iterative-based methods and autoregressive diffusion-based methods. These results highlight NeoDiff's potential as a powerful tool for generating high-quality text and advancing the field of diffusion-based text generation.
RSGaussian:3D Gaussian Splatting with LiDAR for Aerial Remote Sensing Novel View Synthesis
Dec 24, 2024



This study presents RSGaussian, an innovative novel view synthesis (NVS) method for aerial remote sensing scenes that incorporate LiDAR point cloud as constraints into the 3D Gaussian Splatting method, which ensures that Gaussians grow and split along geometric benchmarks, addressing the overgrowth and floaters issues occurs. Additionally, the approach introduces coordinate transformations with distortion parameters for camera models to achieve pixel-level alignment between LiDAR point clouds and 2D images, facilitating heterogeneous data fusion and achieving the high-precision geo-alignment required in aerial remote sensing. Depth and plane consistency losses are incorporated into the loss function to guide Gaussians towards real depth and plane representations, significantly improving depth estimation accuracy. Experimental results indicate that our approach has achieved novel view synthesis that balances photo-realistic visual quality and high-precision geometric estimation under aerial remote sensing datasets. Finally, we have also established and open-sourced a dense LiDAR point cloud dataset along with its corresponding aerial multi-view images, AIR-LONGYAN.
Addressing Representation Collapse in Vector Quantized Models with One Linear Layer
Nov 04, 2024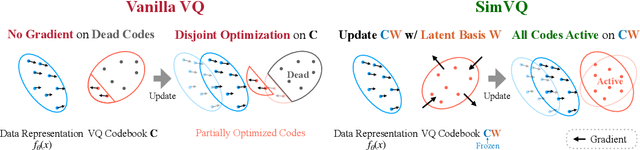
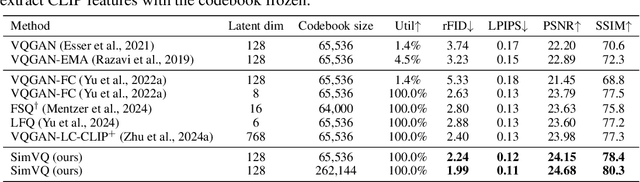
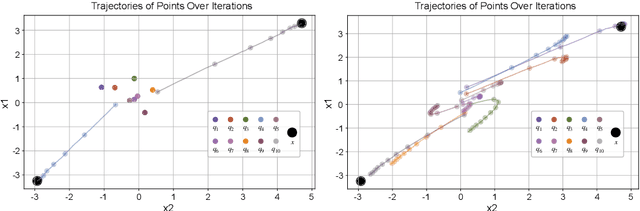
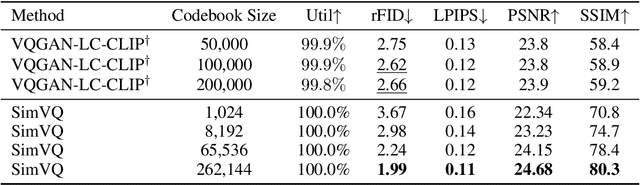
Vector Quantization (VQ) is a widely used method for converting continuous representations into discrete codes, which has become fundamental in unsupervised representation learning and latent generative models. However, VQ models are often hindered by the problem of representation collapse in the latent space, which leads to low codebook utilization and limits the scalability of the codebook for large-scale training. Existing methods designed to mitigate representation collapse typically reduce the dimensionality of latent space at the expense of model capacity, which do not fully resolve the core issue. In this study, we conduct a theoretical analysis of representation collapse in VQ models and identify its primary cause as the disjoint optimization of the codebook, where only a small subset of code vectors are updated through gradient descent. To address this issue, we propose \textbf{SimVQ}, a novel method which reparameterizes the code vectors through a linear transformation layer based on a learnable latent basis. This transformation optimizes the \textit{entire linear space} spanned by the codebook, rather than merely updating \textit{the code vector} selected by the nearest-neighbor search in vanilla VQ models. Although it is commonly understood that the multiplication of two linear matrices is equivalent to applying a single linear layer, our approach works surprisingly well in resolving the collapse issue in VQ models with just one linear layer. We validate the efficacy of SimVQ through extensive experiments across various modalities, including image and audio data with different model architectures. Our code is available at \url{https://github.com/youngsheen/SimVQ}.
Stabilize the Latent Space for Image Autoregressive Modeling: A Unified Perspective
Oct 16, 2024


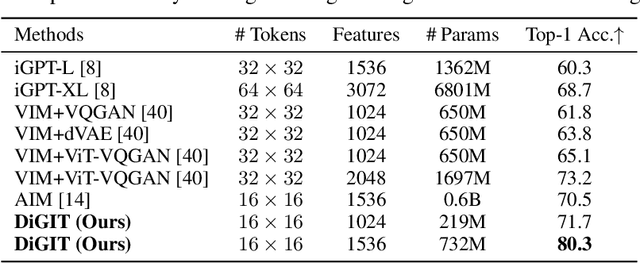
Latent-based image generative models, such as Latent Diffusion Models (LDMs) and Mask Image Models (MIMs), have achieved notable success in image generation tasks. These models typically leverage reconstructive autoencoders like VQGAN or VAE to encode pixels into a more compact latent space and learn the data distribution in the latent space instead of directly from pixels. However, this practice raises a pertinent question: Is it truly the optimal choice? In response, we begin with an intriguing observation: despite sharing the same latent space, autoregressive models significantly lag behind LDMs and MIMs in image generation. This finding contrasts sharply with the field of NLP, where the autoregressive model GPT has established a commanding presence. To address this discrepancy, we introduce a unified perspective on the relationship between latent space and generative models, emphasizing the stability of latent space in image generative modeling. Furthermore, we propose a simple but effective discrete image tokenizer to stabilize the latent space for image generative modeling. Experimental results show that image autoregressive modeling with our tokenizer (DiGIT) benefits both image understanding and image generation with the next token prediction principle, which is inherently straightforward for GPT models but challenging for other generative models. Remarkably, for the first time, a GPT-style autoregressive model for images outperforms LDMs, which also exhibits substantial improvement akin to GPT when scaling up model size. Our findings underscore the potential of an optimized latent space and the integration of discrete tokenization in advancing the capabilities of image generative models. The code is available at \url{https://github.com/DAMO-NLP-SG/DiGIT}.