 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecGPT-V2 Technical Report
Dec 16, 2025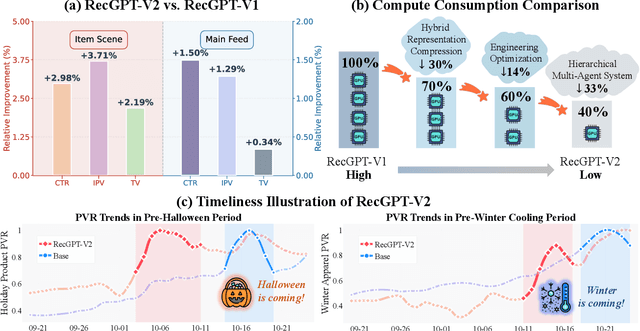
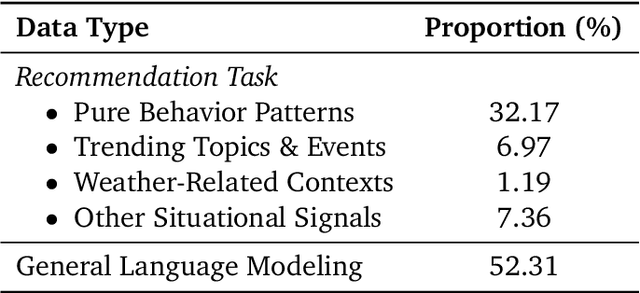
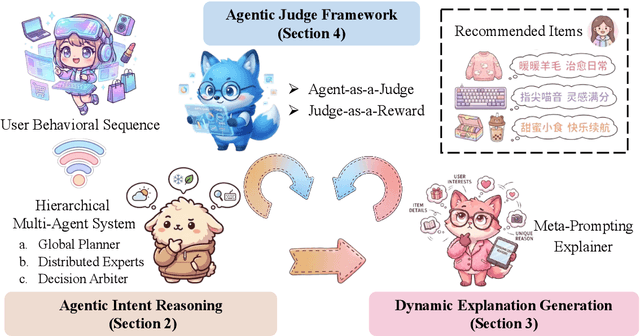

Large language models (LLMs) have demonstrated remarkable potential in transforming recommender systems from implicit behavioral pattern matching to explicit intent reasoning. While RecGPT-V1 successfully pioneered this paradigm by integrating LLM-based reasoning into user interest mining and item tag prediction, it suffers from four fundamental limitations: (1) computational inefficiency and cognitive redundancy across multiple reasoning routes; (2) insufficient explanation diversity in fixed-template generation; (3) limited generalization under supervised learning paradigms; and (4) simplistic outcome-focused evaluation that fails to match human standards. To address these challenges, we present RecGPT-V2 with four key innovations. First, a Hierarchical Multi-Agent System restructures intent reasoning through coordinated collaboration, eliminating cognitive duplication while enabling diverse intent coverage. Combined with Hybrid Representation Inference that compresses user-behavior contexts, our framework reduces GPU consumption by 60% and improves exclusive recall from 9.39% to 10.99%. Second, a Meta-Prompting framework dynamically generates contextually adaptive prompts, improving explanation diversity by +7.3%. Third, constrained reinforcement learning mitigates multi-reward conflicts, achieving +24.1% improvement in tag prediction and +13.0% in explanation acceptance. Fourth, an Agent-as-a-Judge framework decomposes assessment into multi-step reasoning, improving human preference alignment. Online A/B tests on Taobao demonstrate significant improvements: +2.98% CTR, +3.71% IPV, +2.19% TV, and +11.46% NER. RecGPT-V2 establishes both the technical feasibility and commercial viability of deploying LLM-powered intent reasoning at scale, bridging the gap between cognitive exploration and industrial utility.
RecGPT Technical Report
Jul 30, 2025



Recommender systems are among the most impactful applications of artificial intelligence, serving as critical infrastructure connecting users, merchants, and platforms. However, most current industrial systems remain heavily reliant on historical co-occurrence patterns and log-fitting objectives, i.e., optimizing for past user interactions without explicitly modeling user intent. This log-fitting approach often leads to overfitting to narrow historical preferences, failing to capture users' evolving and latent interests. As a result, it reinforces filter bubbles and long-tail phenomena, ultimately harming user experience and threatening the sustainability of the whole recommendation ecosystem. To address these challenges, we rethink the overall design paradigm of recommender systems and propose RecGPT, a next-generation framework that places user intent at the center of the recommendation pipeline. By integrating large language models (LLMs) into key stages of user interest mining, item retrieval, and explanation generation, RecGPT transforms log-fitting recommendation into an intent-centric process. To effectively align general-purpose LLMs to the above domain-specific recommendation tasks at scale, RecGPT incorporates a multi-stage training paradigm, which integrates reasoning-enhanced pre-alignment and self-training evolution, guided by a Human-LLM cooperative judge system. Currently, RecGPT has been fully deployed on the Taobao App. Online experiments demonstrate that RecGPT achieves consistent performance gains across stakeholders: users benefit from increased content diversity and satisfaction, merchants and the platform gain greater exposure and conversions. These comprehensive improvement results across all stakeholders validates that LLM-driven, intent-centric design can foster a more sustainable and mutually beneficial recommendation ecosystem.
Unifying Continuous and Discrete Text Diffusion with Non-simultaneous Diffusion Processes
May 28, 2025Diffusion models have emerged as a promising approach for text generation, with recent works falling into two main categories: discrete and continuous diffusion models. Discrete diffusion models apply token corruption independently using categorical distributions, allowing for different diffusion progress across tokens but lacking fine-grained control. Continuous diffusion models map tokens to continuous spaces and apply fine-grained noise, but the diffusion progress is uniform across tokens, limiting their ability to capture semantic nuances. To address these limitations, we propose \textbf{\underline{N}}on-simultan\textbf{\underline{e}}ous C\textbf{\underline{o}}ntinuous \textbf{\underline{Diff}}usion Models (NeoDiff), a novel diffusion model that integrates the strengths of both discrete and continuous approaches. NeoDiff introduces a Poisson diffusion process for the forward process, enabling a flexible and fine-grained noising paradigm, and employs a time predictor for the reverse process to adaptively modulate the denoising progress based on token semantics. Furthermore, NeoDiff utilizes an optimized schedule for inference to ensure more precise noise control and improved performance. Our approach unifies the theories of discrete and continuous diffusion models, offering a more principled and effective framework for text generation. Experimental results on several text generation tasks demonstrate NeoDiff's superior performance compared to baselines of non-autoregressive continuous and discrete diffusion models, iterative-based methods and autoregressive diffusion-based methods. These results highlight NeoDiff's potential as a powerful tool for generating high-quality text and advancing the field of diffusion-based text generation.
DiffS2UT: A Semantic Preserving Diffusion Model for Textless Direct Speech-to-Speech Translation
Oct 26, 2023



While Diffusion Generative Models have achieved great success on image generation tasks, how to efficiently and effectively incorporate them into speech generation especially translation tasks remains a non-trivial problem. Specifically, due to the low information density of speech data, the transformed discrete speech unit sequence is much longer than the corresponding text transcription, posing significant challenges to existing auto-regressive models. Furthermore, it is not optimal to brutally apply discrete diffusion on the speech unit sequence while disregarding the continuous space structure, which will degrade the generation performance significantly. In this paper, we propose a novel diffusion model by applying the diffusion forward process in the \textit{continuous} speech representation space, while employing the diffusion backward process in the \textit{discrete} speech unit space. In this way, we preserve the semantic structure of the continuous speech representation space in the diffusion process and integrate the continuous and discrete diffusion models. We conduct extensive experiments on the textless direct speech-to-speech translation task, where the proposed method achieves comparable results to the computationally intensive auto-regressive baselines (500 steps on average) with significantly fewer decoding steps (50 steps).
Difformer: Empowering Diffusion Model on Embedding Space for Text Generation
Dec 19, 2022



Diffusion models have achieved state-of-the-art synthesis quality on visual and audio tasks, and recent works adapt them to textual data by diffusing on the embedding space. But the difference between the continuous data space and the embedding space raises challenges to the diffusion model, which have not been carefully explored. In this paper, we conduct systematic studies and analyze the challenges threefold. Firstly, the data distribution is learnable for embeddings, which may lead to the collapse of the loss function. Secondly, as the norm of embedding varies between popular and rare words, adding the same noise scale will lead to sub-optimal results. In addition, we find that noises sampled from a standard Gaussian distribution may distract the diffusion process. To solve the above challenges, we propose Difformer, a denoising diffusion probabilistic model based on Transformer, which consists of three techniques including utilizing an anchor loss function, a layer normalization module for embeddings, and a norm factor to the Gaussian noise. All techniques are complementary to each other and critical to boosting the model performance together. Experiments are conducted on benchmark datasets over two seminal text generation tasks including machine translation and text summarization. The results show that Difformer significantly outperforms the embedding diffusion baselines, while achieving competitive results with strong autoregressive baselines.