 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKARMA: A Multilevel Decomposition Hybrid Mamba Framework for Multivariate Long-Term Time Series Forecasting
Jun 10, 2025Multivariate long-term and efficient time series forecasting is a key requirement for a variety of practical applications, and there are complex interleaving time dynamics in time series data that require decomposition modeling. Traditional time series decomposition methods are single and rely on fixed rules, which are insufficient for mining the potential information of the series and adapting to the dynamic characteristics of complex series. On the other hand, the Transformer-based models for time series forecasting struggle to effectively model long sequences and intricate dynamic relationships due to their high computational complexity. To overcome these limitations, we introduce KARMA, with an Adaptive Time Channel Decomposition module (ATCD) to dynamically extract trend and seasonal components. It further integrates a Hybrid Frequency-Time Decomposition module (HFTD) to further decompose Series into frequency-domain and time-domain. These components are coupled with multi-scale Mamba-based KarmaBlock to efficiently process global and local information in a coordinated manner. Experiments on eight real-world datasets from diverse domains well demonstrated that KARMA significantly outperforms mainstream baseline methods in both predictive accuracy and computational efficiency. Code and full results are available at this repository: https://github.com/yedadasd/KARMA
HICD: Hallucination-Inducing via Attention Dispersion for Contrastive Decoding to Mitigate Hallucinations in Large Language Models
Mar 17, 2025



Large Language Models (LLMs) often generate hallucinations, producing outputs that are contextually inaccurate or factually incorrect. We introduce HICD, a novel method designed to induce hallucinations for contrastive decoding to mitigate hallucinations. Unlike existing contrastive decoding methods, HICD selects attention heads crucial to the model's prediction as inducing heads, then induces hallucinations by dispersing attention of these inducing heads and compares the hallucinated outputs with the original outputs to obtain the final result. Our approach significantly improves performance on tasks requiring contextual faithfulness, such as context completion, reading comprehension, and question answering. It also improves factuality in tasks requiring accurate knowledge recall. We demonstrate that our inducing heads selection and attention dispersion method leads to more "contrast-effective" hallucinations for contrastive decoding, outperforming other hallucination-inducing methods. Our findings provide a promising strategy for reducing hallucinations by inducing hallucinations in a controlled manner, enhancing the performance of LLMs in a wide range of tasks.
Addressing Representation Collapse in Vector Quantized Models with One Linear Layer
Nov 04, 2024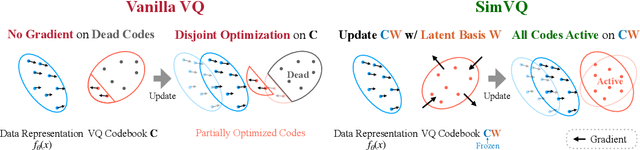
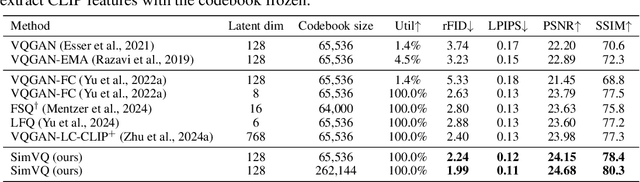
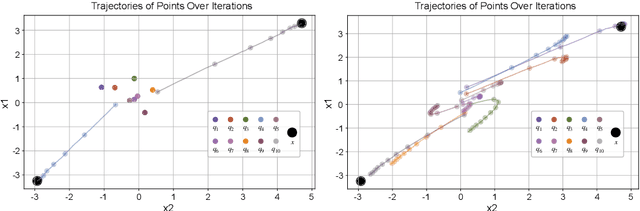
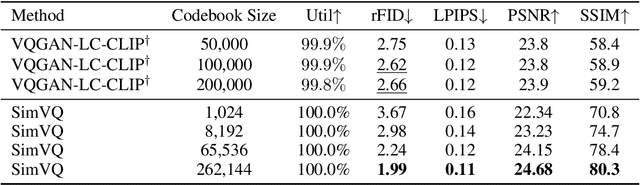
Vector Quantization (VQ) is a widely used method for converting continuous representations into discrete codes, which has become fundamental in unsupervised representation learning and latent generative models. However, VQ models are often hindered by the problem of representation collapse in the latent space, which leads to low codebook utilization and limits the scalability of the codebook for large-scale training. Existing methods designed to mitigate representation collapse typically reduce the dimensionality of latent space at the expense of model capacity, which do not fully resolve the core issue. In this study, we conduct a theoretical analysis of representation collapse in VQ models and identify its primary cause as the disjoint optimization of the codebook, where only a small subset of code vectors are updated through gradient descent. To address this issue, we propose \textbf{SimVQ}, a novel method which reparameterizes the code vectors through a linear transformation layer based on a learnable latent basis. This transformation optimizes the \textit{entire linear space} spanned by the codebook, rather than merely updating \textit{the code vector} selected by the nearest-neighbor search in vanilla VQ models. Although it is commonly understood that the multiplication of two linear matrices is equivalent to applying a single linear layer, our approach works surprisingly well in resolving the collapse issue in VQ models with just one linear layer. We validate the efficacy of SimVQ through extensive experiments across various modalities, including image and audio data with different model architectures. Our code is available at \url{https://github.com/youngsheen/SimVQ}.
Stabilize the Latent Space for Image Autoregressive Modeling: A Unified Perspective
Oct 16, 2024


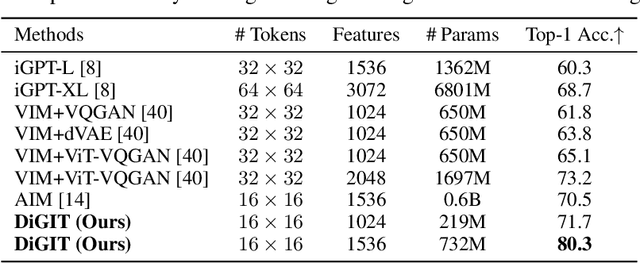
Latent-based image generative models, such as Latent Diffusion Models (LDMs) and Mask Image Models (MIMs), have achieved notable success in image generation tasks. These models typically leverage reconstructive autoencoders like VQGAN or VAE to encode pixels into a more compact latent space and learn the data distribution in the latent space instead of directly from pixels. However, this practice raises a pertinent question: Is it truly the optimal choice? In response, we begin with an intriguing observation: despite sharing the same latent space, autoregressive models significantly lag behind LDMs and MIMs in image generation. This finding contrasts sharply with the field of NLP, where the autoregressive model GPT has established a commanding presence. To address this discrepancy, we introduce a unified perspective on the relationship between latent space and generative models, emphasizing the stability of latent space in image generative modeling. Furthermore, we propose a simple but effective discrete image tokenizer to stabilize the latent space for image generative modeling. Experimental results show that image autoregressive modeling with our tokenizer (DiGIT) benefits both image understanding and image generation with the next token prediction principle, which is inherently straightforward for GPT models but challenging for other generative models. Remarkably, for the first time, a GPT-style autoregressive model for images outperforms LDMs, which also exhibits substantial improvement akin to GPT when scaling up model size. Our findings underscore the potential of an optimized latent space and the integration of discrete tokenization in advancing the capabilities of image generative models. The code is available at \url{https://github.com/DAMO-NLP-SG/DiGIT}.
Talk With Human-like Agents: Empathetic Dialogue Through Perceptible Acoustic Reception and Reaction
Jun 18, 2024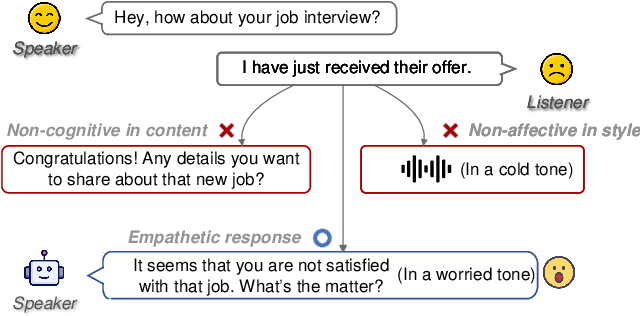

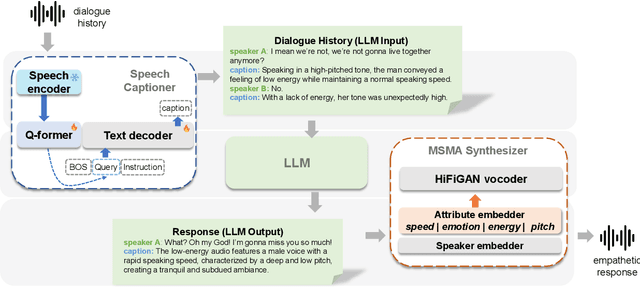
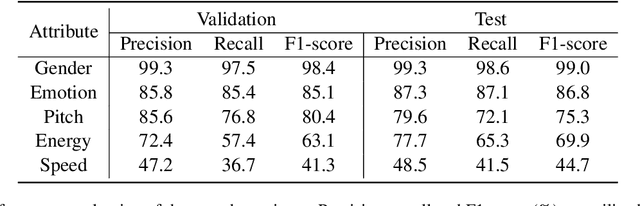
Large Language Model (LLM)-enhanced agents become increasingly prevalent in Human-AI communication, offering vast potential from entertainment to professional domains. However, current multi-modal dialogue systems overlook the acoustic information present in speech, which is crucial for understanding human communication nuances. This oversight can lead to misinterpretations of speakers' intentions, resulting in inconsistent or even contradictory responses within dialogues. To bridge this gap, in this paper, we propose PerceptiveAgent, an empathetic multi-modal dialogue system designed to discern deeper or more subtle meanings beyond the literal interpretations of words through the integration of speech modality perception. Employing LLMs as a cognitive core, PerceptiveAgent perceives acoustic information from input speech and generates empathetic responses based on speaking styles described in natural language. Experimental results indicate that PerceptiveAgent excels in contextual understanding by accurately discerning the speakers' true intentions in scenarios where the linguistic meaning is either contrary to or inconsistent with the speaker's true feelings, producing more nuanced and expressive spoken dialogues. Code is publicly available at: \url{https://github.com/Haoqiu-Yan/PerceptiveAgent}.
VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs
Jun 11, 2024



In this paper, we present the VideoLLaMA 2, a set of Video Large Language Models (Video-LLMs) designed to enhance spatial-temporal modeling and audio understanding in video and audio-oriented tasks. Building upon its predecessor, VideoLLaMA 2 incorporates a tailor-made Spatial-Temporal Convolution (STC) connector, which effectively captures the intricate spatial and temporal dynamics of video data. Additionally, we integrate an Audio Branch into the model through joint training, thereby enriching the multimodal understanding capabilities of the model by seamlessly incorporating audio cues. Comprehensive evaluations on multiple-choice video question answering (MC-VQA), open-ended video question answering (OE-VQA), and video captioning (VC) tasks demonstrate that VideoLLaMA 2 consistently achieves competitive results among open-source models and even gets close to some proprietary models on several benchmarks. Furthermore, VideoLLaMA 2 exhibits reasonable improvements in audio-only and audio-video question-answering (AQA & OE-AVQA) benchmarks over existing models. These advancements underline VideoLLaMA 2's superior performance in multimodal comprehension, setting a new standard for intelligent video analysis systems. All models are public to facilitate further research.
Generative Pre-trained Speech Language Model with Efficient Hierarchical Transformer
Jun 03, 2024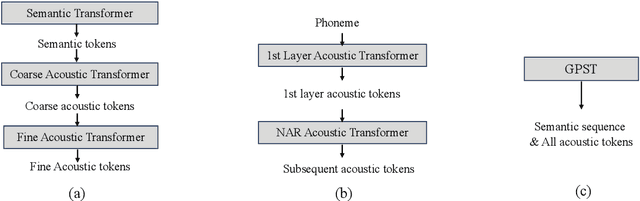
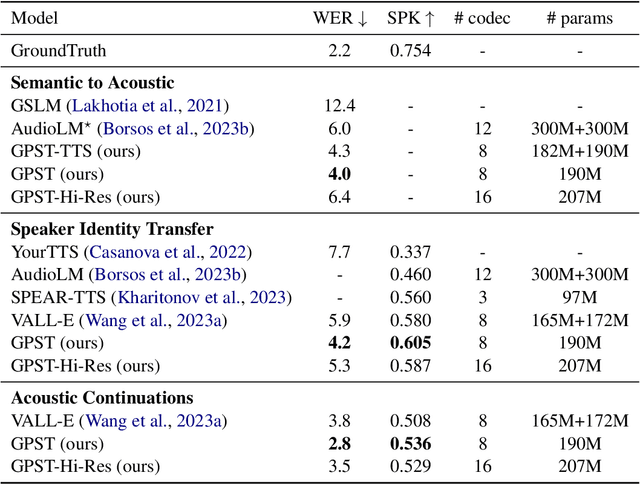
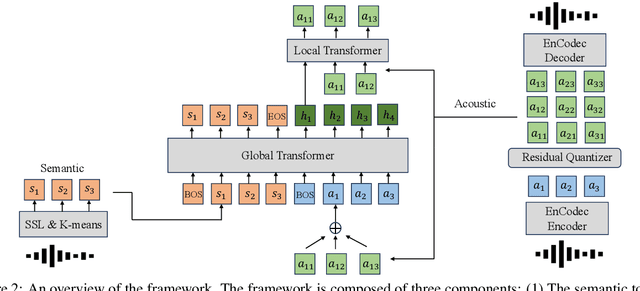
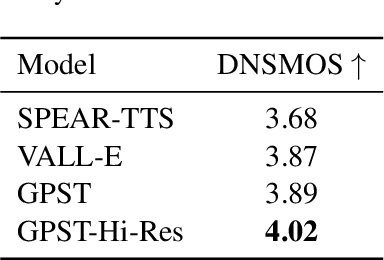
While recent advancements in speech language models have achieved significant progress, they face remarkable challenges in modeling the long acoustic sequences of neural audio codecs. In this paper, we introduce \textbf{G}enerative \textbf{P}re-trained \textbf{S}peech \textbf{T}ransformer (GPST), a hierarchical transformer designed for efficient speech language modeling. GPST quantizes audio waveforms into two distinct types of discrete speech representations and integrates them within a hierarchical transformer architecture, allowing for a unified one-stage generation process and enhancing Hi-Res audio generation capabilities. By training on large corpora of speeches in an end-to-end unsupervised manner, GPST can generate syntactically consistent speech with diverse speaker identities. Given a brief 3-second prompt, GPST can produce natural and coherent personalized speech, demonstrating in-context learning abilities. Moreover, our approach can be easily extended to spoken cross-lingual speech generation by incorporating multi-lingual semantic tokens and universal acoustic tokens. Experimental results indicate that GPST significantly outperforms the existing speech language models in terms of word error rate, speech quality, and speaker similarity. See \url{https://youngsheen.github.io/GPST/demo} for demo samples.
Bitformer: An efficient Transformer with bitwise operation-based attention for Big Data Analytics at low-cost low-precision devices
Nov 22, 2023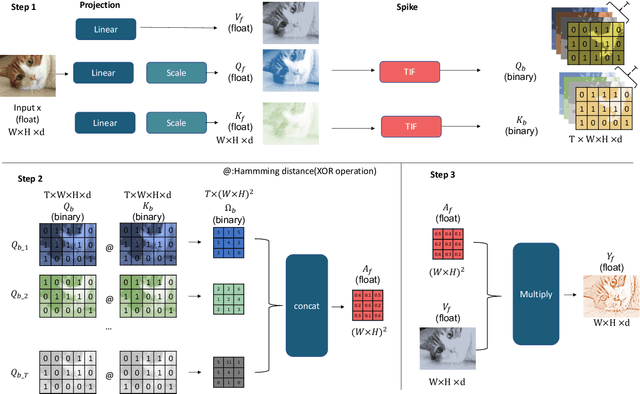

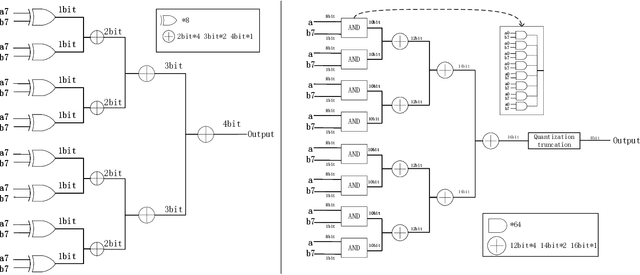
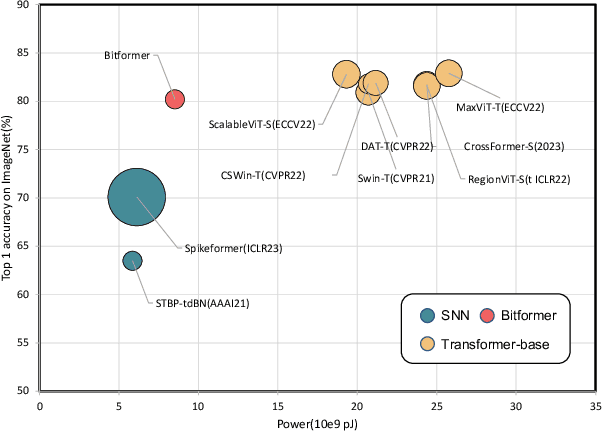
In the current landscape of large models, the Transformer stands as a cornerstone, playing a pivotal role in shaping the trajectory of modern models. However, its application encounters challenges attributed to the substantial computational intricacies intrinsic to its attention mechanism. Moreover, its reliance on high-precision floating-point operations presents specific hurdles, particularly evident in computation-intensive scenarios such as edge computing environments. These environments, characterized by resource-constrained devices and a preference for lower precision, necessitate innovative solutions. To tackle the exacting data processing demands posed by edge devices, we introduce the Bitformer model, an inventive extension of the Transformer paradigm. Central to this innovation is a novel attention mechanism that adeptly replaces conventional floating-point matrix multiplication with bitwise operations. This strategic substitution yields dual advantages. Not only does it maintain the attention mechanism's prowess in capturing intricate long-range information dependencies, but it also orchestrates a profound reduction in the computational complexity inherent in the attention operation. The transition from an $O(n^2d)$ complexity, typical of floating-point operations, to an $O(n^2T)$ complexity characterizing bitwise operations, substantiates this advantage. Notably, in this context, the parameter $T$ remains markedly smaller than the conventional dimensionality parameter $d$. The Bitformer model in essence endeavors to reconcile the indomitable requirements of modern computing landscapes with the constraints posed by edge computing scenarios. By forging this innovative path, we bridge the gap between high-performing models and resource-scarce environments, thus unveiling a promising trajectory for further advancements in the field.
DiffS2UT: A Semantic Preserving Diffusion Model for Textless Direct Speech-to-Speech Translation
Oct 26, 2023



While Diffusion Generative Models have achieved great success on image generation tasks, how to efficiently and effectively incorporate them into speech generation especially translation tasks remains a non-trivial problem. Specifically, due to the low information density of speech data, the transformed discrete speech unit sequence is much longer than the corresponding text transcription, posing significant challenges to existing auto-regressive models. Furthermore, it is not optimal to brutally apply discrete diffusion on the speech unit sequence while disregarding the continuous space structure, which will degrade the generation performance significantly. In this paper, we propose a novel diffusion model by applying the diffusion forward process in the \textit{continuous} speech representation space, while employing the diffusion backward process in the \textit{discrete} speech unit space. In this way, we preserve the semantic structure of the continuous speech representation space in the diffusion process and integrate the continuous and discrete diffusion models. We conduct extensive experiments on the textless direct speech-to-speech translation task, where the proposed method achieves comparable results to the computationally intensive auto-regressive baselines (500 steps on average) with significantly fewer decoding steps (50 steps).
Locate Then Generate: Bridging Vision and Language with Bounding Box for Scene-Text VQA
Apr 04, 2023



In this paper, we propose a novel multi-modal framework for Scene Text Visual Question Answering (STVQA), which requires models to read scene text in images for question answering. Apart from text or visual objects, which could exist independently, scene text naturally links text and visual modalities together by conveying linguistic semantics while being a visual object in an image simultaneously. Different to conventional STVQA models which take the linguistic semantics and visual semantics in scene text as two separate features, in this paper, we propose a paradigm of "Locate Then Generate" (LTG), which explicitly unifies this two semantics with the spatial bounding box as a bridge connecting them. Specifically, at first, LTG locates the region in an image that may contain the answer words with an answer location module (ALM) consisting of a region proposal network and a language refinement network, both of which can transform to each other with one-to-one mapping via the scene text bounding box. Next, given the answer words selected by ALM, LTG generates a readable answer sequence with an answer generation module (AGM) based on a pre-trained language model. As a benefit of the explicit alignment of the visual and linguistic semantics, even without any scene text based pre-training tasks, LTG can boost the absolute accuracy by +6.06% and +6.92% on the TextVQA dataset and the ST-VQA dataset respectively, compared with a non-pre-training baseline. We further demonstrate that LTG effectively unifies visual and text modalities through the spatial bounding box connection, which is underappreciated in previous methods.