 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpark-Prover-X1: Formal Theorem Proving Through Diverse Data Training
Nov 18, 2025Large Language Models (LLMs) have shown significant promise in automated theorem proving, yet progress is often constrained by the scarcity of diverse and high-quality formal language data. To address this issue, we introduce Spark-Prover-X1, a 7B parameter model trained via an three-stage framework designed to unlock the reasoning potential of more accessible and moderately-sized LLMs. The first stage infuses deep knowledge through continuous pre-training on a broad mathematical corpus, enhanced by a suite of novel data tasks. Key innovation is a "CoT-augmented state prediction" task to achieve fine-grained reasoning. The second stage employs Supervised Fine-tuning (SFT) within an expert iteration loop to specialize both the Spark-Prover-X1-7B and Spark-Formalizer-X1-7B models. Finally, a targeted round of Group Relative Policy Optimization (GRPO) is applied to sharpen the prover's capabilities on the most challenging problems. To facilitate robust evaluation, particularly on problems from real-world examinations, we also introduce ExamFormal-Bench, a new benchmark dataset of 402 formal problems. Experimental results demonstrate that Spark-Prover achieves state-of-the-art performance among similarly-sized open-source models within the "Whole-Proof Generation" paradigm. It shows exceptional performance on difficult competition benchmarks, notably solving 27 problems on PutnamBench (pass@32) and achieving 24.0\% on CombiBench (pass@32). Our work validates that this diverse training data and progressively refined training pipeline provides an effective path for enhancing the formal reasoning capabilities of lightweight LLMs. Both Spark-Prover-X1-7B and Spark-Formalizer-X1-7B, along with the ExamFormal-Bench dataset, are made publicly available at: https://www.modelscope.cn/organization/iflytek, https://gitcode.com/ifly_opensource.
DiffS2UT: A Semantic Preserving Diffusion Model for Textless Direct Speech-to-Speech Translation
Oct 26, 2023



While Diffusion Generative Models have achieved great success on image generation tasks, how to efficiently and effectively incorporate them into speech generation especially translation tasks remains a non-trivial problem. Specifically, due to the low information density of speech data, the transformed discrete speech unit sequence is much longer than the corresponding text transcription, posing significant challenges to existing auto-regressive models. Furthermore, it is not optimal to brutally apply discrete diffusion on the speech unit sequence while disregarding the continuous space structure, which will degrade the generation performance significantly. In this paper, we propose a novel diffusion model by applying the diffusion forward process in the \textit{continuous} speech representation space, while employing the diffusion backward process in the \textit{discrete} speech unit space. In this way, we preserve the semantic structure of the continuous speech representation space in the diffusion process and integrate the continuous and discrete diffusion models. We conduct extensive experiments on the textless direct speech-to-speech translation task, where the proposed method achieves comparable results to the computationally intensive auto-regressive baselines (500 steps on average) with significantly fewer decoding steps (50 steps).
CNN-based Discriminative Training for Domain Compensation in Acoustic Event Detection with Frame-wise Classifier
Mar 26, 2021

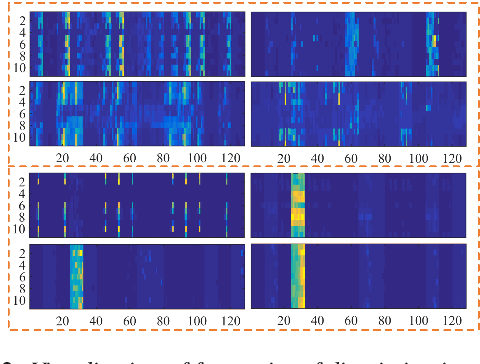

Domain mismatch is a noteworthy issue in acoustic event detection tasks, as the target domain data is difficult to access in most real applications. In this study, we propose a novel CNN-based discriminative training framework as a domain compensation method to handle this issue. It uses a parallel CNN-based discriminator to learn a pair of high-level intermediate acoustic representations. Together with a binary discriminative loss, the discriminators are forced to maximally exploit the discrimination of heterogeneous acoustic information in each audio clip with target events, which results in a robust paired representations that can well discriminate the target events and background/domain variations separately. Moreover, to better learn the transient characteristics of target events, a frame-wise classifier is designed to perform the final classification. In addition, a two-stage training with the CNN-based discriminator initialization is further proposed to enhance the system training. All experiments are performed on the DCASE 2018 Task3 datasets. Results show that our proposal significantly outperforms the official baseline on cross-domain conditions in AUC by relative $1.8-12.1$% without any performance degradation on in-domain evaluation conditions.