 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClawMark: A Living-World Benchmark for Multi-Turn, Multi-Day, Multimodal Coworker Agents
Apr 26, 2026Language-model agents are increasingly used as persistent coworkers that assist users across multiple working days. During such workflows, the surrounding environment may change independently of the agent: new emails arrive, calendar entries shift, knowledge-base records are updated, and evidence appears across images, scanned PDFs, audio, video, and spreadsheets. Existing benchmarks do not adequately evaluate this setting because they typically run within a single static episode and remain largely text-centric. We introduce \bench{}, a benchmark for coworker agents built around multi-turn multi-day tasks, a stateful sandboxed service environment whose state evolves between turns, and rule-based verification. The current release contains 100 tasks across 13 professional scenarios, executed against five stateful sandboxed services (filesystem, email, calendar, knowledge base, spreadsheet) and scored by 1537 deterministic Python checkers over post-execution service state; no LLM-as-judge is invoked during scoring. We benchmark seven frontier agent systems. The strongest model reaches 75.8 weighted score, but the best strict Task Success is only 20.0\%, indicating that partial progress is common while complete end-to-end workflow completion remains rare. Turn-level analysis shows that performance drops after the first exogenous environment update, highlighting adaptation to changing state as a key open challenge. We release the benchmark, evaluation harness, and construction pipeline to support reproducible coworker-agent evaluation.
LongRLVR: Long-Context Reinforcement Learning Requires Verifiable Context Rewards
Mar 02, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has significantly advanced the reasoning capabilities of Large Language Models (LLMs) by optimizing them against factual outcomes. However, this paradigm falters in long-context scenarios, as its reliance on internal parametric knowledge is ill-suited for tasks requiring contextual grounding--the ability to find and reason over externally provided information. We identify a key reason for this failure: a reward based solely on the final answer is too sparse to effectively guide the model for identifying relevant evidence. We formally prove that the outcome-only reward leads to significant vanishing gradients for the context grounding process, rendering learning intractable. To overcome this bottleneck, we introduce LongRLVR to augment the sparse answer reward with a dense and verifiable context reward. This auxiliary signal directly incentivizes the model for selecting the correct grounding information, providing a robust learning gradient that solves the underlying optimization challenge. We validate our method on challenging long-context benchmarks using Qwen and LLaMA models. LongRLVR consistently and significantly outperforms the standard RLVR across all models and benchmarks, e.g., boosting a 14B model's scores on RULER-QA from 73.17 to 88.90 and on LongBench v2 from 39.8 to 46.5. Our work demonstrates that explicitly rewarding the grounding process is a critical and effective strategy for unlocking the full reasoning potential of LLMs in long-context applications. Our code is available at https://github.com/real-absolute-AI/LongRLVR.
Document Reconstruction Unlocks Scalable Long-Context RLVR
Feb 09, 2026Reinforcement Learning with Verifiable Rewards~(RLVR) has become a prominent paradigm to enhance the capabilities (i.e.\ long-context) of Large Language Models~(LLMs). However, it often relies on gold-standard answers or explicit evaluation rubrics provided by powerful teacher models or human experts, which are costly and time-consuming. In this work, we investigate unsupervised approaches to enhance the long-context capabilities of LLMs, eliminating the need for heavy human annotations or teacher models' supervision. Specifically, we first replace a few paragraphs with special placeholders in a long document. LLMs are trained through reinforcement learning to reconstruct the document by correctly identifying and sequencing missing paragraphs from a set of candidate options. This training paradigm enables the model to capture global narrative coherence, significantly boosting long-context performance. We validate the effectiveness of our method on two widely used benchmarks, RULER and LongBench~v2. While acquiring noticeable gains on RULER, it can also achieve a reasonable improvement on LongBench~v2 without any manually curated long-context QA data. Furthermore, we conduct extensive ablation studies to analyze the impact of reward design, data curation strategies, training schemes, and data scaling effects on model performance. We publicly release our code, data, and models.
MiroThinker: Pushing the Performance Boundaries of Open-Source Research Agents via Model, Context, and Interactive Scaling
Nov 18, 2025We present MiroThinker v1.0, an open-source research agent designed to advance tool-augmented reasoning and information-seeking capabilities. Unlike previous agents that only scale up model size or context length, MiroThinker explores interaction scaling at the model level, systematically training the model to handle deeper and more frequent agent-environment interactions as a third dimension of performance improvement. Unlike LLM test-time scaling, which operates in isolation and risks degradation with longer reasoning chains, interactive scaling leverages environment feedback and external information acquisition to correct errors and refine trajectories. Through reinforcement learning, the model achieves efficient interaction scaling: with a 256K context window, it can perform up to 600 tool calls per task, enabling sustained multi-turn reasoning and complex real-world research workflows. Across four representative benchmarks-GAIA, HLE, BrowseComp, and BrowseComp-ZH-the 72B variant achieves up to 81.9%, 37.7%, 47.1%, and 55.6% accuracy respectively, surpassing previous open-source agents and approaching commercial counterparts such as GPT-5-high. Our analysis reveals that MiroThinker benefits from interactive scaling consistently: research performance improves predictably as the model engages in deeper and more frequent agent-environment interactions, demonstrating that interaction depth exhibits scaling behaviors analogous to model size and context length. These findings establish interaction scaling as a third critical dimension for building next-generation open research agents, complementing model capacity and context windows.
Long-Context Inference with Retrieval-Augmented Speculative Decoding
Feb 27, 2025The emergence of long-context large language models (LLMs) offers a promising alternative to traditional retrieval-augmented generation (RAG) for processing extensive documents. However, the computational overhead of long-context inference, particularly in managing key-value (KV) caches, presents significant efficiency challenges. While Speculative Decoding (SD) traditionally accelerates inference using smaller draft models, its effectiveness diminishes substantially in long-context scenarios due to memory-bound KV cache operations. We present Retrieval-Augmented Speculative Decoding (RAPID), which leverages RAG for both accelerating and enhancing generation quality in long-context inference. RAPID introduces the RAG drafter-a draft LLM operating on shortened retrieval contexts-to speculate on the generation of long-context target LLMs. Our approach enables a new paradigm where same-scale or even larger LLMs can serve as RAG drafters while maintaining computational efficiency. To fully leverage the potentially superior capabilities from stronger RAG drafters, we develop an inference-time knowledge transfer dynamic that enriches the target distribution by RAG. Extensive experiments on the LLaMA-3.1 and Qwen2.5 backbones demonstrate that RAPID effectively integrates the strengths of both approaches, achieving significant performance improvements (e.g., from 39.33 to 42.83 on InfiniteBench for LLaMA-3.1-8B) with more than 2x speedups. Our analyses reveal that RAPID achieves robust acceleration beyond 32K context length and demonstrates superior generation quality in real-world applications.
LongPO: Long Context Self-Evolution of Large Language Models through Short-to-Long Preference Optimization
Feb 20, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities through pretraining and alignment. However, superior short-context LLMs may underperform in long-context scenarios due to insufficient long-context alignment. This alignment process remains challenging due to the impracticality of human annotation for extended contexts and the difficulty in balancing short- and long-context performance. To address these challenges, we introduce LongPO, that enables short-context LLMs to self-evolve to excel on long-context tasks by internally transferring short-context capabilities. LongPO harnesses LLMs to learn from self-generated short-to-long preference data, comprising paired responses generated for identical instructions with long-context inputs and their compressed short-context counterparts, respectively. This preference reveals capabilities and potentials of LLMs cultivated during short-context alignment that may be diminished in under-aligned long-context scenarios. Additionally, LongPO incorporates a short-to-long KL constraint to mitigate short-context performance decline during long-context alignment. When applied to Mistral-7B-Instruct-v0.2 from 128K to 512K context lengths, LongPO fully retains short-context performance and largely outperforms naive SFT and DPO in both long- and short-context tasks. Specifically, LongPO-trained models can achieve results on long-context benchmarks comparable to, or even surpassing, those of superior LLMs (e.g., GPT-4-128K) that involve extensive long-context annotation and larger parameter scales. Our code is available at https://github.com/DAMO-NLP-SG/LongPO.
VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs
Jun 11, 2024



In this paper, we present the VideoLLaMA 2, a set of Video Large Language Models (Video-LLMs) designed to enhance spatial-temporal modeling and audio understanding in video and audio-oriented tasks. Building upon its predecessor, VideoLLaMA 2 incorporates a tailor-made Spatial-Temporal Convolution (STC) connector, which effectively captures the intricate spatial and temporal dynamics of video data. Additionally, we integrate an Audio Branch into the model through joint training, thereby enriching the multimodal understanding capabilities of the model by seamlessly incorporating audio cues. Comprehensive evaluations on multiple-choice video question answering (MC-VQA), open-ended video question answering (OE-VQA), and video captioning (VC) tasks demonstrate that VideoLLaMA 2 consistently achieves competitive results among open-source models and even gets close to some proprietary models on several benchmarks. Furthermore, VideoLLaMA 2 exhibits reasonable improvements in audio-only and audio-video question-answering (AQA & OE-AVQA) benchmarks over existing models. These advancements underline VideoLLaMA 2's superior performance in multimodal comprehension, setting a new standard for intelligent video analysis systems. All models are public to facilitate further research.
SeaLLMs -- Large Language Models for Southeast Asia
Dec 01, 2023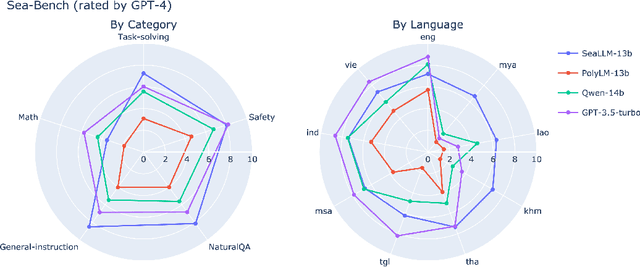
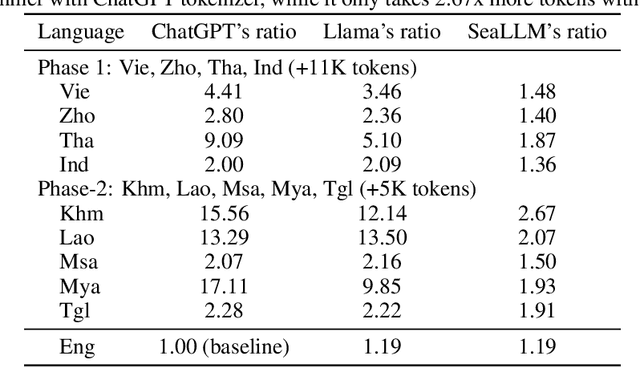
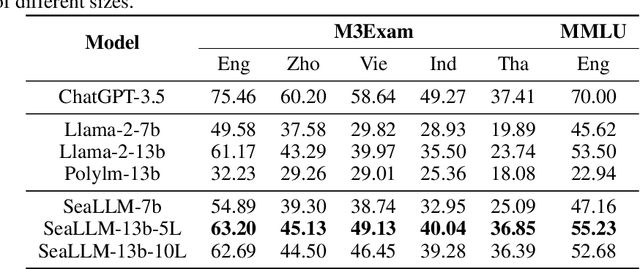
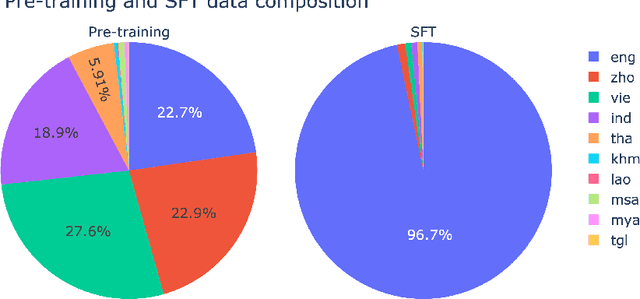
Despite the remarkable achievements of large language models (LLMs) in various tasks, there remains a linguistic bias that favors high-resource languages, such as English, often at the expense of low-resource and regional languages. To address this imbalance, we introduce SeaLLMs, an innovative series of language models that specifically focuses on Southeast Asian (SEA) languages. SeaLLMs are built upon the Llama-2 model and further advanced through continued pre-training with an extended vocabulary, specialized instruction and alignment tuning to better capture the intricacies of regional languages. This allows them to respect and reflect local cultural norms, customs, stylistic preferences, and legal considerations. Our comprehensive evaluation demonstrates that SeaLLM-13b models exhibit superior performance across a wide spectrum of linguistic tasks and assistant-style instruction-following capabilities relative to comparable open-source models. Moreover, they outperform ChatGPT-3.5 in non-Latin languages, such as Thai, Khmer, Lao, and Burmese, by large margins while remaining lightweight and cost-effective to operate.
Mitigating Object Hallucinations in Large Vision-Language Models through Visual Contrastive Decoding
Nov 28, 2023Large Vision-Language Models (LVLMs) have advanced considerably, intertwining visual recognition and language understanding to generate content that is not only coherent but also contextually attuned. Despite their success, LVLMs still suffer from the issue of object hallucinations, where models generate plausible yet incorrect outputs that include objects that do not exist in the images. To mitigate this issue, we introduce Visual Contrastive Decoding (VCD), a simple and training-free method that contrasts output distributions derived from original and distorted visual inputs. The proposed VCD effectively reduces the over-reliance on statistical bias and unimodal priors, two essential causes of object hallucinations. This adjustment ensures the generated content is closely grounded to visual inputs, resulting in contextually accurate outputs. Our experiments show that VCD, without either additional training or the usage of external tools, significantly mitigates the object hallucination issue across different LVLM families. Beyond mitigating object hallucinations, VCD also excels in general LVLM benchmarks, highlighting its wide-ranging applicability.
CLEX: Continuous Length Extrapolation for Large Language Models
Oct 25, 2023
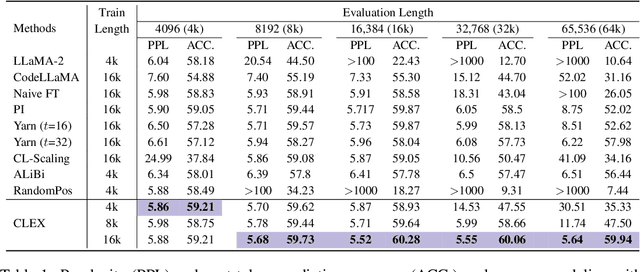


Transformer-based Large Language Models (LLMs) are pioneering advances in many natural language processing tasks, however, their exceptional capabilities are restricted within the preset context window of Transformer. Position Embedding (PE) scaling methods, while effective in extending the context window to a specific length, demonstrate either notable limitations in their extrapolation abilities or sacrificing partial performance within the context window. Length extrapolation methods, although theoretically capable of extending the context window beyond the training sequence length, often underperform in practical long-context applications. To address these challenges, we propose Continuous Length EXtrapolation (CLEX) for LLMs. We generalise the PE scaling approaches to model the continuous dynamics by ordinary differential equations over the length scaling factor, thereby overcoming the constraints of current PE scaling methods designed for specific lengths. Moreover, by extending the dynamics to desired context lengths beyond the training sequence length, CLEX facilitates the length extrapolation with impressive performance in practical tasks. We demonstrate that CLEX can be seamlessly incorporated into LLMs equipped with Rotary Position Embedding, such as LLaMA and GPT-NeoX, with negligible impact on training and inference latency. Experimental results reveal that CLEX can effectively extend the context window to over 4x or almost 8x training length, with no deterioration in performance. Furthermore, when evaluated on the practical LongBench benchmark, our model trained on a 4k length exhibits competitive performance against state-of-the-art open-source models trained on context lengths up to 32k.