 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRynnVLA-001: Using Human Demonstrations to Improve Robot Manipulation
Sep 18, 2025This paper presents RynnVLA-001, a vision-language-action(VLA) model built upon large-scale video generative pretraining from human demonstrations. We propose a novel two-stage pretraining methodology. The first stage, Ego-Centric Video Generative Pretraining, trains an Image-to-Video model on 12M ego-centric manipulation videos to predict future frames conditioned on an initial frame and a language instruction. The second stage, Human-Centric Trajectory-Aware Modeling, extends this by jointly predicting future keypoint trajectories, thereby effectively bridging visual frame prediction with action prediction. Furthermore, to enhance action representation, we propose ActionVAE, a variational autoencoder that compresses sequences of actions into compact latent embeddings, reducing the complexity of the VLA output space. When finetuned on the same downstream robotics datasets, RynnVLA-001 achieves superior performance over state-of-the-art baselines, demonstrating that the proposed pretraining strategy provides a more effective initialization for VLA models.
VL-Cogito: Progressive Curriculum Reinforcement Learning for Advanced Multimodal Reasoning
Jul 30, 2025



Reinforcement learning has proven its effectiveness in enhancing the reasoning capabilities of large language models. Recent research efforts have progressively extended this paradigm to multimodal reasoning tasks. Due to the inherent complexity and diversity of multimodal tasks, especially in semantic content and problem formulations, existing models often exhibit unstable performance across various domains and difficulty levels. To address these limitations, we propose VL-Cogito, an advanced multimodal reasoning model trained via a novel multi-stage Progressive Curriculum Reinforcement Learning (PCuRL) framework. PCuRL systematically guides the model through tasks of gradually increasing difficulty, substantially improving its reasoning abilities across diverse multimodal contexts. The framework introduces two key innovations: (1) an online difficulty soft weighting mechanism, dynamically adjusting training difficulty across successive RL training stages; and (2) a dynamic length reward mechanism, which encourages the model to adaptively regulate its reasoning path length according to task complexity, thus balancing reasoning efficiency with correctness. Experimental evaluations demonstrate that VL-Cogito consistently matches or surpasses existing reasoning-oriented models across mainstream multimodal benchmarks spanning mathematics, science, logic, and general understanding, validating the effectiveness of our approach.
Two Is Better Than One: Rotations Scale LoRAs
May 29, 2025Scaling Low-Rank Adaptation (LoRA)-based Mixture-of-Experts (MoE) facilitates large language models (LLMs) to efficiently adapt to diverse tasks. However, traditional gating mechanisms that route inputs to the best experts may fundamentally hinder LLMs' scalability, leading to poor generalization and underfitting issues. We identify that the root cause lies in the restricted expressiveness of existing weighted-sum mechanisms, both within and outside the convex cone of LoRA representations. This motivates us to propose RadarGate, a novel geometrically inspired gating method that introduces rotational operations of LoRAs representations to boost the expressiveness and facilitate richer feature interactions among multiple LoRAs for scalable LLMs. Specifically, we first fuse each LoRA representation to other LoRAs using a learnable component and then feed the output to a rotation matrix. This matrix involves learnable parameters that define the relative angular relationship between LoRA representations. Such a simple yet effective mechanism provides an extra degree of freedom, facilitating the learning of cross-LoRA synergies and properly tracking the challenging poor generalization and underfitting issues as the number of LoRA grows. Extensive experiments on 6 public benchmarks across 21 tasks show the effectiveness of our RadarGate for scaling LoRAs. We also provide valuable insights, revealing that the rotations to each pair of representations are contrastive, encouraging closer alignment of semantically similar representations during geometrical transformation while pushing distance ones further apart. We will release our code to the community.
Advancing Expert Specialization for Better MoE
May 28, 2025

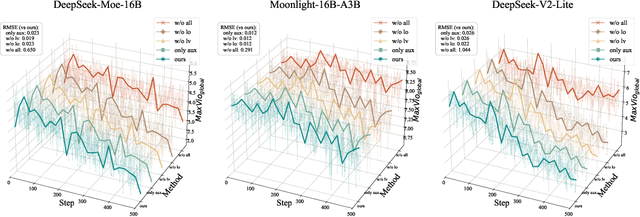

Mixture-of-Experts (MoE) models enable efficient scaling of large language models (LLMs) by activating only a subset of experts per input. However, we observe that the commonly used auxiliary load balancing loss often leads to expert overlap and overly uniform routing, which hinders expert specialization and degrades overall performance during post-training. To address this, we propose a simple yet effective solution that introduces two complementary objectives: (1) an orthogonality loss to encourage experts to process distinct types of tokens, and (2) a variance loss to encourage more discriminative routing decisions. Gradient-level analysis demonstrates that these objectives are compatible with the existing auxiliary loss and contribute to optimizing the training process. Experimental results over various model architectures and across multiple benchmarks show that our method significantly enhances expert specialization. Notably, our method improves classic MoE baselines with auxiliary loss by up to 23.79%, while also maintaining load balancing in downstream tasks, without any architectural modifications or additional components. We will release our code to contribute to the community.
Refining Positive and Toxic Samples for Dual Safety Self-Alignment of LLMs with Minimal Human Interventions
Feb 08, 2025Recent AI agents, such as ChatGPT and LLaMA, primarily rely on instruction tuning and reinforcement learning to calibrate the output of large language models (LLMs) with human intentions, ensuring the outputs are harmless and helpful. Existing methods heavily depend on the manual annotation of high-quality positive samples, while contending with issues such as noisy labels and minimal distinctions between preferred and dispreferred response data. However, readily available toxic samples with clear safety distinctions are often filtered out, removing valuable negative references that could aid LLMs in safety alignment. In response, we propose PT-ALIGN, a novel safety self-alignment approach that minimizes human supervision by automatically refining positive and toxic samples and performing fine-grained dual instruction tuning. Positive samples are harmless responses, while toxic samples deliberately contain extremely harmful content, serving as a new supervisory signals. Specifically, we utilize LLM itself to iteratively generate and refine training instances by only exploring fewer than 50 human annotations. We then employ two losses, i.e., maximum likelihood estimation (MLE) and fine-grained unlikelihood training (UT), to jointly learn to enhance the LLM's safety. The MLE loss encourages an LLM to maximize the generation of harmless content based on positive samples. Conversely, the fine-grained UT loss guides the LLM to minimize the output of harmful words based on negative samples at the token-level, thereby guiding the model to decouple safety from effectiveness, directing it toward safer fine-tuning objectives, and increasing the likelihood of generating helpful and reliable content. Experiments on 9 popular open-source LLMs demonstrate the effectiveness of our PT-ALIGN for safety alignment, while maintaining comparable levels of helpfulness and usefulness.
BenchX: A Unified Benchmark Framework for Medical Vision-Language Pretraining on Chest X-Rays
Oct 29, 2024



Medical Vision-Language Pretraining (MedVLP) shows promise in learning generalizable and transferable visual representations from paired and unpaired medical images and reports. MedVLP can provide useful features to downstream tasks and facilitate adapting task-specific models to new setups using fewer examples. However, existing MedVLP methods often differ in terms of datasets, preprocessing, and finetuning implementations. This pose great challenges in evaluating how well a MedVLP method generalizes to various clinically-relevant tasks due to the lack of unified, standardized, and comprehensive benchmark. To fill this gap, we propose BenchX, a unified benchmark framework that enables head-to-head comparison and systematical analysis between MedVLP methods using public chest X-ray datasets. Specifically, BenchX is composed of three components: 1) Comprehensive datasets covering nine datasets and four medical tasks; 2) Benchmark suites to standardize data preprocessing, train-test splits, and parameter selection; 3) Unified finetuning protocols that accommodate heterogeneous MedVLP methods for consistent task adaptation in classification, segmentation, and report generation, respectively. Utilizing BenchX, we establish baselines for nine state-of-the-art MedVLP methods and found that the performance of some early MedVLP methods can be enhanced to surpass more recent ones, prompting a revisiting of the developments and conclusions from prior works in MedVLP. Our code are available at https://github.com/yangzhou12/BenchX.
Breaking the Memory Barrier: Near Infinite Batch Size Scaling for Contrastive Loss
Oct 22, 2024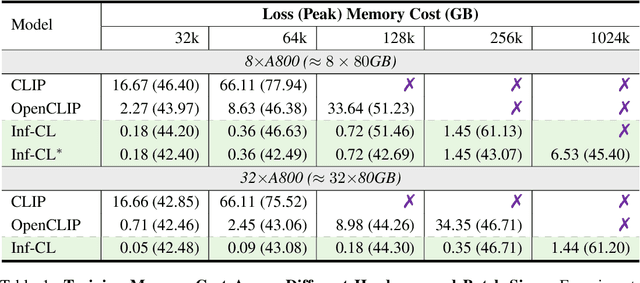
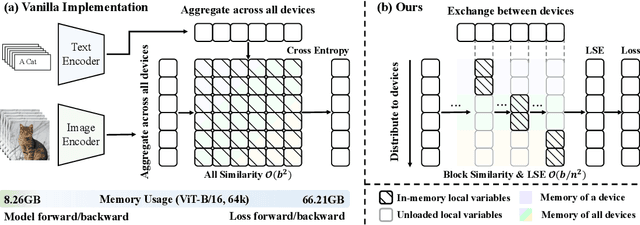
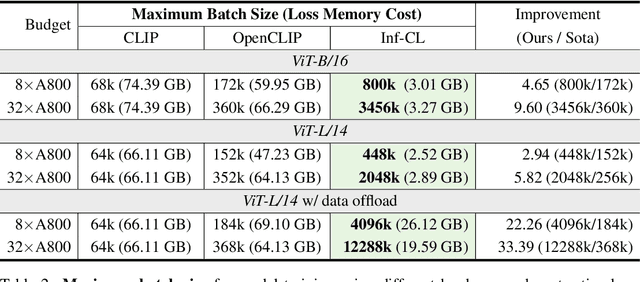
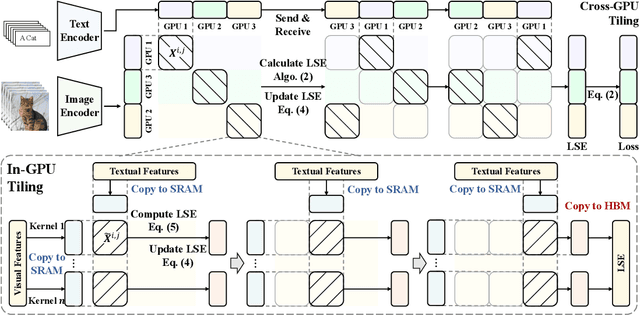
Contrastive loss is a powerful approach for representation learning, where larger batch sizes enhance performance by providing more negative samples to better distinguish between similar and dissimilar data. However, scaling batch sizes is constrained by the quadratic growth in GPU memory consumption, primarily due to the full instantiation of the similarity matrix. To address this, we propose a tile-based computation strategy that partitions the contrastive loss calculation into arbitrary small blocks, avoiding full materialization of the similarity matrix. Furthermore, we introduce a multi-level tiling strategy to leverage the hierarchical structure of distributed systems, employing ring-based communication at the GPU level to optimize synchronization and fused kernels at the CUDA core level to reduce I/O overhead. Experimental results show that the proposed method scales batch sizes to unprecedented levels. For instance, it enables contrastive training of a CLIP-ViT-L/14 model with a batch size of 4M or 12M using 8 or 32 A800 80GB without sacrificing any accuracy. Compared to SOTA memory-efficient solutions, it achieves a two-order-of-magnitude reduction in memory while maintaining comparable speed. The code will be made publicly available.
The Curse of Multi-Modalities: Evaluating Hallucinations of Large Multimodal Models across Language, Visual, and Audio
Oct 16, 2024
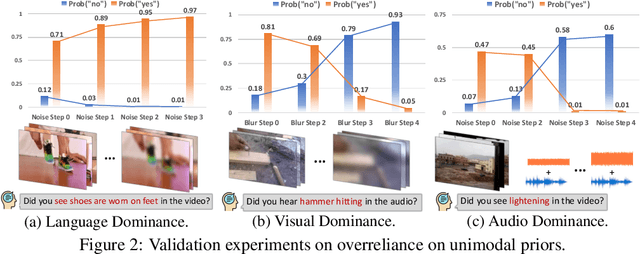

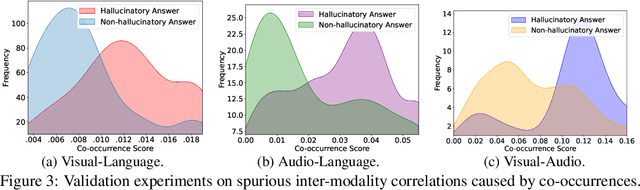
Recent advancements in large multimodal models (LMMs) have significantly enhanced performance across diverse tasks, with ongoing efforts to further integrate additional modalities such as video and audio. However, most existing LMMs remain vulnerable to hallucinations, the discrepancy between the factual multimodal input and the generated textual output, which has limited their applicability in various real-world scenarios. This paper presents the first systematic investigation of hallucinations in LMMs involving the three most common modalities: language, visual, and audio. Our study reveals two key contributors to hallucinations: overreliance on unimodal priors and spurious inter-modality correlations. To address these challenges, we introduce the benchmark The Curse of Multi-Modalities (CMM), which comprehensively evaluates hallucinations in LMMs, providing a detailed analysis of their underlying issues. Our findings highlight key vulnerabilities, including imbalances in modality integration and biases from training data, underscoring the need for balanced cross-modal learning and enhanced hallucination mitigation strategies. Based on our observations and findings, we suggest potential research directions that could enhance the reliability of LMMs.
AGLA: Mitigating Object Hallucinations in Large Vision-Language Models with Assembly of Global and Local Attention
Jun 18, 2024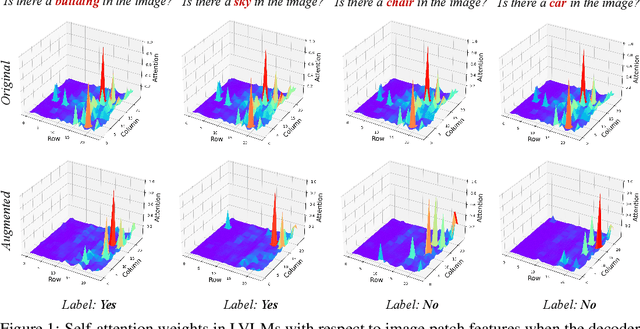
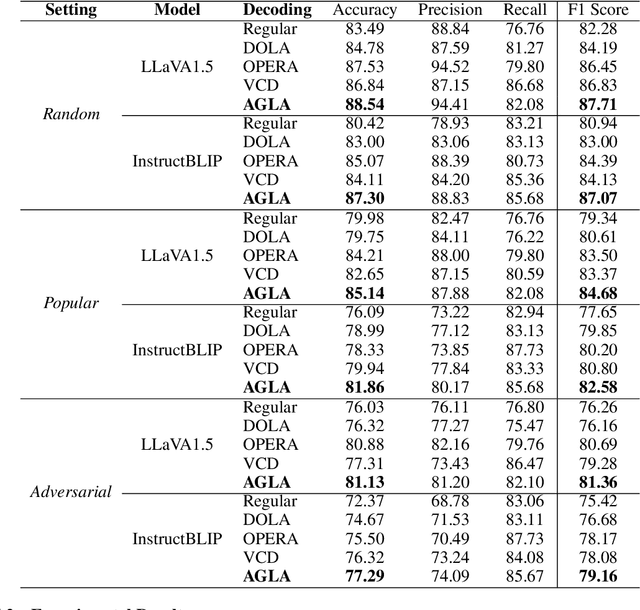
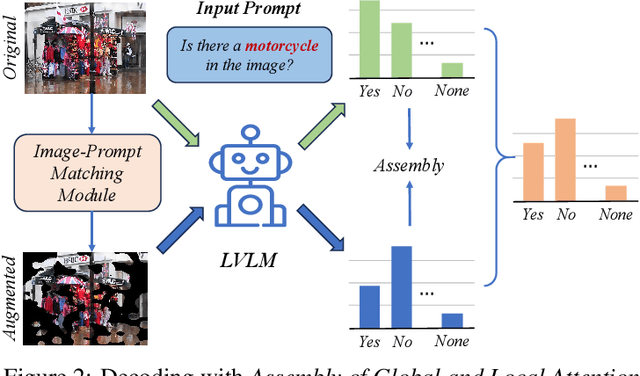
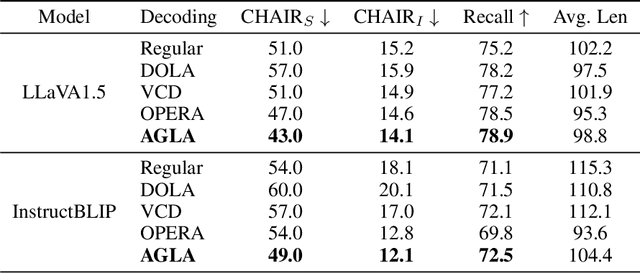
Despite their great success across various multimodal tasks, Large Vision-Language Models (LVLMs) are facing a prevalent problem with object hallucinations, where the generated textual responses are inconsistent with ground-truth objects in the given image. This paper investigates various LVLMs and pinpoints attention deficiency toward discriminative local image features as one root cause of object hallucinations. Specifically, LVLMs predominantly attend to prompt-independent global image features, while failing to capture prompt-relevant local features, consequently undermining the visual grounding capacity of LVLMs and leading to hallucinations. To this end, we propose Assembly of Global and Local Attention (AGLA), a training-free and plug-and-play approach that mitigates object hallucinations by exploring an ensemble of global features for response generation and local features for visual discrimination simultaneously. Our approach exhibits an image-prompt matching scheme that captures prompt-relevant local features from images, leading to an augmented view of the input image where prompt-relevant content is reserved while irrelevant distractions are masked. With the augmented view, a calibrated decoding distribution can be derived by integrating generative global features from the original image and discriminative local features from the augmented image. Extensive experiments show that AGLA consistently mitigates object hallucinations and enhances general perception capability for LVLMs across various discriminative and generative benchmarks. Our code will be released at https://github.com/Lackel/AGLA.
VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs
Jun 11, 2024



In this paper, we present the VideoLLaMA 2, a set of Video Large Language Models (Video-LLMs) designed to enhance spatial-temporal modeling and audio understanding in video and audio-oriented tasks. Building upon its predecessor, VideoLLaMA 2 incorporates a tailor-made Spatial-Temporal Convolution (STC) connector, which effectively captures the intricate spatial and temporal dynamics of video data. Additionally, we integrate an Audio Branch into the model through joint training, thereby enriching the multimodal understanding capabilities of the model by seamlessly incorporating audio cues. Comprehensive evaluations on multiple-choice video question answering (MC-VQA), open-ended video question answering (OE-VQA), and video captioning (VC) tasks demonstrate that VideoLLaMA 2 consistently achieves competitive results among open-source models and even gets close to some proprietary models on several benchmarks. Furthermore, VideoLLaMA 2 exhibits reasonable improvements in audio-only and audio-video question-answering (AQA & OE-AVQA) benchmarks over existing models. These advancements underline VideoLLaMA 2's superior performance in multimodal comprehension, setting a new standard for intelligent video analysis systems. All models are public to facilitate further research.