 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards deployment-centric multimodal AI beyond vision and language
Apr 04, 2025Multimodal artificial intelligence (AI) integrates diverse types of data via machine learning to improve understanding, prediction, and decision-making across disciplines such as healthcare, science, and engineering. However, most multimodal AI advances focus on models for vision and language data, while their deployability remains a key challenge. We advocate a deployment-centric workflow that incorporates deployment constraints early to reduce the likelihood of undeployable solutions, complementing data-centric and model-centric approaches. We also emphasise deeper integration across multiple levels of multimodality and multidisciplinary collaboration to significantly broaden the research scope beyond vision and language. To facilitate this approach, we identify common multimodal-AI-specific challenges shared across disciplines and examine three real-world use cases: pandemic response, self-driving car design, and climate change adaptation, drawing expertise from healthcare, social science, engineering, science, sustainability, and finance. By fostering multidisciplinary dialogue and open research practices, our community can accelerate deployment-centric development for broad societal impact.
Classifying the Stoichiometry of Virus-like Particles with Interpretable Machine Learning
Feb 17, 2025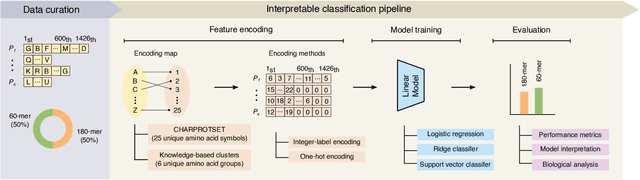

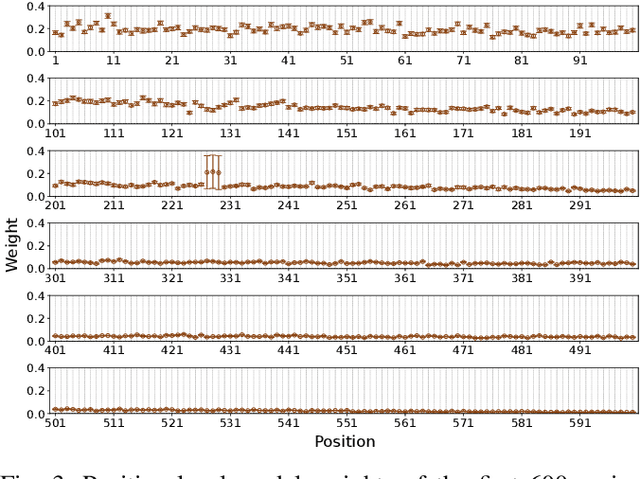
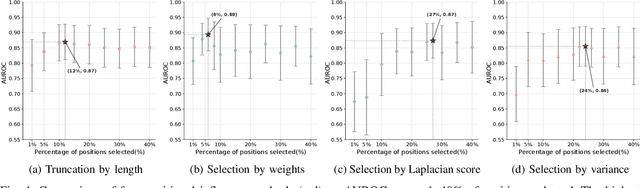
Virus-like particles (VLPs) are valuable for vaccine development due to their immune-triggering properties. Understanding their stoichiometry, the number of protein subunits to form a VLP, is critical for vaccine optimisation. However, current experimental methods to determine stoichiometry are time-consuming and require highly purified proteins. To efficiently classify stoichiometry classes in proteins, we curate a new dataset and propose an interpretable, data-driven pipeline leveraging linear machine learning models. We also explore the impact of feature encoding on model performance and interpretability, as well as methods to identify key protein sequence features influencing classification. The evaluation of our pipeline demonstrates that it can classify stoichiometry while revealing protein features that possibly influence VLP assembly. The data and code used in this work are publicly available at https://github.com/Shef-AIRE/StoicIML.
Uncovering What, Why and How: A Comprehensive Benchmark for Causation Understanding of Video Anomaly
Apr 30, 2024



Video anomaly understanding (VAU) aims to automatically comprehend unusual occurrences in videos, thereby enabling various applications such as traffic surveillance and industrial manufacturing. While existing VAU benchmarks primarily concentrate on anomaly detection and localization, our focus is on more practicality, prompting us to raise the following crucial questions: "what anomaly occurred?", "why did it happen?", and "how severe is this abnormal event?". In pursuit of these answers, we present a comprehensive benchmark for Causation Understanding of Video Anomaly (CUVA). Specifically, each instance of the proposed benchmark involves three sets of human annotations to indicate the "what", "why" and "how" of an anomaly, including 1) anomaly type, start and end times, and event descriptions, 2) natural language explanations for the cause of an anomaly, and 3) free text reflecting the effect of the abnormality. In addition, we also introduce MMEval, a novel evaluation metric designed to better align with human preferences for CUVA, facilitating the measurement of existing LLMs in comprehending the underlying cause and corresponding effect of video anomalies. Finally, we propose a novel prompt-based method that can serve as a baseline approach for the challenging CUVA. We conduct extensive experiments to show the superiority of our evaluation metric and the prompt-based approach. Our code and dataset are available at https://github.com/fesvhtr/CUVA.
Spatial-aware Speaker Diarization for Multi-channel Multi-party Meeting
Sep 24, 2022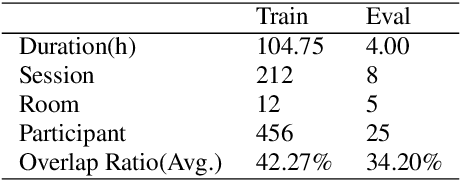
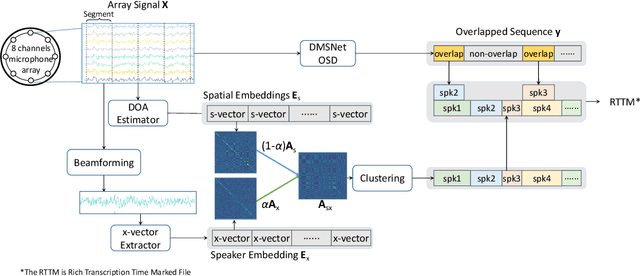

This paper describes a spatial-aware speaker diarization system for the multi-channel multi-party meeting. The diarization system obtains direction information of speaker by microphone array. Speaker spatial embedding is generated by xvector and s-vector derived from superdirective beamforming (SDB) which makes the embedding more robust. Specifically, we propose a novel multi-channel sequence-to-sequence neural network architecture named discriminative multi-stream neural network (DMSNet) which consists of attention superdirective beamforming (ASDB) block and Conformer encoder. The proposed ASDB is a self-adapted channel-wise block that extracts the latent spatial features of array audios by modeling interdependencies between channels. We explore DMSNet to address overlapped speech problem on multi-channel audio and achieve 93.53% accuracy on evaluation set. By performing DMSNet based overlapped speech detection (OSD) module, the diarization error rate (DER) of cluster-based diarization system decrease significantly from 13.45% to 7.64%.
The xmuspeech system for multi-channel multi-party meeting transcription challenge
Feb 11, 2022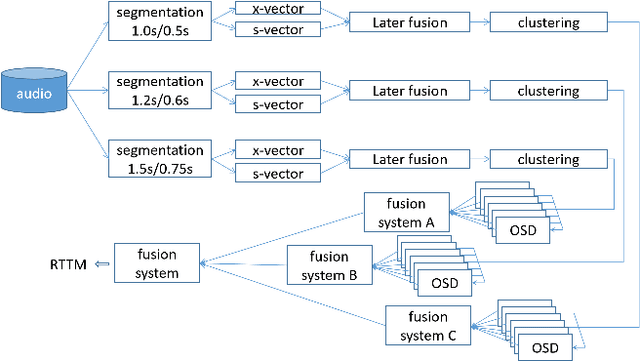

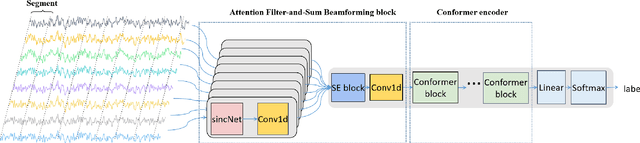
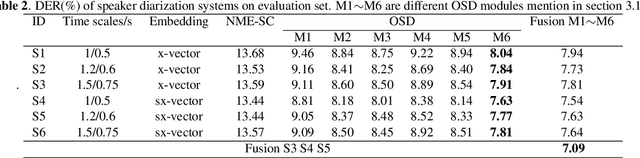
This paper describes the system developed by the XMUSPEECH team for the Multi-channel Multi-party Meeting Transcription Challenge (M2MeT). For the speaker diarization task, we propose a multi-channel speaker diarization system that obtains spatial information of speaker by Difference of Arrival (DOA) technology. Speaker-spatial embedding is generated by x-vector and s-vector derived from Filter-and-Sum Beamforming (FSB) which makes the embedding more robust. Specifically, we propose a novel multi-channel sequence-to-sequence neural network architecture named Discriminative Multi-stream Neural Network (DMSNet) which consists of Attention Filter-and-Sum block (AFSB) and Conformer encoder. We explore DMSNet to address overlapped speech problem on multi-channel audio. Compared with LSTM based OSD module, we achieve a decreases of 10.1% in Detection Error Rate(DetER). By performing DMSNet based OSD module, the DER of cluster-based diarization system decrease significantly form 13.44% to 7.63%. Our best fusion system achieves 7.09% and 9.80% of the diarization error rate (DER) on evaluation set and test set.