 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards deployment-centric multimodal AI beyond vision and language
Apr 04, 2025Multimodal artificial intelligence (AI) integrates diverse types of data via machine learning to improve understanding, prediction, and decision-making across disciplines such as healthcare, science, and engineering. However, most multimodal AI advances focus on models for vision and language data, while their deployability remains a key challenge. We advocate a deployment-centric workflow that incorporates deployment constraints early to reduce the likelihood of undeployable solutions, complementing data-centric and model-centric approaches. We also emphasise deeper integration across multiple levels of multimodality and multidisciplinary collaboration to significantly broaden the research scope beyond vision and language. To facilitate this approach, we identify common multimodal-AI-specific challenges shared across disciplines and examine three real-world use cases: pandemic response, self-driving car design, and climate change adaptation, drawing expertise from healthcare, social science, engineering, science, sustainability, and finance. By fostering multidisciplinary dialogue and open research practices, our community can accelerate deployment-centric development for broad societal impact.
Count, Crop and Recognise: Fine-Grained Recognition in the Wild
Oct 09, 2019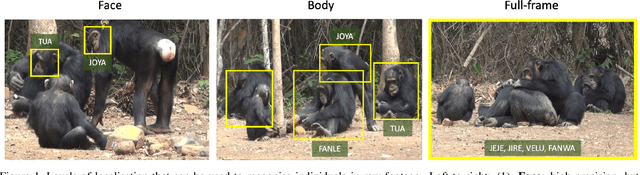
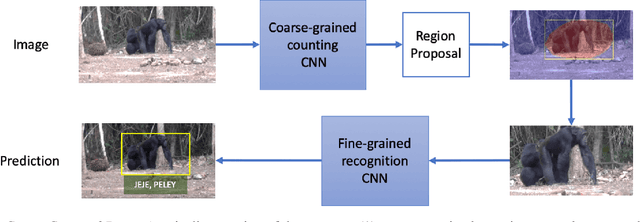


The goal of this paper is to label all the animal individuals present in every frame of a video. Unlike previous methods that have principally concentrated on labelling face tracks, we aim to label individuals even when their faces are not visible. We make the following contributions: (i) we introduce a 'Count, Crop and Recognise' (CCR) multistage recognition process for frame level labelling. The Count and Recognise stages involve specialised CNNs for the task, and we show that this simple staging gives a substantial boost in performance; (ii) we compare the recall using frame based labelling to both face and body track based labelling, and demonstrate the advantage of frame based with CCR for the specified goal; (iii) we introduce a new dataset for chimpanzee recognition in the wild; and (iv) we apply a high-granularity visualisation technique to further understand the learned CNN features for the recognition of chimpanzee individuals.