 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecognizing Co-Speech Gestures in-the-Wild
May 29, 2026While humans naturally gesture during speech, only a sparse subset of these movements are visually depictive and semantically linked to specific spoken words. Current multimodal models struggle to capture these semantic co-speech gestures, heavily bottlenecked by a lack of precisely annotated training data. To address this, we introduce the Gesture Recognition in the Wild (GRW) dataset, the first large-scale benchmark designed to map unconstrained human gestures to specific words with frame-accurate temporal boundaries. Comprising 156,688 manually annotated video clips, GRW spans a highly diverse 150-word taxonomy of physical actions, spatial descriptors, and abstract concepts. We leverage GRW to train video models to (a) classify gestures as semantic or not, (b) recognize the word corresponding to a co-speech gesture, and (c) temporally localize the gesture. We also use GRW to establish benchmarks for these three tasks.
GMOS: Grounding Moving Object Segmentation in 3D Space and Time
May 28, 2026Moving Object Segmentation (MOS) aims to discover, segment, and track objects that move independently of the camera. Current MOS methods, however, exhibit two fundamental limitations: they rely on pre-computed 2D auxiliary modalities such as optical flow or point trajectories that lack 3D geometric information, and they treat motion as a sequence-level attribute, overlooking the instantaneous motion state of each object. We address both by grounding MOS in 3D space and time, and propose GMOS, a framework that operates directly on RGB video to produce 3D-aware, temporally fine-grained segmentation of multiple moving objects, alongside a foreground--background variant GMOS-S for faster deployment. To support training and evaluation in this regime, we curate GMOS-2K, a dataset of 2,210 real-world videos with per-object temporal motion annotations drawn from five established Video Object Segmentation (VOS) benchmarks, and formalise MOS-I ("I" for instantaneous), a temporally fine-grained evaluation protocol with three complementary metrics. GMOS achieves state-of-the-art results across MOS, MOS-I, and Unsupervised VOS benchmarks, while running significantly faster than prior multi-object MOS methods and supporting online inference for streaming deployment.
Recognising BSL Fingerspelling in Continuous Signing Sequences
Mar 19, 2026Fingerspelling is a critical component of British Sign Language (BSL), used to spell proper names, technical terms, and words that lack established lexical signs. Fingerspelling recognition is challenging due to the rapid pace of signing and common letter omissions by native signers, while existing BSL fingerspelling datasets are either small in scale or temporally and letter-wise inaccurate. In this work, we introduce a new large-scale BSL fingerspelling dataset, FS23K, constructed using an iterative annotation framework. In addition, we propose a fingerspelling recognition model that explicitly accounts for bi-manual interactions and mouthing cues. As a result, with refined annotations, our approach halves the character error rate (CER) compared to the prior state of the art on fingerspelling recognition. These findings demonstrate the effectiveness of our method and highlight its potential to support future research in sign language understanding and scalable, automated annotation pipelines. The project page can be found at https://taeinkwon.com/projects/fs23k/.
WISE: A Multimodal Search Engine for Visual Scenes, Audio, Objects, Faces, Speech, and Metadata
Feb 13, 2026In this paper, we present WISE, an open-source audiovisual search engine which integrates a range of multimodal retrieval capabilities into a single, practical tool accessible to users without machine learning expertise. WISE supports natural-language and reverse-image queries at both the scene level (e.g. empty street) and object level (e.g. horse) across images and videos; face-based search for specific individuals; audio retrieval of acoustic events using text (e.g. wood creak) or an audio file; search over automatically transcribed speech; and filtering by user-provided metadata. Rich insights can be obtained by combining queries across modalities -- for example, retrieving German trains from a historical archive by applying the object query "train" and the metadata query "Germany", or searching for a face in a place. By employing vector search techniques, WISE can scale to support efficient retrieval over millions of images or thousands of hours of video. Its modular architecture facilitates the integration of new models. WISE can be deployed locally for private or sensitive collections, and has been applied to various real-world use cases. Our code is open-source and available at https://gitlab.com/vgg/wise/wise.
Perception Test 2025: Challenge Summary and a Unified VQA Extension
Jan 09, 2026The Third Perception Test challenge was organised as a full-day workshop alongside the IEEE/CVF International Conference on Computer Vision (ICCV) 2025. Its primary goal is to benchmark state-of-the-art video models and measure the progress in multimodal perception. This year, the workshop featured 2 guest tracks as well: KiVA (an image understanding challenge) and Physic-IQ (a video generation challenge). In this report, we summarise the results from the main Perception Test challenge, detailing both the existing tasks as well as novel additions to the benchmark. In this iteration, we placed an emphasis on task unification, as this poses a more challenging test for current SOTA multimodal models. The challenge included five consolidated tracks: unified video QA, unified object and point tracking, unified action and sound localisation, grounded video QA, and hour-long video QA, alongside an analysis and interpretability track that is still open for submissions. Notably, the unified video QA track introduced a novel subset that reformulates traditional perception tasks (such as point tracking and temporal action localisation) as multiple-choice video QA questions that video-language models can natively tackle. The unified object and point tracking merged the original object tracking and point tracking tasks, whereas the unified action and sound localisation merged the original temporal action localisation and temporal sound localisation tracks. Accordingly, we required competitors to use unified approaches rather than engineered pipelines with task-specific models. By proposing such a unified challenge, Perception Test 2025 highlights the significant difficulties existing models face when tackling diverse perception tasks through unified interfaces.
CountGD++: Generalized Prompting for Open-World Counting
Dec 29, 2025The flexibility and accuracy of methods for automatically counting objects in images and videos are limited by the way the object can be specified. While existing methods allow users to describe the target object with text and visual examples, the visual examples must be manually annotated inside the image, and there is no way to specify what not to count. To address these gaps, we introduce novel capabilities that expand how the target object can be specified. Specifically, we extend the prompt to enable what not to count to be described with text and/or visual examples, introduce the concept of `pseudo-exemplars' that automate the annotation of visual examples at inference, and extend counting models to accept visual examples from both natural and synthetic external images. We also use our new counting model, CountGD++, as a vision expert agent for an LLM. Together, these contributions expand the prompt flexibility of multi-modal open-world counting and lead to significant improvements in accuracy, efficiency, and generalization across multiple datasets. Code is available at https://github.com/niki-amini-naieni/CountGDPlusPlus.
TARA: Simple and Efficient Time Aware Retrieval Adaptation of MLLMs for Video Understanding
Dec 15, 2025Our objective is to build a general time-aware video-text embedding model for retrieval. To that end, we propose a simple and efficient recipe, dubbed TARA (Time Aware Retrieval Adaptation), to adapt Multimodal LLMs (MLLMs) to a time-aware video-text embedding model without using any video data at all. For evaluating time-awareness in retrieval, we propose a new benchmark with temporally opposite (chiral) actions as hard negatives and curated splits for chiral and non-chiral actions. We show that TARA outperforms all existing video-text models on this chiral benchmark while also achieving strong results on standard benchmarks. Furthermore, we discover additional benefits of TARA beyond time-awareness: (i) TARA embeddings are negation-aware as shown in NegBench benchmark that evaluates negation in video retrieval, (ii) TARA achieves state of the art performance on verb and adverb understanding in videos. Overall, TARA yields a strong, versatile, time-aware video-text embedding model with state of the art zero-shot performance.
Recurrent Video Masked Autoencoders
Dec 15, 2025We present Recurrent Video Masked-Autoencoders (RVM): a novel video representation learning approach that uses a transformer-based recurrent neural network to aggregate dense image features over time, effectively capturing the spatio-temporal structure of natural video data. RVM learns via an asymmetric masked prediction task requiring only a standard pixel reconstruction objective. This design yields a highly efficient ``generalist'' encoder: RVM achieves competitive performance with state-of-the-art video models (e.g. VideoMAE, V-JEPA) on video-level tasks like action recognition and point/object tracking, while also performing favorably against image models (e.g. DINOv2) on tasks that test geometric and dense spatial understanding. Notably, RVM achieves strong performance in the small-model regime without requiring knowledge distillation, exhibiting up to 30x greater parameter efficiency than competing video masked autoencoders. Moreover, we demonstrate that RVM's recurrent nature allows for stable feature propagation over long temporal horizons with linear computational cost, overcoming some of the limitations of standard spatio-temporal attention-based architectures. Finally, we use qualitative visualizations to highlight that RVM learns rich representations of scene semantics, structure, and motion.
Efficiently Reconstructing Dynamic Scenes One D4RT at a Time
Dec 10, 2025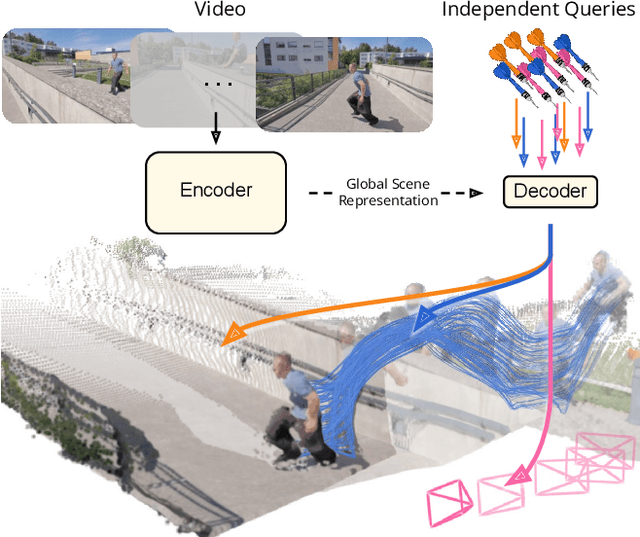

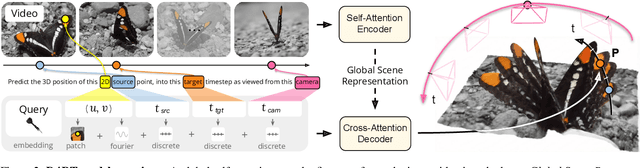
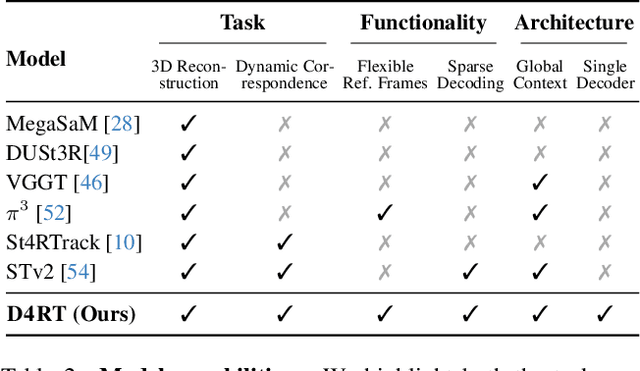
Understanding and reconstructing the complex geometry and motion of dynamic scenes from video remains a formidable challenge in computer vision. This paper introduces D4RT, a simple yet powerful feedforward model designed to efficiently solve this task. D4RT utilizes a unified transformer architecture to jointly infer depth, spatio-temporal correspondence, and full camera parameters from a single video. Its core innovation is a novel querying mechanism that sidesteps the heavy computation of dense, per-frame decoding and the complexity of managing multiple, task-specific decoders. Our decoding interface allows the model to independently and flexibly probe the 3D position of any point in space and time. The result is a lightweight and highly scalable method that enables remarkably efficient training and inference. We demonstrate that our approach sets a new state of the art, outperforming previous methods across a wide spectrum of 4D reconstruction tasks. We refer to the project webpage for animated results: https://d4rt-paper.github.io/.
Lost in Translation, Found in Embeddings: Sign Language Translation and Alignment
Dec 08, 2025

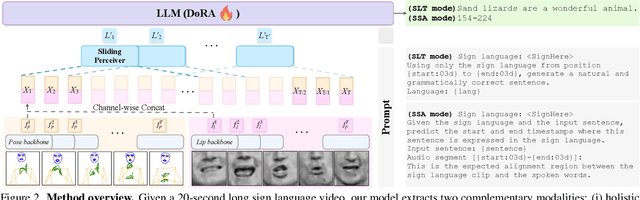
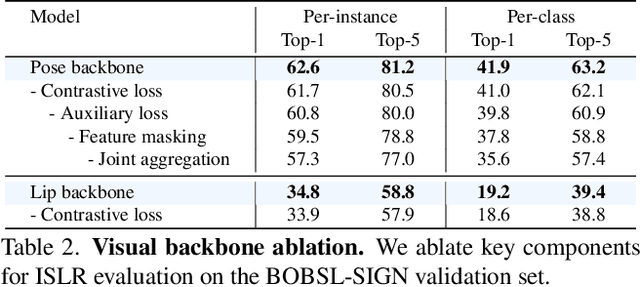
Our aim is to develop a unified model for sign language understanding, that performs sign language translation (SLT) and sign-subtitle alignment (SSA). Together, these two tasks enable the conversion of continuous signing videos into spoken language text and also the temporal alignment of signing with subtitles -- both essential for practical communication, large-scale corpus construction, and educational applications. To achieve this, our approach is built upon three components: (i) a lightweight visual backbone that captures manual and non-manual cues from human keypoints and lip-region images while preserving signer privacy; (ii) a Sliding Perceiver mapping network that aggregates consecutive visual features into word-level embeddings to bridge the vision-text gap; and (iii) a multi-task scalable training strategy that jointly optimises SLT and SSA, reinforcing both linguistic and temporal alignment. To promote cross-linguistic generalisation, we pretrain our model on large-scale sign-text corpora covering British Sign Language (BSL) and American Sign Language (ASL) from the BOBSL and YouTube-SL-25 datasets. With this multilingual pretraining and strong model design, we achieve state-of-the-art results on the challenging BOBSL (BSL) dataset for both SLT and SSA. Our model also demonstrates robust zero-shot generalisation and finetuned SLT performance on How2Sign (ASL), highlighting the potential of scalable translation across different sign languages.