 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficiently Reconstructing Dynamic Scenes One D4RT at a Time
Dec 10, 2025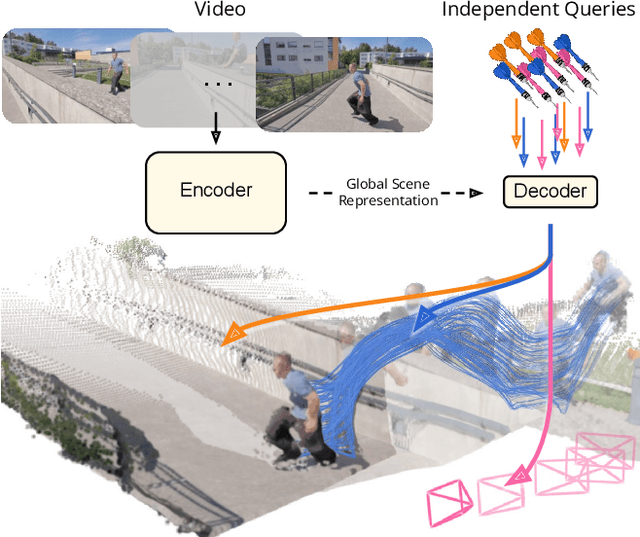

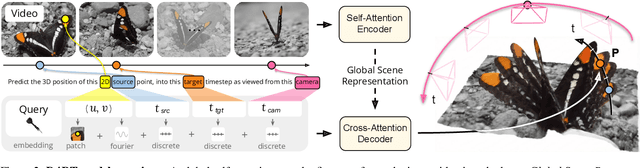
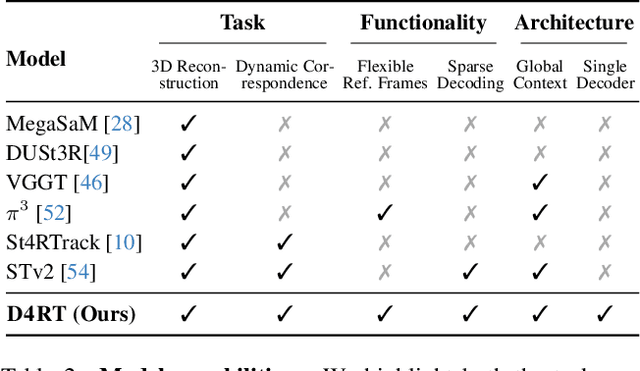
Understanding and reconstructing the complex geometry and motion of dynamic scenes from video remains a formidable challenge in computer vision. This paper introduces D4RT, a simple yet powerful feedforward model designed to efficiently solve this task. D4RT utilizes a unified transformer architecture to jointly infer depth, spatio-temporal correspondence, and full camera parameters from a single video. Its core innovation is a novel querying mechanism that sidesteps the heavy computation of dense, per-frame decoding and the complexity of managing multiple, task-specific decoders. Our decoding interface allows the model to independently and flexibly probe the 3D position of any point in space and time. The result is a lightweight and highly scalable method that enables remarkably efficient training and inference. We demonstrate that our approach sets a new state of the art, outperforming previous methods across a wide spectrum of 4D reconstruction tasks. We refer to the project webpage for animated results: https://d4rt-paper.github.io/.
Lost in Translation, Found in Embeddings: Sign Language Translation and Alignment
Dec 08, 2025

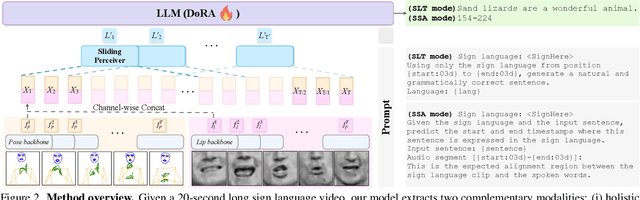
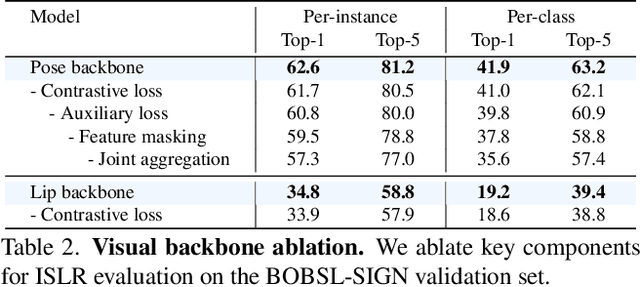
Our aim is to develop a unified model for sign language understanding, that performs sign language translation (SLT) and sign-subtitle alignment (SSA). Together, these two tasks enable the conversion of continuous signing videos into spoken language text and also the temporal alignment of signing with subtitles -- both essential for practical communication, large-scale corpus construction, and educational applications. To achieve this, our approach is built upon three components: (i) a lightweight visual backbone that captures manual and non-manual cues from human keypoints and lip-region images while preserving signer privacy; (ii) a Sliding Perceiver mapping network that aggregates consecutive visual features into word-level embeddings to bridge the vision-text gap; and (iii) a multi-task scalable training strategy that jointly optimises SLT and SSA, reinforcing both linguistic and temporal alignment. To promote cross-linguistic generalisation, we pretrain our model on large-scale sign-text corpora covering British Sign Language (BSL) and American Sign Language (ASL) from the BOBSL and YouTube-SL-25 datasets. With this multilingual pretraining and strong model design, we achieve state-of-the-art results on the challenging BOBSL (BSL) dataset for both SLT and SSA. Our model also demonstrates robust zero-shot generalisation and finetuned SLT performance on How2Sign (ASL), highlighting the potential of scalable translation across different sign languages.
Segment, Embed, and Align: A Universal Recipe for Aligning Subtitles to Signing
Dec 08, 2025The goal of this work is to develop a universal approach for aligning subtitles (i.e., spoken language text with corresponding timestamps) to continuous sign language videos. Prior approaches typically rely on end-to-end training tied to a specific language or dataset, which limits their generality. In contrast, our method Segment, Embed, and Align (SEA) provides a single framework that works across multiple languages and domains. SEA leverages two pretrained models: the first to segment a video frame sequence into individual signs and the second to embed the video clip of each sign into a shared latent space with text. Alignment is subsequently performed with a lightweight dynamic programming procedure that runs efficiently on CPUs within a minute, even for hour-long episodes. SEA is flexible and can adapt to a wide range of scenarios, utilizing resources from small lexicons to large continuous corpora. Experiments on four sign language datasets demonstrate state-of-the-art alignment performance, highlighting the potential of SEA to generate high-quality parallel data for advancing sign language processing. SEA's code and models are openly available.
Lost in Translation, Found in Context: Sign Language Translation with Contextual Cues
Jan 16, 2025



Our objective is to translate continuous sign language into spoken language text. Inspired by the way human interpreters rely on context for accurate translation, we incorporate additional contextual cues together with the signing video, into a new translation framework. Specifically, besides visual sign recognition features that encode the input video, we integrate complementary textual information from (i) captions describing the background show, (ii) translation of previous sentences, as well as (iii) pseudo-glosses transcribing the signing. These are automatically extracted and inputted along with the visual features to a pre-trained large language model (LLM), which we fine-tune to generate spoken language translations in text form. Through extensive ablation studies, we show the positive contribution of each input cue to the translation performance. We train and evaluate our approach on BOBSL -- the largest British Sign Language dataset currently available. We show that our contextual approach significantly enhances the quality of the translations compared to previously reported results on BOBSL, and also to state-of-the-art methods that we implement as baselines. Furthermore, we demonstrate the generality of our approach by applying it also to How2Sign, an American Sign Language dataset, and achieve competitive results.
A Tale of Two Languages: Large-Vocabulary Continuous Sign Language Recognition from Spoken Language Supervision
May 16, 2024
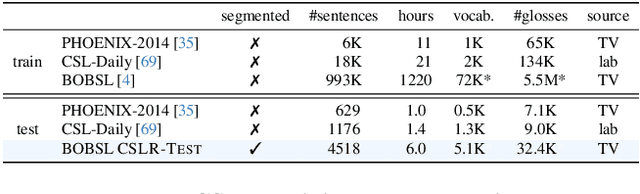
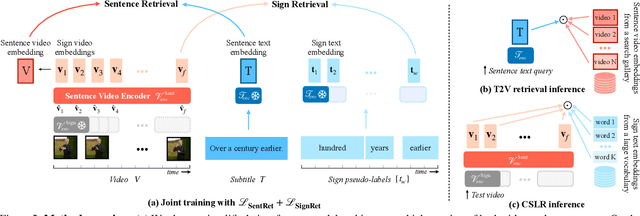

In this work, our goals are two fold: large-vocabulary continuous sign language recognition (CSLR), and sign language retrieval. To this end, we introduce a multi-task Transformer model, CSLR2, that is able to ingest a signing sequence and output in a joint embedding space between signed language and spoken language text. To enable CSLR evaluation in the large-vocabulary setting, we introduce new dataset annotations that have been manually collected. These provide continuous sign-level annotations for six hours of test videos, and will be made publicly available. We demonstrate that by a careful choice of loss functions, training the model for both the CSLR and retrieval tasks is mutually beneficial in terms of performance -- retrieval improves CSLR performance by providing context, while CSLR improves retrieval with more fine-grained supervision. We further show the benefits of leveraging weak and noisy supervision from large-vocabulary datasets such as BOBSL, namely sign-level pseudo-labels, and English subtitles. Our model significantly outperforms the previous state of the art on both tasks.
Verbs in Action: Improving verb understanding in video-language models
Apr 13, 2023
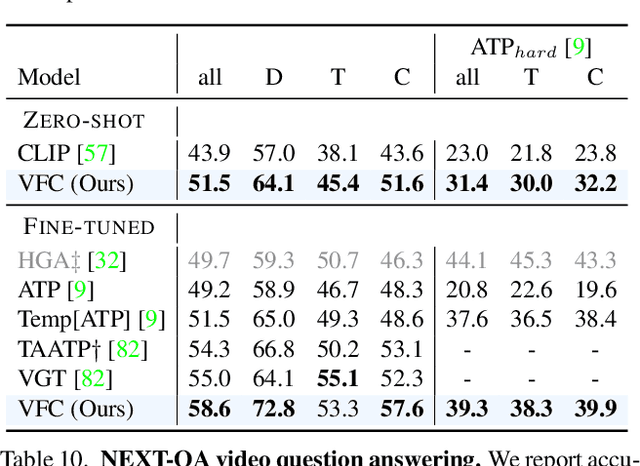
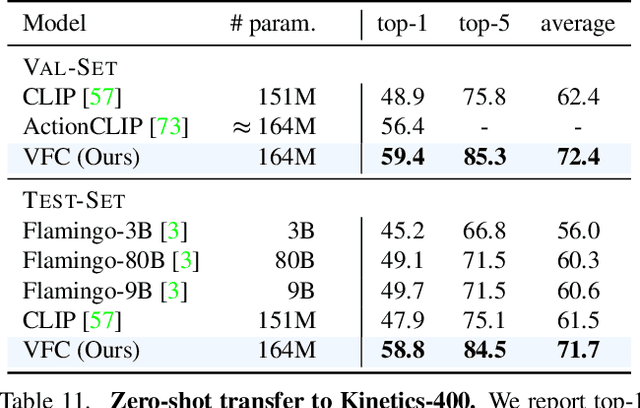
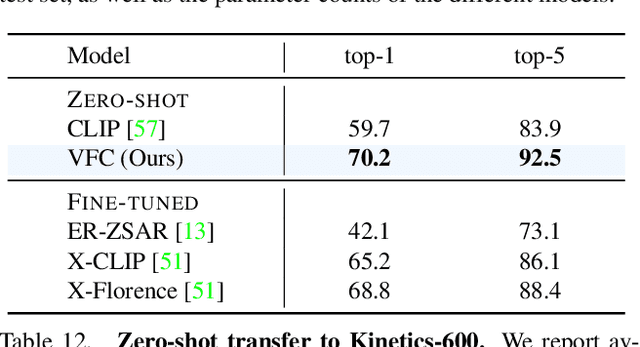
Understanding verbs is crucial to modelling how people and objects interact with each other and the environment through space and time. Recently, state-of-the-art video-language models based on CLIP have been shown to have limited verb understanding and to rely extensively on nouns, restricting their performance in real-world video applications that require action and temporal understanding. In this work, we improve verb understanding for CLIP-based video-language models by proposing a new Verb-Focused Contrastive (VFC) framework. This consists of two main components: (1) leveraging pretrained large language models (LLMs) to create hard negatives for cross-modal contrastive learning, together with a calibration strategy to balance the occurrence of concepts in positive and negative pairs; and (2) enforcing a fine-grained, verb phrase alignment loss. Our method achieves state-of-the-art results for zero-shot performance on three downstream tasks that focus on verb understanding: video-text matching, video question-answering and video classification. To the best of our knowledge, this is the first work which proposes a method to alleviate the verb understanding problem, and does not simply highlight it.
Large Language Models are Few-shot Publication Scoopers
Apr 02, 2023Driven by recent advances AI, we passengers are entering a golden age of scientific discovery. But golden for whom? Confronting our insecurity that others may beat us to the most acclaimed breakthroughs of the era, we propose a novel solution to the long-standing personal credit assignment problem to ensure that it is golden for us. At the heart of our approach is a pip-to-the-post algorithm that assures adulatory Wikipedia pages without incurring the substantial capital and career risks of pursuing high impact science with conventional research methodologies. By leveraging the meta trend of leveraging large language models for everything, we demonstrate the unparalleled potential of our algorithm to scoop groundbreaking findings with the insouciance of a seasoned researcher at a dessert buffet.
Weakly-supervised Fingerspelling Recognition in British Sign Language Videos
Nov 16, 2022



The goal of this work is to detect and recognize sequences of letters signed using fingerspelling in British Sign Language (BSL). Previous fingerspelling recognition methods have not focused on BSL, which has a very different signing alphabet (e.g., two-handed instead of one-handed) to American Sign Language (ASL). They also use manual annotations for training. In contrast to previous methods, our method only uses weak annotations from subtitles for training. We localize potential instances of fingerspelling using a simple feature similarity method, then automatically annotate these instances by querying subtitle words and searching for corresponding mouthing cues from the signer. We propose a Transformer architecture adapted to this task, with a multiple-hypothesis CTC loss function to learn from alternative annotation possibilities. We employ a multi-stage training approach, where we make use of an initial version of our trained model to extend and enhance our training data before re-training again to achieve better performance. Through extensive evaluations, we verify our method for automatic annotation and our model architecture. Moreover, we provide a human expert annotated test set of 5K video clips for evaluating BSL fingerspelling recognition methods to support sign language research.
Automatic dense annotation of large-vocabulary sign language videos
Aug 04, 2022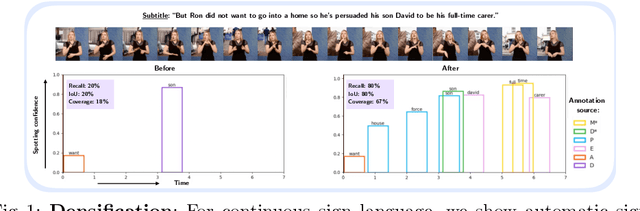

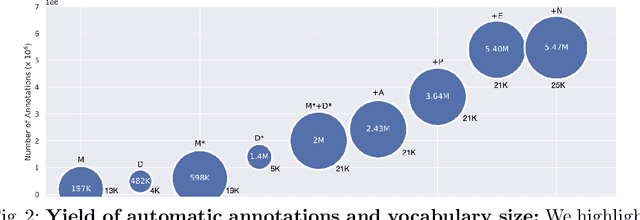
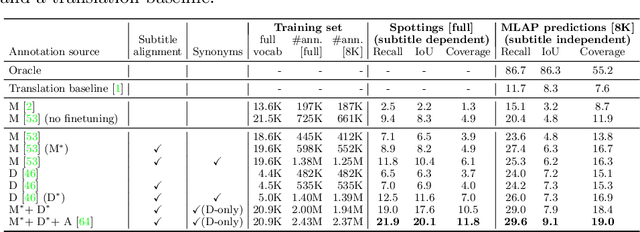
Recently, sign language researchers have turned to sign language interpreted TV broadcasts, comprising (i) a video of continuous signing and (ii) subtitles corresponding to the audio content, as a readily available and large-scale source of training data. One key challenge in the usability of such data is the lack of sign annotations. Previous work exploiting such weakly-aligned data only found sparse correspondences between keywords in the subtitle and individual signs. In this work, we propose a simple, scalable framework to vastly increase the density of automatic annotations. Our contributions are the following: (1) we significantly improve previous annotation methods by making use of synonyms and subtitle-signing alignment; (2) we show the value of pseudo-labelling from a sign recognition model as a way of sign spotting; (3) we propose a novel approach for increasing our annotations of known and unknown classes based on in-domain exemplars; (4) on the BOBSL BSL sign language corpus, we increase the number of confident automatic annotations from 670K to 5M. We make these annotations publicly available to support the sign language research community.
Scaling up sign spotting through sign language dictionaries
May 09, 2022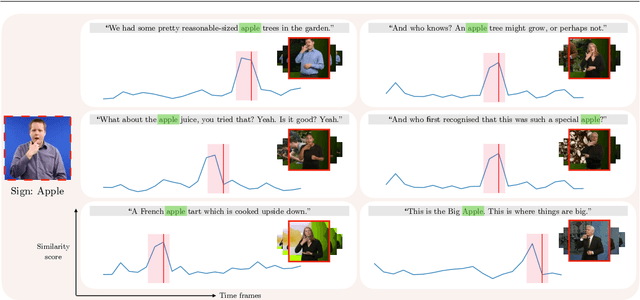
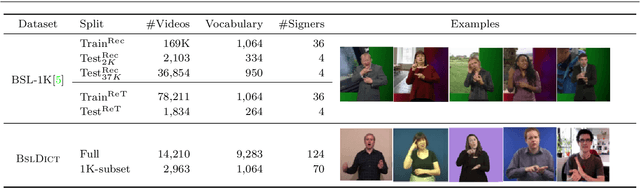
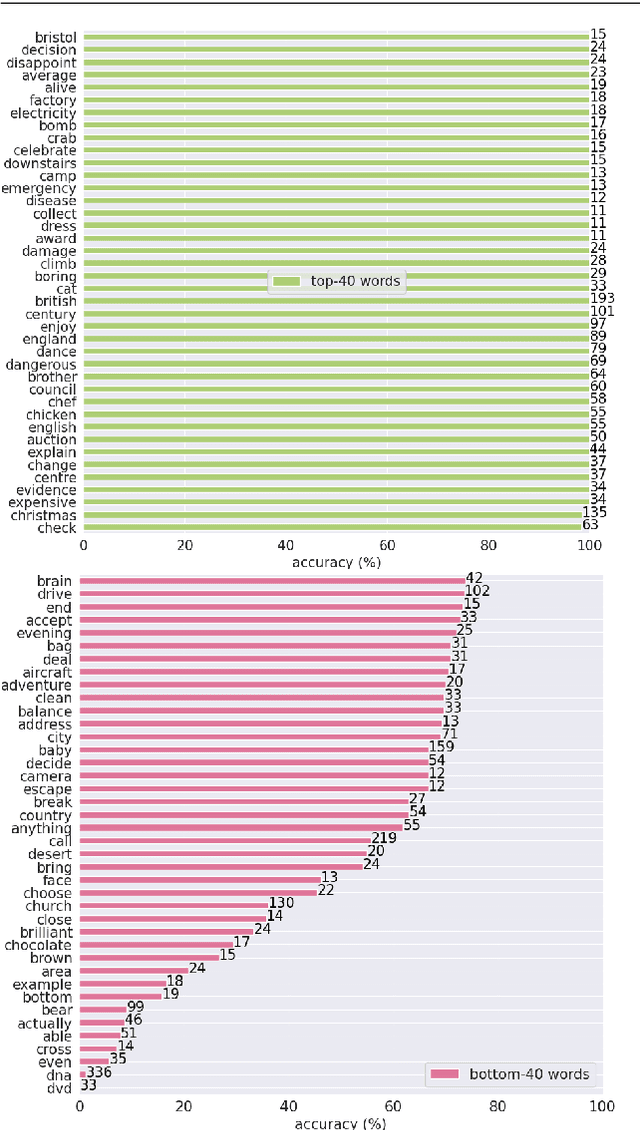
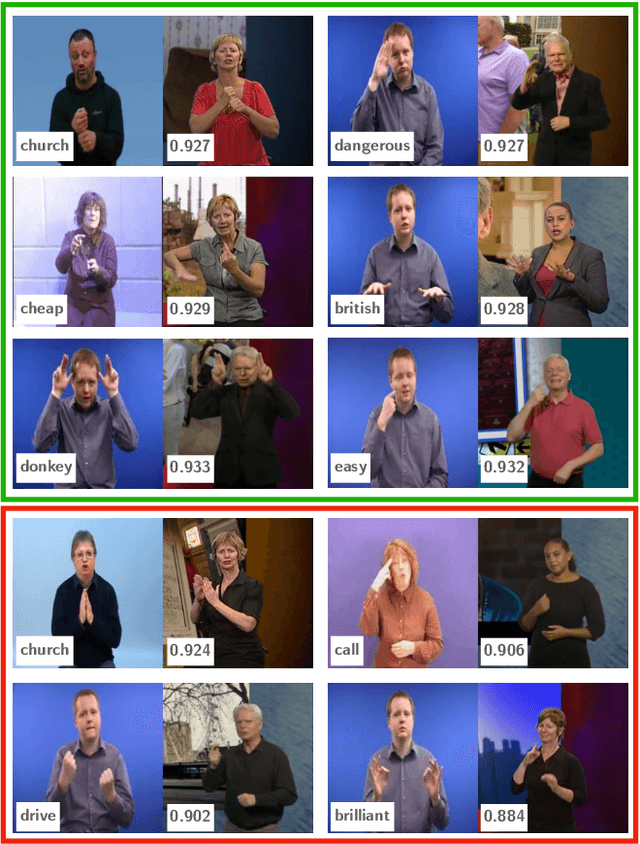
The focus of this work is $\textit{sign spotting}$ - given a video of an isolated sign, our task is to identify $\textit{whether}$ and $\textit{where}$ it has been signed in a continuous, co-articulated sign language video. To achieve this sign spotting task, we train a model using multiple types of available supervision by: (1) $\textit{watching}$ existing footage which is sparsely labelled using mouthing cues; (2) $\textit{reading}$ associated subtitles (readily available translations of the signed content) which provide additional $\textit{weak-supervision}$; (3) $\textit{looking up}$ words (for which no co-articulated labelled examples are available) in visual sign language dictionaries to enable novel sign spotting. These three tasks are integrated into a unified learning framework using the principles of Noise Contrastive Estimation and Multiple Instance Learning. We validate the effectiveness of our approach on low-shot sign spotting benchmarks. In addition, we contribute a machine-readable British Sign Language (BSL) dictionary dataset of isolated signs, BSLDict, to facilitate study of this task. The dataset, models and code are available at our project page.
* Appears in: 2022 International Journal of Computer Vision (IJCV). 25 pages. arXiv admin note: substantial text overlap with arXiv:2010.04002