 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecognizing Co-Speech Gestures in-the-Wild
May 29, 2026While humans naturally gesture during speech, only a sparse subset of these movements are visually depictive and semantically linked to specific spoken words. Current multimodal models struggle to capture these semantic co-speech gestures, heavily bottlenecked by a lack of precisely annotated training data. To address this, we introduce the Gesture Recognition in the Wild (GRW) dataset, the first large-scale benchmark designed to map unconstrained human gestures to specific words with frame-accurate temporal boundaries. Comprising 156,688 manually annotated video clips, GRW spans a highly diverse 150-word taxonomy of physical actions, spatial descriptors, and abstract concepts. We leverage GRW to train video models to (a) classify gestures as semantic or not, (b) recognize the word corresponding to a co-speech gesture, and (c) temporally localize the gesture. We also use GRW to establish benchmarks for these three tasks.
Understanding Co-speech Gestures in-the-wild
Mar 28, 2025
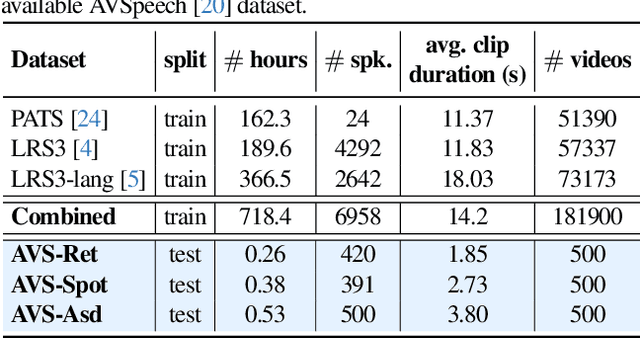
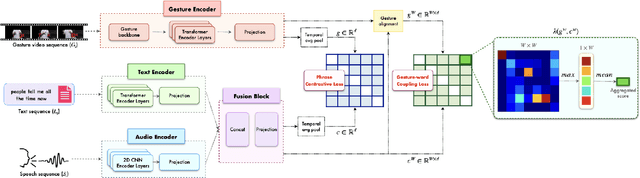
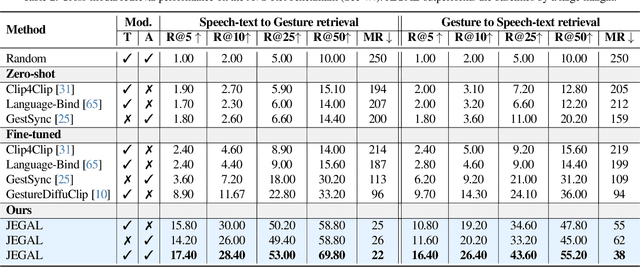
Co-speech gestures play a vital role in non-verbal communication. In this paper, we introduce a new framework for co-speech gesture understanding in the wild. Specifically, we propose three new tasks and benchmarks to evaluate a model's capability to comprehend gesture-text-speech associations: (i) gesture-based retrieval, (ii) gestured word spotting, and (iii) active speaker detection using gestures. We present a new approach that learns a tri-modal speech-text-video-gesture representation to solve these tasks. By leveraging a combination of global phrase contrastive loss and local gesture-word coupling loss, we demonstrate that a strong gesture representation can be learned in a weakly supervised manner from videos in the wild. Our learned representations outperform previous methods, including large vision-language models (VLMs), across all three tasks. Further analysis reveals that speech and text modalities capture distinct gesture-related signals, underscoring the advantages of learning a shared tri-modal embedding space. The dataset, model, and code are available at: https://www.robots.ox.ac.uk/~vgg/research/jegal
MusicFlow: Cascaded Flow Matching for Text Guided Music Generation
Oct 27, 2024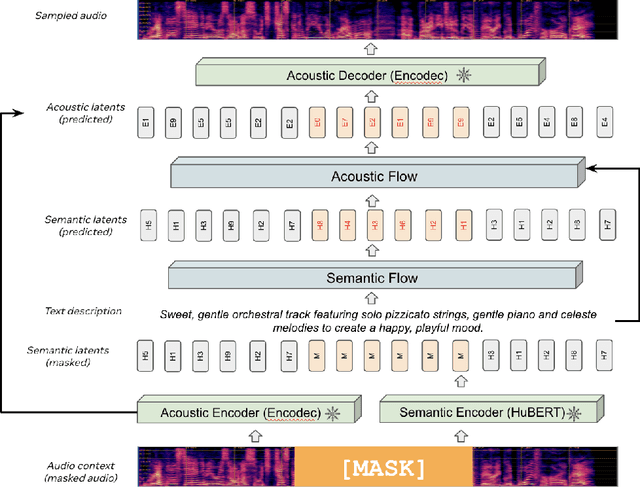
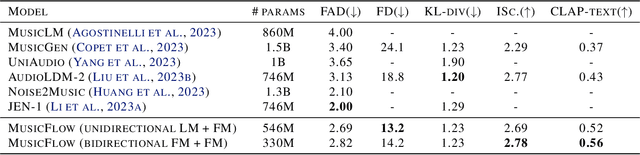
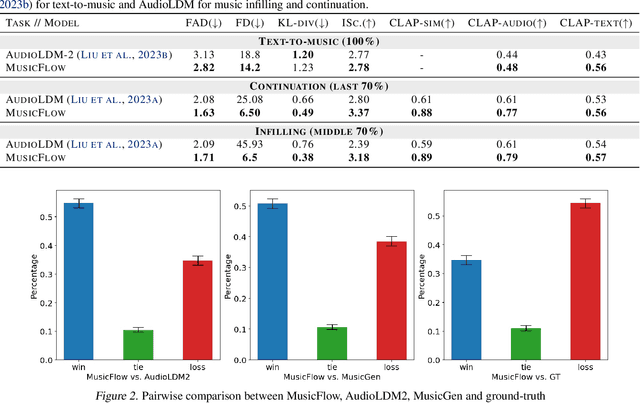
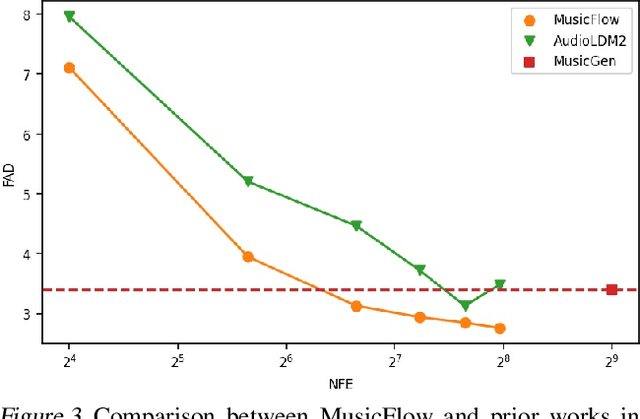
We introduce MusicFlow, a cascaded text-to-music generation model based on flow matching. Based on self-supervised representations to bridge between text descriptions and music audios, we construct two flow matching networks to model the conditional distribution of semantic and acoustic features. Additionally, we leverage masked prediction as the training objective, enabling the model to generalize to other tasks such as music infilling and continuation in a zero-shot manner. Experiments on MusicCaps reveal that the music generated by MusicFlow exhibits superior quality and text coherence despite being over $2\sim5$ times smaller and requiring $5$ times fewer iterative steps. Simultaneously, the model can perform other music generation tasks and achieves competitive performance in music infilling and continuation. Our code and model will be publicly available.
A Tale of Two Languages: Large-Vocabulary Continuous Sign Language Recognition from Spoken Language Supervision
May 16, 2024
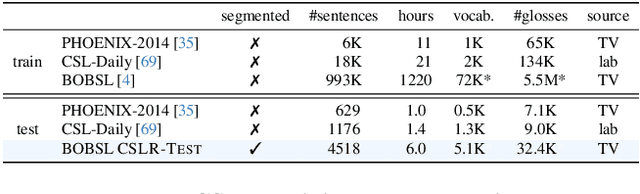
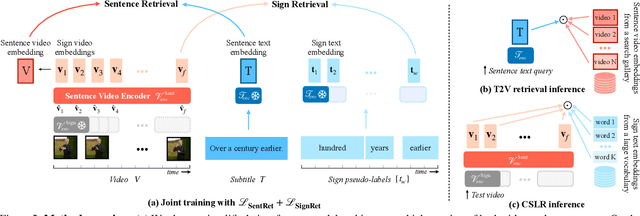

In this work, our goals are two fold: large-vocabulary continuous sign language recognition (CSLR), and sign language retrieval. To this end, we introduce a multi-task Transformer model, CSLR2, that is able to ingest a signing sequence and output in a joint embedding space between signed language and spoken language text. To enable CSLR evaluation in the large-vocabulary setting, we introduce new dataset annotations that have been manually collected. These provide continuous sign-level annotations for six hours of test videos, and will be made publicly available. We demonstrate that by a careful choice of loss functions, training the model for both the CSLR and retrieval tasks is mutually beneficial in terms of performance -- retrieval improves CSLR performance by providing context, while CSLR improves retrieval with more fine-grained supervision. We further show the benefits of leveraging weak and noisy supervision from large-vocabulary datasets such as BOBSL, namely sign-level pseudo-labels, and English subtitles. Our model significantly outperforms the previous state of the art on both tasks.
Weakly-supervised Fingerspelling Recognition in British Sign Language Videos
Nov 16, 2022



The goal of this work is to detect and recognize sequences of letters signed using fingerspelling in British Sign Language (BSL). Previous fingerspelling recognition methods have not focused on BSL, which has a very different signing alphabet (e.g., two-handed instead of one-handed) to American Sign Language (ASL). They also use manual annotations for training. In contrast to previous methods, our method only uses weak annotations from subtitles for training. We localize potential instances of fingerspelling using a simple feature similarity method, then automatically annotate these instances by querying subtitle words and searching for corresponding mouthing cues from the signer. We propose a Transformer architecture adapted to this task, with a multiple-hypothesis CTC loss function to learn from alternative annotation possibilities. We employ a multi-stage training approach, where we make use of an initial version of our trained model to extend and enhance our training data before re-training again to achieve better performance. Through extensive evaluations, we verify our method for automatic annotation and our model architecture. Moreover, we provide a human expert annotated test set of 5K video clips for evaluating BSL fingerspelling recognition methods to support sign language research.
Lip-to-Speech Synthesis for Arbitrary Speakers in the Wild
Sep 01, 2022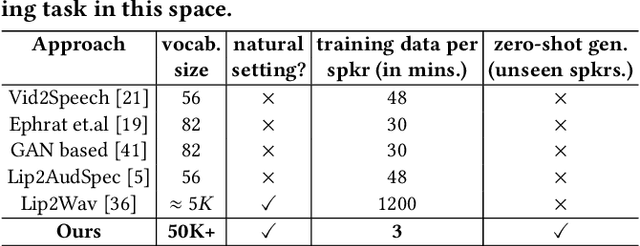
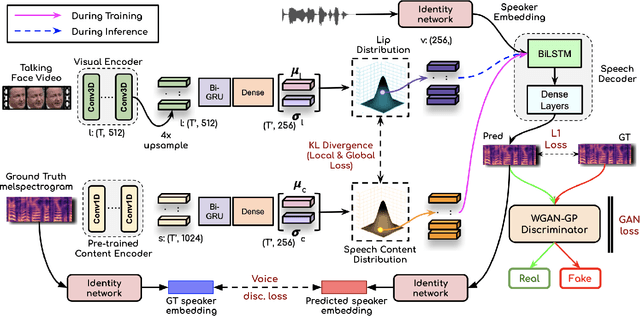
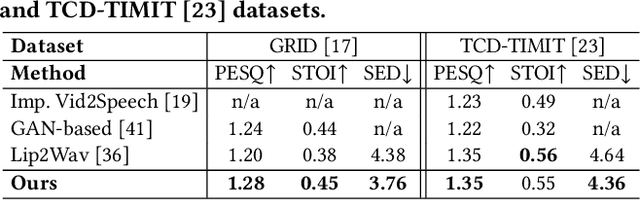
In this work, we address the problem of generating speech from silent lip videos for any speaker in the wild. In stark contrast to previous works, our method (i) is not restricted to a fixed number of speakers, (ii) does not explicitly impose constraints on the domain or the vocabulary and (iii) deals with videos that are recorded in the wild as opposed to within laboratory settings. The task presents a host of challenges, with the key one being that many features of the desired target speech, like voice, pitch and linguistic content, cannot be entirely inferred from the silent face video. In order to handle these stochastic variations, we propose a new VAE-GAN architecture that learns to associate the lip and speech sequences amidst the variations. With the help of multiple powerful discriminators that guide the training process, our generator learns to synthesize speech sequences in any voice for the lip movements of any person. Extensive experiments on multiple datasets show that we outperform all baselines by a large margin. Further, our network can be fine-tuned on videos of specific identities to achieve a performance comparable to single-speaker models that are trained on $4\times$ more data. We conduct numerous ablation studies to analyze the effect of different modules of our architecture. We also provide a demo video that demonstrates several qualitative results along with the code and trained models on our website: \url{http://cvit.iiit.ac.in/research/projects/cvit-projects/lip-to-speech-synthesis}}
Automatic dense annotation of large-vocabulary sign language videos
Aug 04, 2022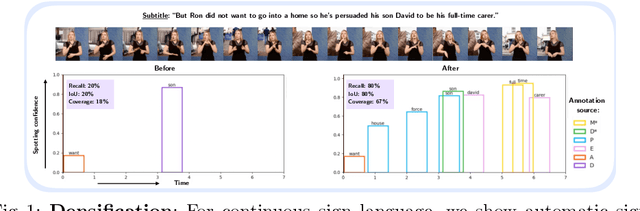

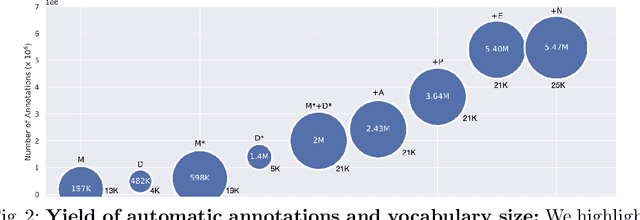
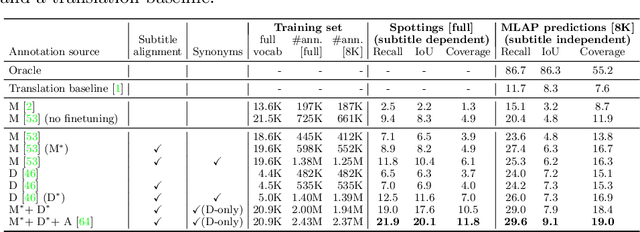
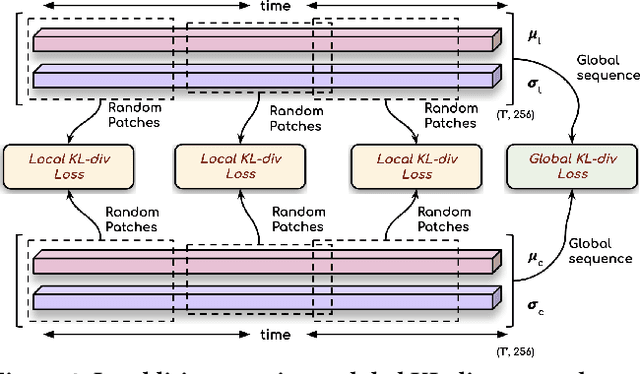
Recently, sign language researchers have turned to sign language interpreted TV broadcasts, comprising (i) a video of continuous signing and (ii) subtitles corresponding to the audio content, as a readily available and large-scale source of training data. One key challenge in the usability of such data is the lack of sign annotations. Previous work exploiting such weakly-aligned data only found sparse correspondences between keywords in the subtitle and individual signs. In this work, we propose a simple, scalable framework to vastly increase the density of automatic annotations. Our contributions are the following: (1) we significantly improve previous annotation methods by making use of synonyms and subtitle-signing alignment; (2) we show the value of pseudo-labelling from a sign recognition model as a way of sign spotting; (3) we propose a novel approach for increasing our annotations of known and unknown classes based on in-domain exemplars; (4) on the BOBSL BSL sign language corpus, we increase the number of confident automatic annotations from 670K to 5M. We make these annotations publicly available to support the sign language research community.
Visual Keyword Spotting with Attention
Oct 29, 2021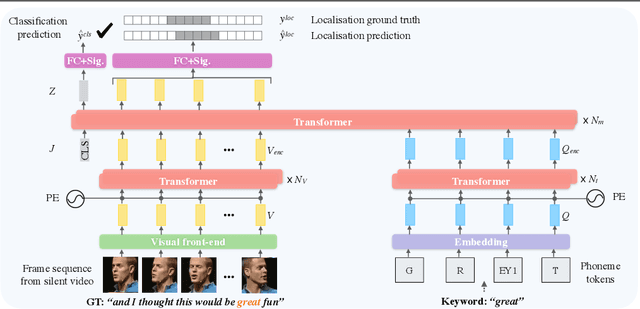
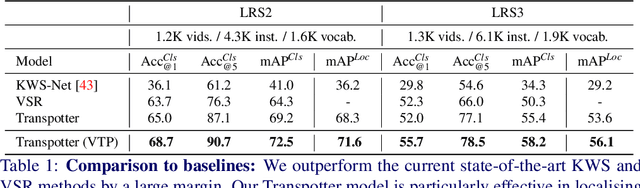

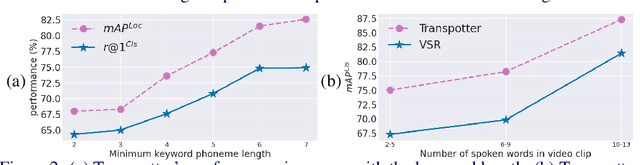
In this paper, we consider the task of spotting spoken keywords in silent video sequences -- also known as visual keyword spotting. To this end, we investigate Transformer-based models that ingest two streams, a visual encoding of the video and a phonetic encoding of the keyword, and output the temporal location of the keyword if present. Our contributions are as follows: (1) We propose a novel architecture, the Transpotter, that uses full cross-modal attention between the visual and phonetic streams; (2) We show through extensive evaluations that our model outperforms the prior state-of-the-art visual keyword spotting and lip reading methods on the challenging LRW, LRS2, LRS3 datasets by a large margin; (3) We demonstrate the ability of our model to spot words under the extreme conditions of isolated mouthings in sign language videos.
Visual Speech Enhancement Without A Real Visual Stream
Dec 20, 2020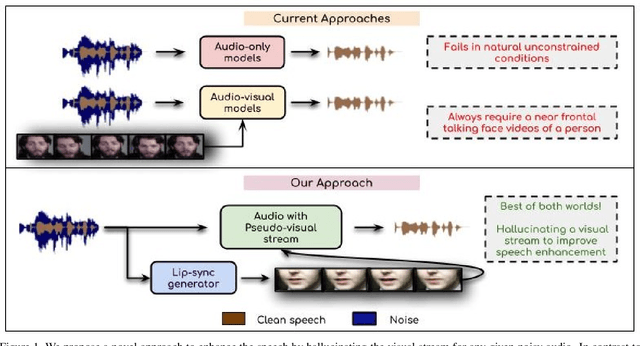

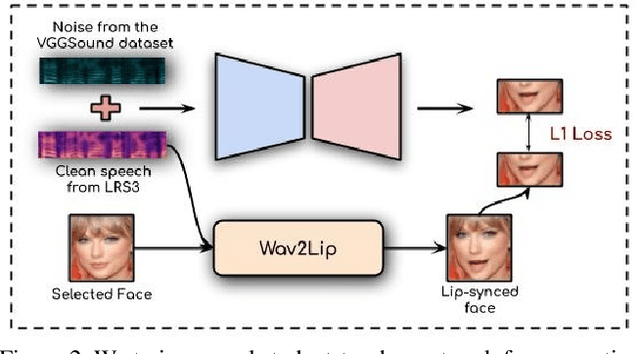
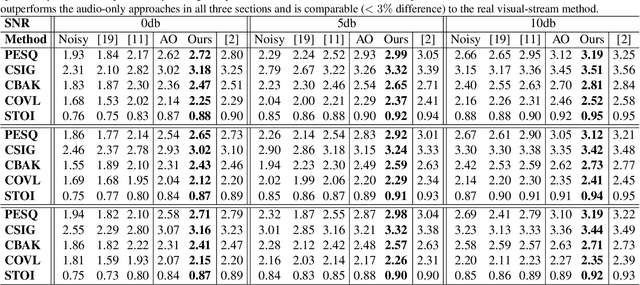
In this work, we re-think the task of speech enhancement in unconstrained real-world environments. Current state-of-the-art methods use only the audio stream and are limited in their performance in a wide range of real-world noises. Recent works using lip movements as additional cues improve the quality of generated speech over "audio-only" methods. But, these methods cannot be used for several applications where the visual stream is unreliable or completely absent. We propose a new paradigm for speech enhancement by exploiting recent breakthroughs in speech-driven lip synthesis. Using one such model as a teacher network, we train a robust student network to produce accurate lip movements that mask away the noise, thus acting as a "visual noise filter". The intelligibility of the speech enhanced by our pseudo-lip approach is comparable (< 3% difference) to the case of using real lips. This implies that we can exploit the advantages of using lip movements even in the absence of a real video stream. We rigorously evaluate our model using quantitative metrics as well as human evaluations. Additional ablation studies and a demo video on our website containing qualitative comparisons and results clearly illustrate the effectiveness of our approach. We provide a demo video which clearly illustrates the effectiveness of our proposed approach on our website: \url{http://cvit.iiit.ac.in/research/projects/cvit-projects/visual-speech-enhancement-without-a-real-visual-stream}. The code and models are also released for future research: \url{https://github.com/Sindhu-Hegde/pseudo-visual-speech-denoising}.
A Lip Sync Expert Is All You Need for Speech to Lip Generation In The Wild
Aug 23, 2020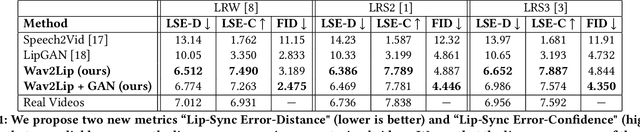
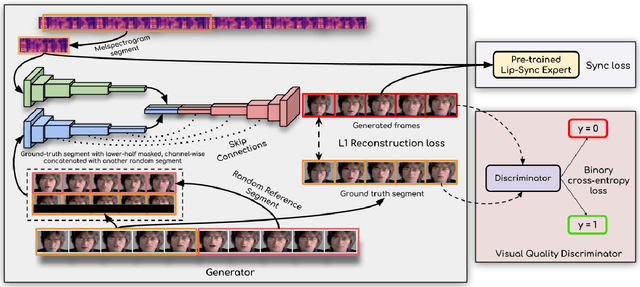
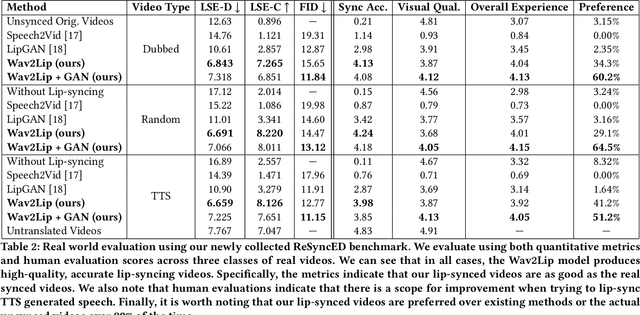
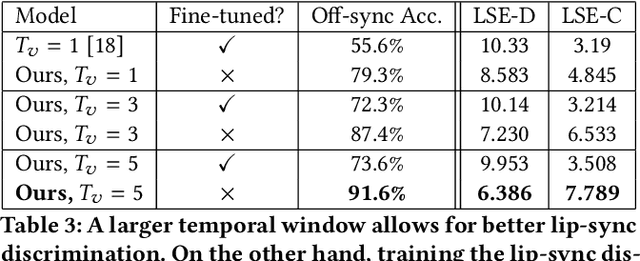
In this work, we investigate the problem of lip-syncing a talking face video of an arbitrary identity to match a target speech segment. Current works excel at producing accurate lip movements on a static image or videos of specific people seen during the training phase. However, they fail to accurately morph the lip movements of arbitrary identities in dynamic, unconstrained talking face videos, resulting in significant parts of the video being out-of-sync with the new audio. We identify key reasons pertaining to this and hence resolve them by learning from a powerful lip-sync discriminator. Next, we propose new, rigorous evaluation benchmarks and metrics to accurately measure lip synchronization in unconstrained videos. Extensive quantitative evaluations on our challenging benchmarks show that the lip-sync accuracy of the videos generated by our Wav2Lip model is almost as good as real synced videos. We provide a demo video clearly showing the substantial impact of our Wav2Lip model and evaluation benchmarks on our website: \url{cvit.iiit.ac.in/research/projects/cvit-projects/a-lip-sync-expert-is-all-you-need-for-speech-to-lip-generation-in-the-wild}. The code and models are released at this GitHub repository: \url{github.com/Rudrabha/Wav2Lip}. You can also try out the interactive demo at this link: \url{bhaasha.iiit.ac.in/lipsync}.