 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIPPER: Direct Preference Optimization to Accelerate Primitive-Enabled Hierarchical Reinforcement Learning
Jun 16, 2024Learning control policies to perform complex robotics tasks from human preference data presents significant challenges. On the one hand, the complexity of such tasks typically requires learning policies to perform a variety of subtasks, then combining them to achieve the overall goal. At the same time, comprehensive, well-engineered reward functions are typically unavailable in such problems, while limited human preference data often is; making efficient use of such data to guide learning is therefore essential. Methods for learning to perform complex robotics tasks from human preference data must overcome both these challenges simultaneously. In this work, we introduce DIPPER: Direct Preference Optimization to Accelerate Primitive-Enabled Hierarchical Reinforcement Learning, an efficient hierarchical approach that leverages direct preference optimization to learn a higher-level policy and reinforcement learning to learn a lower-level policy. DIPPER enjoys improved computational efficiency due to its use of direct preference optimization instead of standard preference-based approaches such as reinforcement learning from human feedback, while it also mitigates the well-known hierarchical reinforcement learning issues of non-stationarity and infeasible subgoal generation due to our use of primitive-informed regularization inspired by a novel bi-level optimization formulation of the hierarchical reinforcement learning problem. To validate our approach, we perform extensive experimental analysis on a variety of challenging robotics tasks, demonstrating that DIPPER outperforms hierarchical and non-hierarchical baselines, while ameliorating the non-stationarity and infeasible subgoal generation issues of hierarchical reinforcement learning.
PEAR: Primitive enabled Adaptive Relabeling for boosting Hierarchical Reinforcement Learning
Jun 10, 2023Hierarchical reinforcement learning (HRL) has the potential to solve complex long horizon tasks using temporal abstraction and increased exploration. However, hierarchical agents are difficult to train as they suffer from inherent non-stationarity due to continuously changing low level primitive. We present primitive enabled adaptive relabeling (PEAR), a two-phase approach where firstly we perform adaptive relabeling on a few expert demonstrations to generate subgoal supervision dataset, and then employ imitation learning for regularizing HRL agents. We bound the sub-optimality of our method using theoretical bounds and devise a practical HRL algorithm for solving complex robotic tasks. We perform experiments on challenging robotic tasks: maze navigation, pick and place, rope manipulation and kitchen environments, and demonstrate that the proposed approach is able to solve complex tasks that require long term decision making. Since our method uses a handful of expert demonstrations and makes minimal limiting assumptions on task structure, it can be easily integrated with typical model free reinforcement learning algorithms to solve most robotic tasks. We empirically show that our approach outperforms previous hierarchical and non-hierarchical baselines, and exhibits better sample efficiency. We also perform real world robotic experiments by deploying the learned policy on a real robotic rope manipulation task and demonstrate that PEAR consistently outperforms the baselines. Here is the link for supplementary video: \url{https://tinyurl.com/pearOverview}
CRISP: Curriculum inducing Primitive Informed Subgoal Prediction for Hierarchical Reinforcement Learning
Apr 07, 2023Hierarchical reinforcement learning is a promising approach that uses temporal abstraction to solve complex long horizon problems. However, simultaneously learning a hierarchy of policies is unstable as it is challenging to train higher-level policy when the lower-level primitive is non-stationary. In this paper, we propose a novel hierarchical algorithm by generating a curriculum of achievable subgoals for evolving lower-level primitives using reinforcement learning and imitation learning. The lower level primitive periodically performs data relabeling on a handful of expert demonstrations using our primitive informed parsing approach. We provide expressions to bound the sub-optimality of our method and develop a practical algorithm for hierarchical reinforcement learning. Since our approach uses a handful of expert demonstrations, it is suitable for most robotic control tasks. Experimental evaluation on complex maze navigation and robotic manipulation environments show that inducing hierarchical curriculum learning significantly improves sample efficiency, and results in efficient goal conditioned policies for solving temporally extended tasks.
INR-V: A Continuous Representation Space for Video-based Generative Tasks
Oct 29, 2022

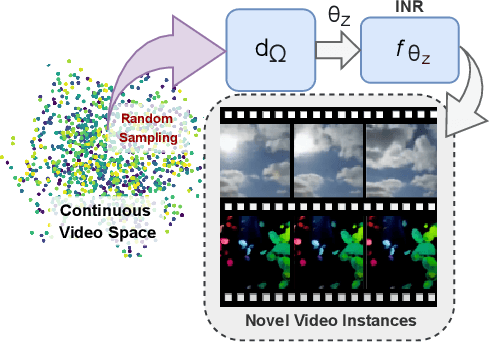
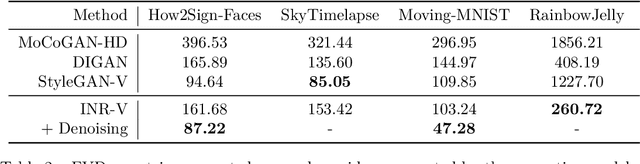
Generating videos is a complex task that is accomplished by generating a set of temporally coherent images frame-by-frame. This limits the expressivity of videos to only image-based operations on the individual video frames needing network designs to obtain temporally coherent trajectories in the underlying image space. We propose INR-V, a video representation network that learns a continuous space for video-based generative tasks. INR-V parameterizes videos using implicit neural representations (INRs), a multi-layered perceptron that predicts an RGB value for each input pixel location of the video. The INR is predicted using a meta-network which is a hypernetwork trained on neural representations of multiple video instances. Later, the meta-network can be sampled to generate diverse novel videos enabling many downstream video-based generative tasks. Interestingly, we find that conditional regularization and progressive weight initialization play a crucial role in obtaining INR-V. The representation space learned by INR-V is more expressive than an image space showcasing many interesting properties not possible with the existing works. For instance, INR-V can smoothly interpolate intermediate videos between known video instances (such as intermediate identities, expressions, and poses in face videos). It can also in-paint missing portions in videos to recover temporally coherent full videos. In this work, we evaluate the space learned by INR-V on diverse generative tasks such as video interpolation, novel video generation, video inversion, and video inpainting against the existing baselines. INR-V significantly outperforms the baselines on several of these demonstrated tasks, clearly showcasing the potential of the proposed representation space.
Lip-to-Speech Synthesis for Arbitrary Speakers in the Wild
Sep 01, 2022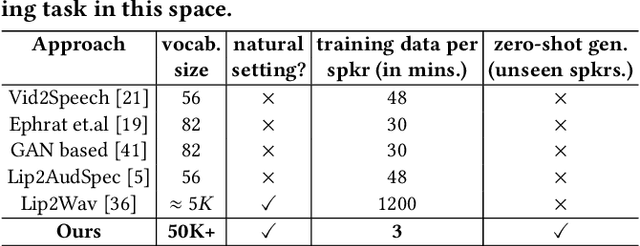
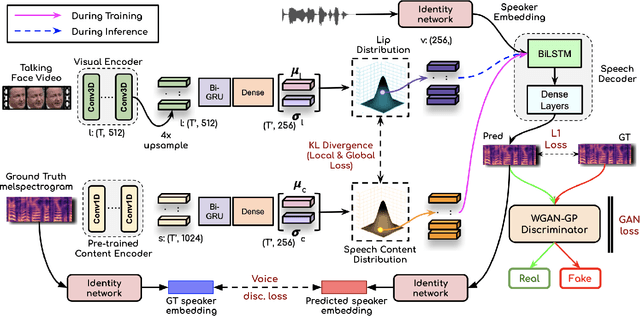
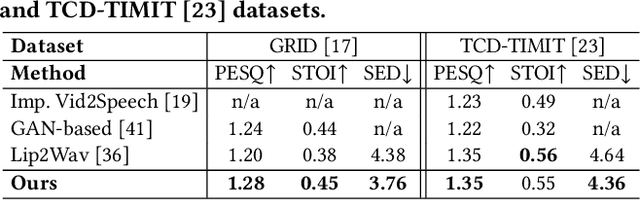
In this work, we address the problem of generating speech from silent lip videos for any speaker in the wild. In stark contrast to previous works, our method (i) is not restricted to a fixed number of speakers, (ii) does not explicitly impose constraints on the domain or the vocabulary and (iii) deals with videos that are recorded in the wild as opposed to within laboratory settings. The task presents a host of challenges, with the key one being that many features of the desired target speech, like voice, pitch and linguistic content, cannot be entirely inferred from the silent face video. In order to handle these stochastic variations, we propose a new VAE-GAN architecture that learns to associate the lip and speech sequences amidst the variations. With the help of multiple powerful discriminators that guide the training process, our generator learns to synthesize speech sequences in any voice for the lip movements of any person. Extensive experiments on multiple datasets show that we outperform all baselines by a large margin. Further, our network can be fine-tuned on videos of specific identities to achieve a performance comparable to single-speaker models that are trained on $4\times$ more data. We conduct numerous ablation studies to analyze the effect of different modules of our architecture. We also provide a demo video that demonstrates several qualitative results along with the code and trained models on our website: \url{http://cvit.iiit.ac.in/research/projects/cvit-projects/lip-to-speech-synthesis}}
Extreme-scale Talking-Face Video Upsampling with Audio-Visual Priors
Aug 17, 2022

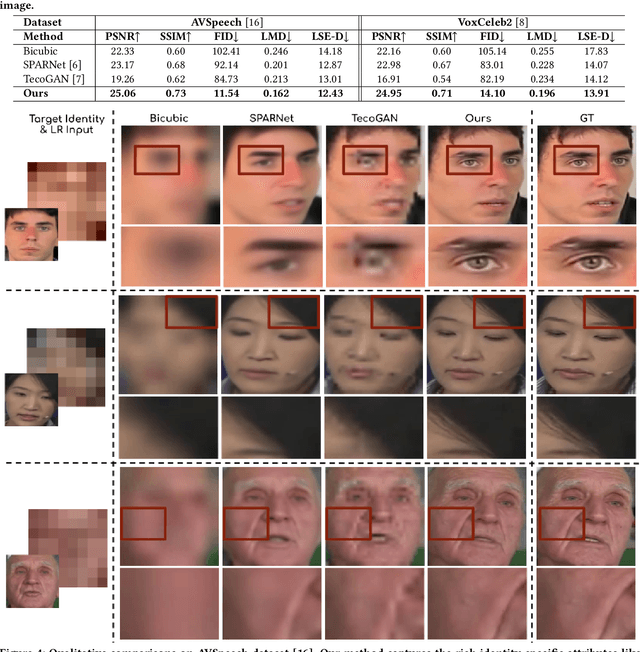
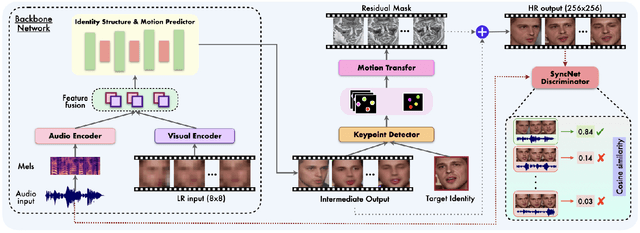
In this paper, we explore an interesting question of what can be obtained from an $8\times8$ pixel video sequence. Surprisingly, it turns out to be quite a lot. We show that when we process this $8\times8$ video with the right set of audio and image priors, we can obtain a full-length, $256\times256$ video. We achieve this $32\times$ scaling of an extremely low-resolution input using our novel audio-visual upsampling network. The audio prior helps to recover the elemental facial details and precise lip shapes and a single high-resolution target identity image prior provides us with rich appearance details. Our approach is an end-to-end multi-stage framework. The first stage produces a coarse intermediate output video that can be then used to animate single target identity image and generate realistic, accurate and high-quality outputs. Our approach is simple and performs exceedingly well (an $8\times$ improvement in FID score) compared to previous super-resolution methods. We also extend our model to talking-face video compression, and show that we obtain a $3.5\times$ improvement in terms of bits/pixel over the previous state-of-the-art. The results from our network are thoroughly analyzed through extensive ablation experiments (in the paper and supplementary material). We also provide the demo video along with code and models on our website: \url{http://cvit.iiit.ac.in/research/projects/cvit-projects/talking-face-video-upsampling}.
Mitigating Uncertainty of Classifier for Unsupervised Domain Adaptation
Jul 01, 2021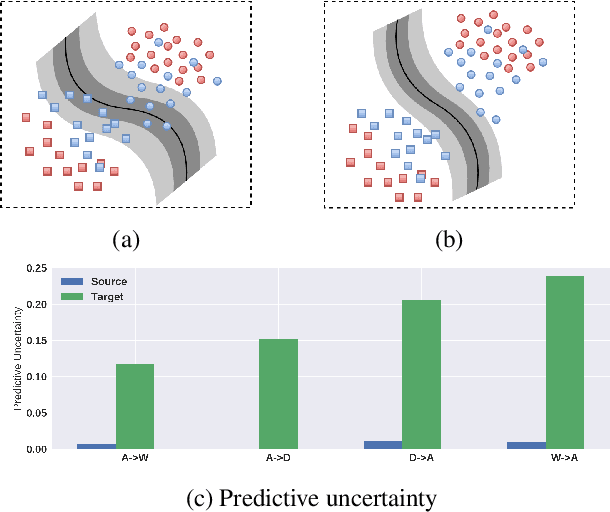
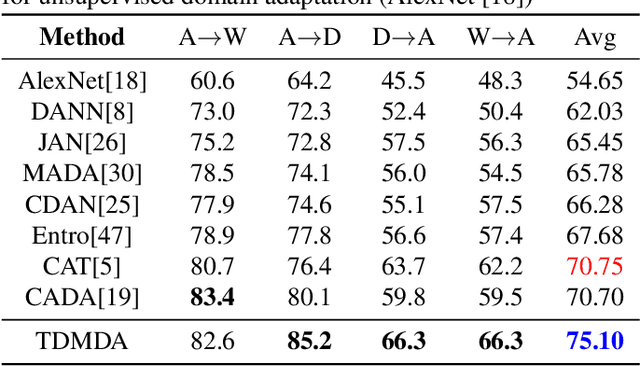

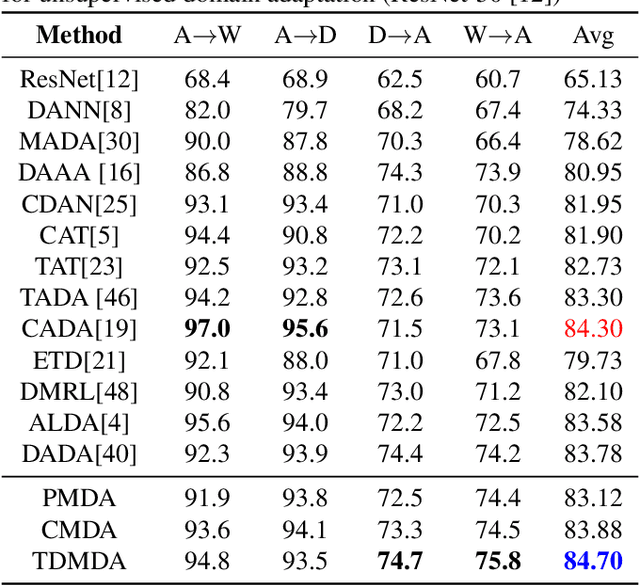
Understanding unsupervised domain adaptation has been an important task that has been well explored. However, the wide variety of methods have not analyzed the role of a classifier's performance in detail. In this paper, we thoroughly examine the role of a classifier in terms of matching source and target distributions. We specifically investigate the classifier ability by matching a) the distribution of features, b) probabilistic uncertainty for samples and c) certainty activation mappings. Our analysis suggests that using these three distributions does result in a consistently improved performance on all the datasets. Our work thus extends present knowledge on the role of the various distributions obtained from the classifier towards solving unsupervised domain adaptation.
Collaborative Learning to Generate Audio-Video Jointly
Apr 01, 2021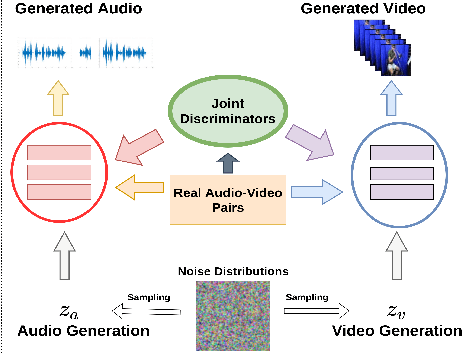

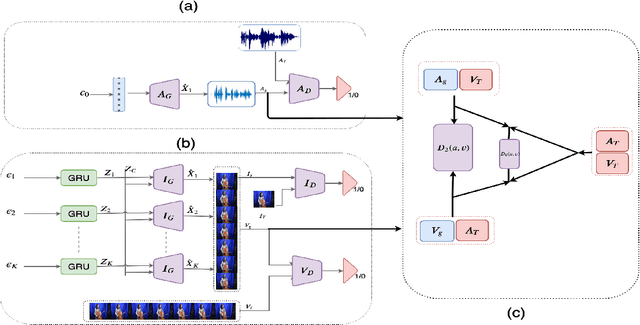

There have been a number of techniques that have demonstrated the generation of multimedia data for one modality at a time using GANs, such as the ability to generate images, videos, and audio. However, so far, the task of multi-modal generation of data, specifically for audio and videos both, has not been sufficiently well-explored. Towards this, we propose a method that demonstrates that we are able to generate naturalistic samples of video and audio data by the joint correlated generation of audio and video modalities. The proposed method uses multiple discriminators to ensure that the audio, video, and the joint output are also indistinguishable from real-world samples. We present a dataset for this task and show that we are able to generate realistic samples. This method is validated using various standard metrics such as Inception Score, Frechet Inception Distance (FID) and through human evaluation.
Domain Impression: A Source Data Free Domain Adaptation Method
Feb 17, 2021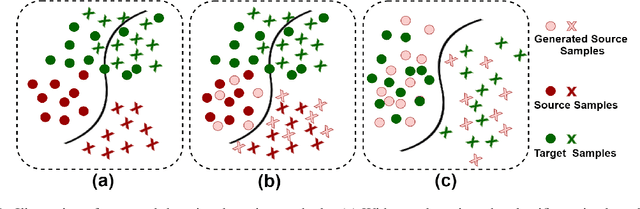
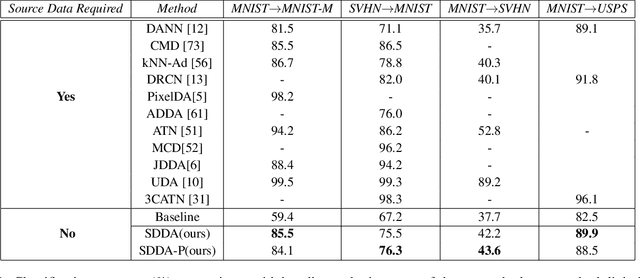
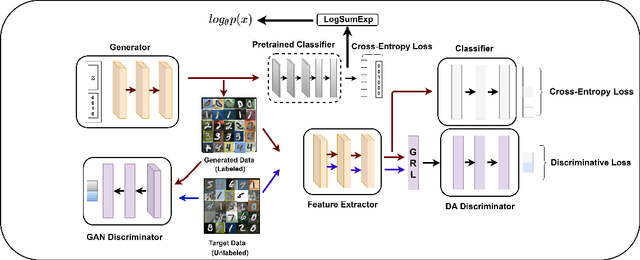
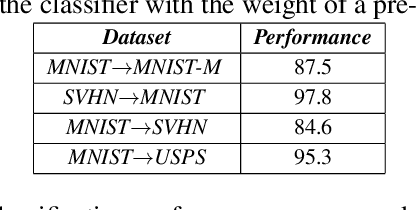
Unsupervised Domain adaptation methods solve the adaptation problem for an unlabeled target set, assuming that the source dataset is available with all labels. However, the availability of actual source samples is not always possible in practical cases. It could be due to memory constraints, privacy concerns, and challenges in sharing data. This practical scenario creates a bottleneck in the domain adaptation problem. This paper addresses this challenging scenario by proposing a domain adaptation technique that does not need any source data. Instead of the source data, we are only provided with a classifier that is trained on the source data. Our proposed approach is based on a generative framework, where the trained classifier is used for generating samples from the source classes. We learn the joint distribution of data by using the energy-based modeling of the trained classifier. At the same time, a new classifier is also adapted for the target domain. We perform various ablation analysis under different experimental setups and demonstrate that the proposed approach achieves better results than the baseline models in this extremely novel scenario.
Stochastic Talking Face Generation Using Latent Distribution Matching
Nov 21, 2020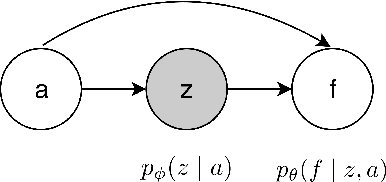
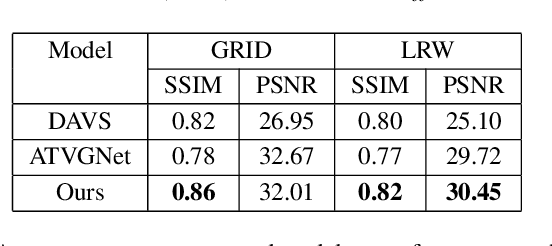
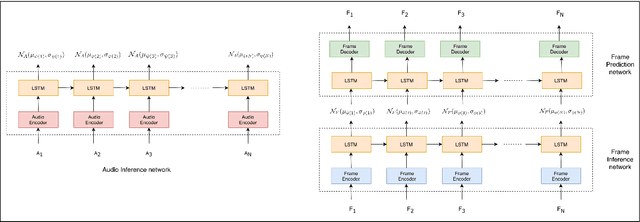
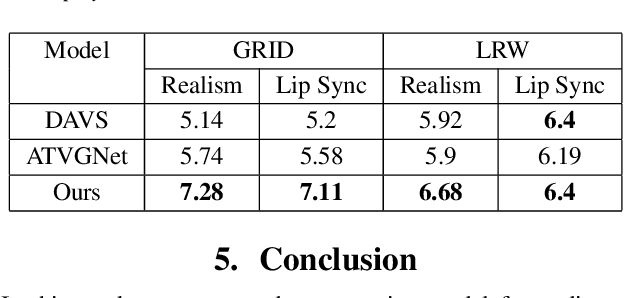
The ability to envisage the visual of a talking face based just on hearing a voice is a unique human capability. There have been a number of works that have solved for this ability recently. We differ from these approaches by enabling a variety of talking face generations based on single audio input. Indeed, just having the ability to generate a single talking face would make a system almost robotic in nature. In contrast, our unsupervised stochastic audio-to-video generation model allows for diverse generations from a single audio input. Particularly, we present an unsupervised stochastic audio-to-video generation model that can capture multiple modes of the video distribution. We ensure that all the diverse generations are plausible. We do so through a principled multi-modal variational autoencoder framework. We demonstrate its efficacy on the challenging LRW and GRID datasets and demonstrate performance better than the baseline, while having the ability to generate multiple diverse lip synchronized videos.