 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Dropout Discriminator for Domain Adaptation
Jul 09, 2021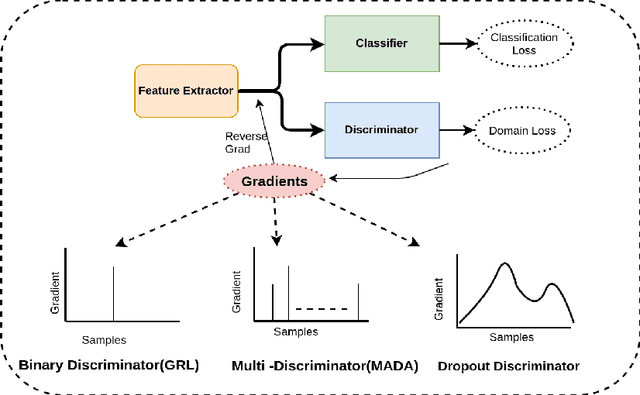
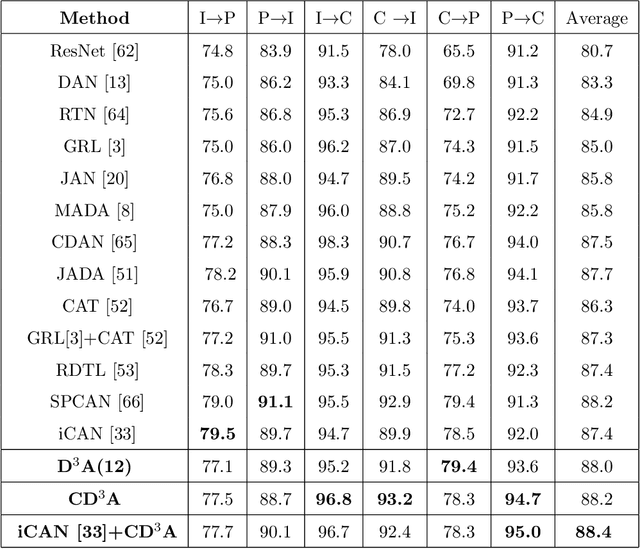
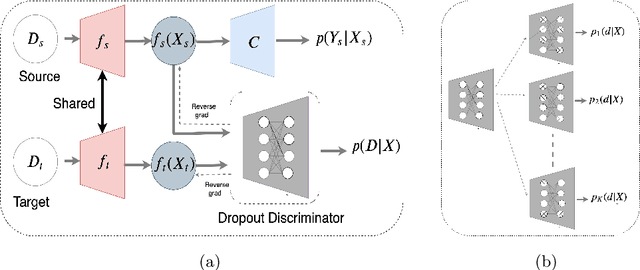
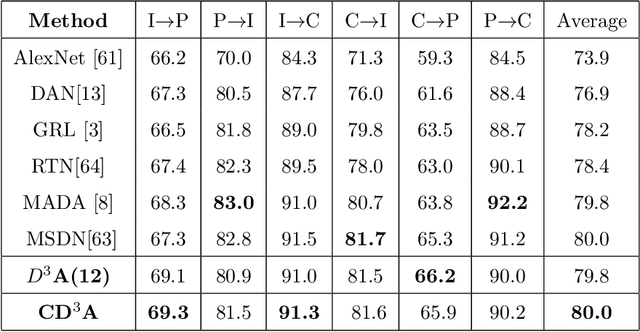
Adaptation of a classifier to new domains is one of the challenging problems in machine learning. This has been addressed using many deep and non-deep learning based methods. Among the methodologies used, that of adversarial learning is widely applied to solve many deep learning problems along with domain adaptation. These methods are based on a discriminator that ensures source and target distributions are close. However, here we suggest that rather than using a point estimate obtaining by a single discriminator, it would be useful if a distribution based on ensembles of discriminators could be used to bridge this gap. This could be achieved using multiple classifiers or using traditional ensemble methods. In contrast, we suggest that a Monte Carlo dropout based ensemble discriminator could suffice to obtain the distribution based discriminator. Specifically, we propose a curriculum based dropout discriminator that gradually increases the variance of the sample based distribution and the corresponding reverse gradients are used to align the source and target feature representations. An ensemble of discriminators helps the model to learn the data distribution efficiently. It also provides a better gradient estimates to train the feature extractor. The detailed results and thorough ablation analysis show that our model outperforms state-of-the-art results.
Domain Impression: A Source Data Free Domain Adaptation Method
Feb 17, 2021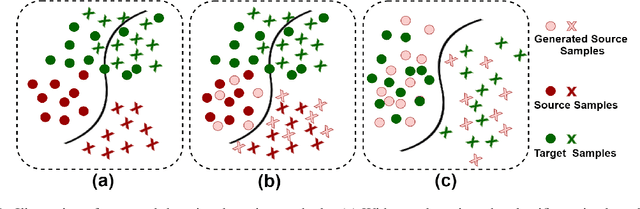
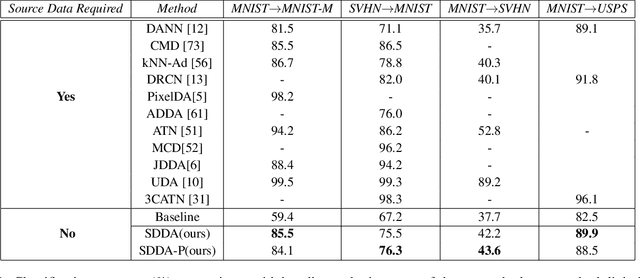
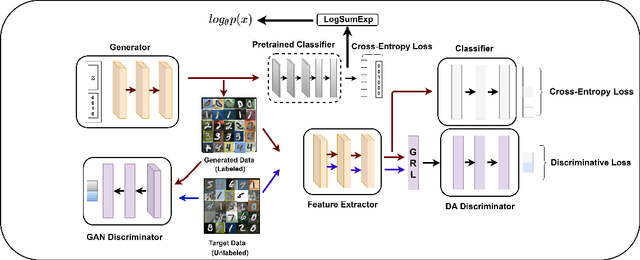
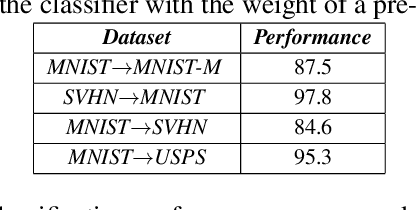
Unsupervised Domain adaptation methods solve the adaptation problem for an unlabeled target set, assuming that the source dataset is available with all labels. However, the availability of actual source samples is not always possible in practical cases. It could be due to memory constraints, privacy concerns, and challenges in sharing data. This practical scenario creates a bottleneck in the domain adaptation problem. This paper addresses this challenging scenario by proposing a domain adaptation technique that does not need any source data. Instead of the source data, we are only provided with a classifier that is trained on the source data. Our proposed approach is based on a generative framework, where the trained classifier is used for generating samples from the source classes. We learn the joint distribution of data by using the energy-based modeling of the trained classifier. At the same time, a new classifier is also adapted for the target domain. We perform various ablation analysis under different experimental setups and demonstrate that the proposed approach achieves better results than the baseline models in this extremely novel scenario.
Curriculum based Dropout Discriminator for Domain Adaptation
Jul 24, 2019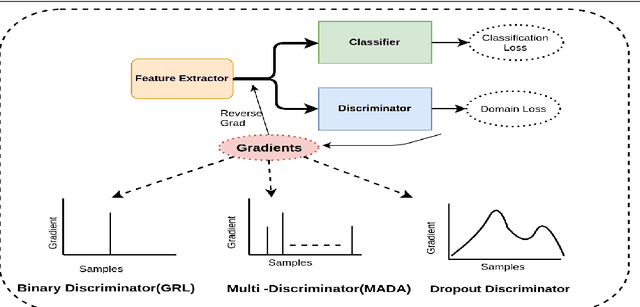
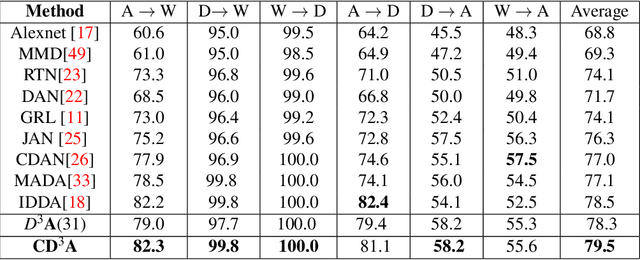
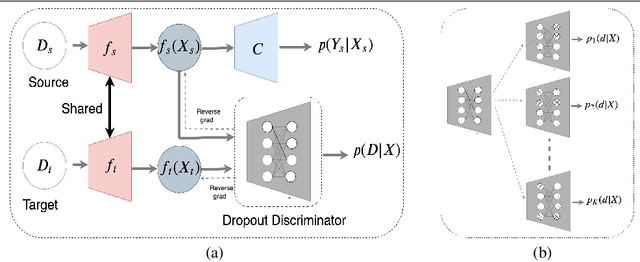
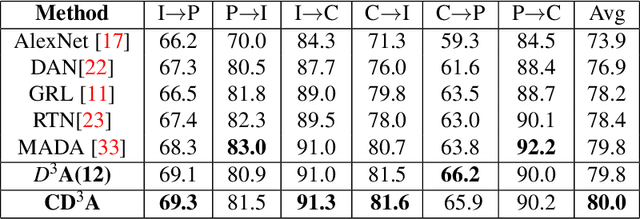
Domain adaptation is essential to enable wide usage of deep learning based networks trained using large labeled datasets. Adversarial learning based techniques have shown their utility towards solving this problem using a discriminator that ensures source and target distributions are close. However, here we suggest that rather than using a point estimate, it would be useful if a distribution based discriminator could be used to bridge this gap. This could be achieved using multiple classifiers or using traditional ensemble methods. In contrast, we suggest that a Monte Carlo dropout based ensemble discriminator could suffice to obtain the distribution based discriminator. Specifically, we propose a curriculum based dropout discriminator that gradually increases the variance of the sample based distribution and the corresponding reverse gradients are used to align the source and target feature representations. The detailed results and thorough ablation analysis show that our model outperforms state-of-the-art results.