 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Learning to Generate Audio-Video Jointly
Apr 01, 2021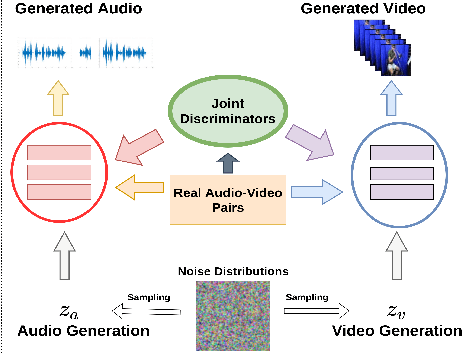

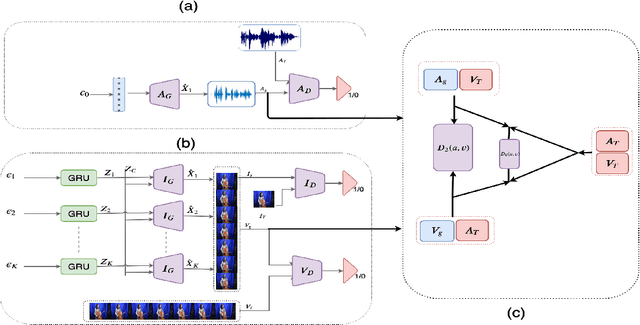

There have been a number of techniques that have demonstrated the generation of multimedia data for one modality at a time using GANs, such as the ability to generate images, videos, and audio. However, so far, the task of multi-modal generation of data, specifically for audio and videos both, has not been sufficiently well-explored. Towards this, we propose a method that demonstrates that we are able to generate naturalistic samples of video and audio data by the joint correlated generation of audio and video modalities. The proposed method uses multiple discriminators to ensure that the audio, video, and the joint output are also indistinguishable from real-world samples. We present a dataset for this task and show that we are able to generate realistic samples. This method is validated using various standard metrics such as Inception Score, Frechet Inception Distance (FID) and through human evaluation.
Curriculum based Dropout Discriminator for Domain Adaptation
Jul 24, 2019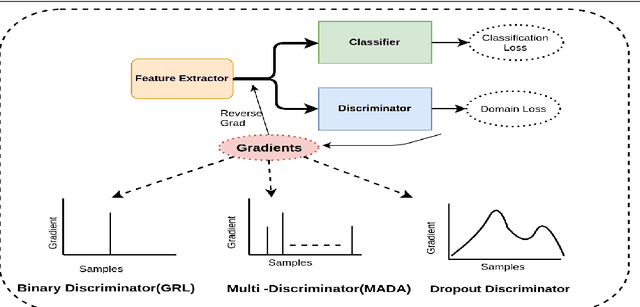
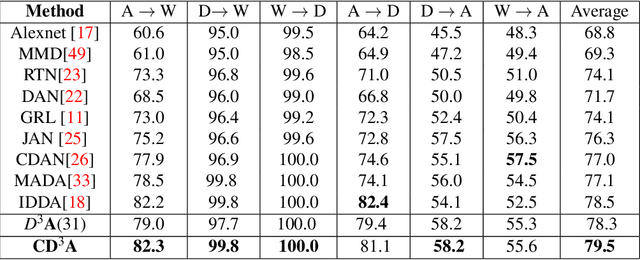
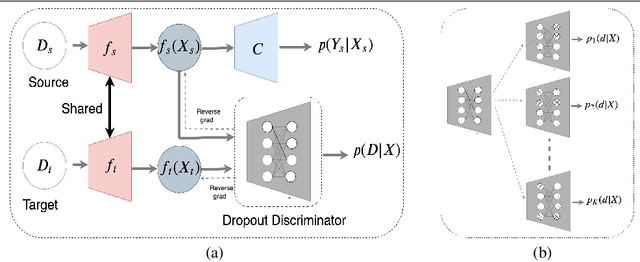
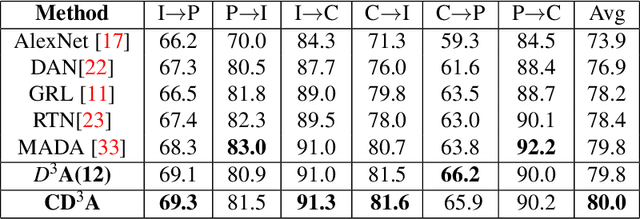
Domain adaptation is essential to enable wide usage of deep learning based networks trained using large labeled datasets. Adversarial learning based techniques have shown their utility towards solving this problem using a discriminator that ensures source and target distributions are close. However, here we suggest that rather than using a point estimate, it would be useful if a distribution based discriminator could be used to bridge this gap. This could be achieved using multiple classifiers or using traditional ensemble methods. In contrast, we suggest that a Monte Carlo dropout based ensemble discriminator could suffice to obtain the distribution based discriminator. Specifically, we propose a curriculum based dropout discriminator that gradually increases the variance of the sample based distribution and the corresponding reverse gradients are used to align the source and target feature representations. The detailed results and thorough ablation analysis show that our model outperforms state-of-the-art results.