 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Look Around: Enhancing Teleoperation and Learning with a Human-like Actuated Neck
Nov 01, 2024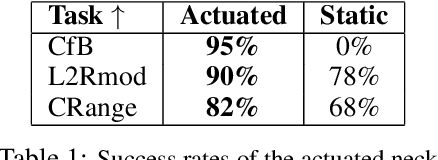



We introduce a teleoperation system that integrates a 5 DOF actuated neck, designed to replicate natural human head movements and perception. By enabling behaviors like peeking or tilting, the system provides operators with a more intuitive and comprehensive view of the environment, improving task performance, reducing cognitive load, and facilitating complex whole-body manipulation. We demonstrate the benefits of natural perception across seven challenging teleoperation tasks, showing how the actuated neck enhances the scope and efficiency of remote operation. Furthermore, we investigate its role in training autonomous policies through imitation learning. In three distinct tasks, the actuated neck supports better spatial awareness, reduces distribution shift, and enables adaptive task-specific adjustments compared to a static wide-angle camera.
SceneComplete: Open-World 3D Scene Completion in Complex Real World Environments for Robot Manipulation
Oct 31, 2024



Careful robot manipulation in every-day cluttered environments requires an accurate understanding of the 3D scene, in order to grasp and place objects stably and reliably and to avoid mistakenly colliding with other objects. In general, we must construct such a 3D interpretation of a complex scene based on limited input, such as a single RGB-D image. We describe SceneComplete, a system for constructing a complete, segmented, 3D model of a scene from a single view. It provides a novel pipeline for composing general-purpose pretrained perception modules (vision-language, segmentation, image-inpainting, image-to-3D, and pose-estimation) to obtain high-accuracy results. We demonstrate its accuracy and effectiveness with respect to ground-truth models in a large benchmark dataset and show that its accurate whole-object reconstruction enables robust grasp proposal generation, including for a dexterous hand.
Constrained 6-DoF Grasp Generation on Complex Shapes for Improved Dual-Arm Manipulation
Apr 06, 2024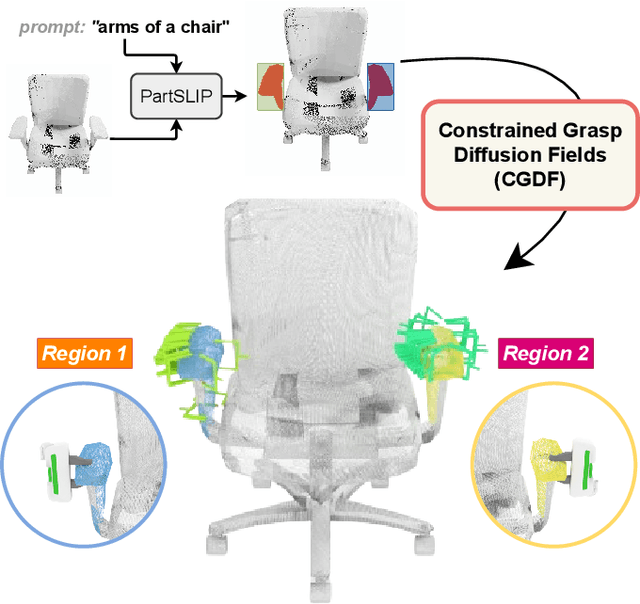
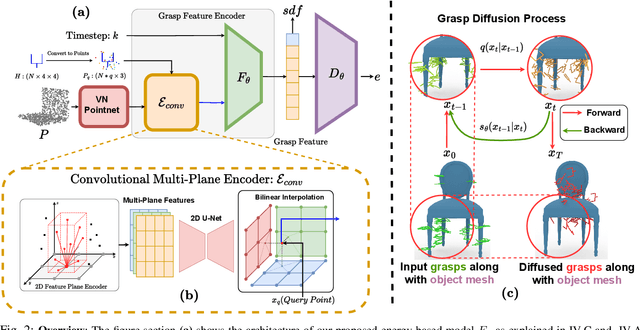
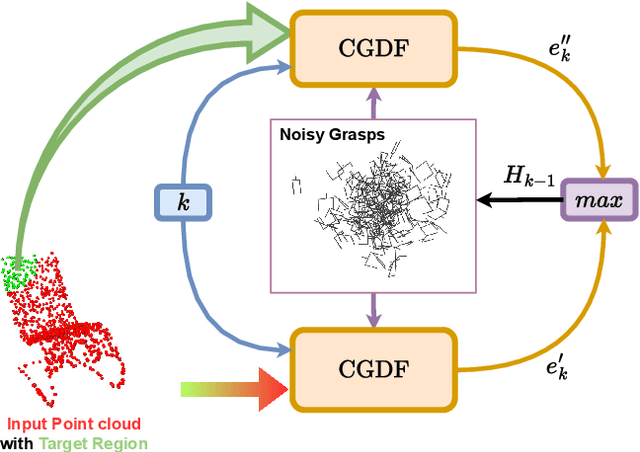
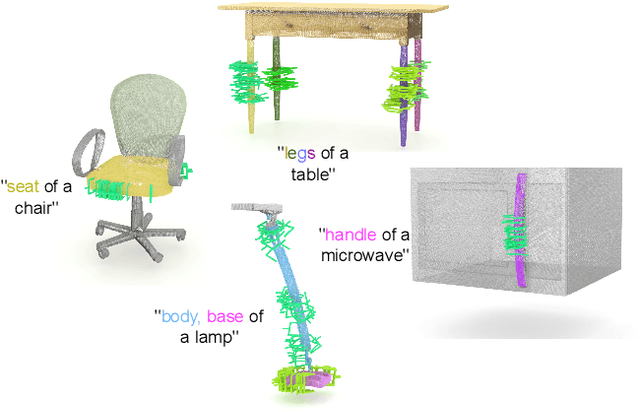
Efficiently generating grasp poses tailored to specific regions of an object is vital for various robotic manipulation tasks, especially in a dual-arm setup. This scenario presents a significant challenge due to the complex geometries involved, requiring a deep understanding of the local geometry to generate grasps efficiently on the specified constrained regions. Existing methods only explore settings involving table-top/small objects and require augmented datasets to train, limiting their performance on complex objects. We propose CGDF: Constrained Grasp Diffusion Fields, a diffusion-based grasp generative model that generalizes to objects with arbitrary geometries, as well as generates dense grasps on the target regions. CGDF uses a part-guided diffusion approach that enables it to get high sample efficiency in constrained grasping without explicitly training on massive constraint-augmented datasets. We provide qualitative and quantitative comparisons using analytical metrics and in simulation, in both unconstrained and constrained settings to show that our method can generalize to generate stable grasps on complex objects, especially useful for dual-arm manipulation settings, while existing methods struggle to do so.
ConceptGraphs: Open-Vocabulary 3D Scene Graphs for Perception and Planning
Sep 28, 2023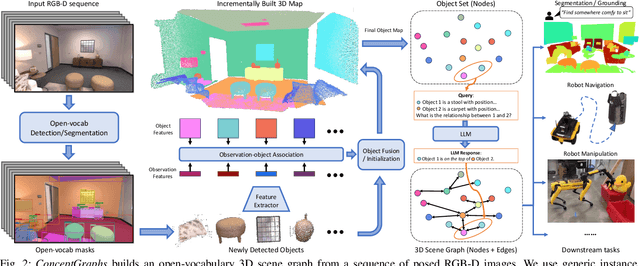
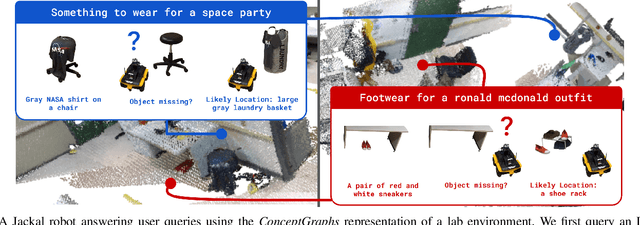
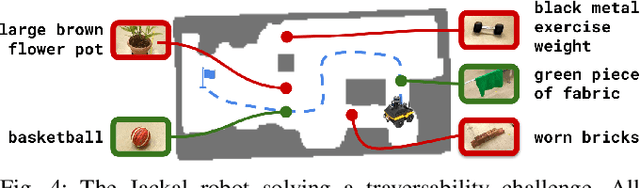
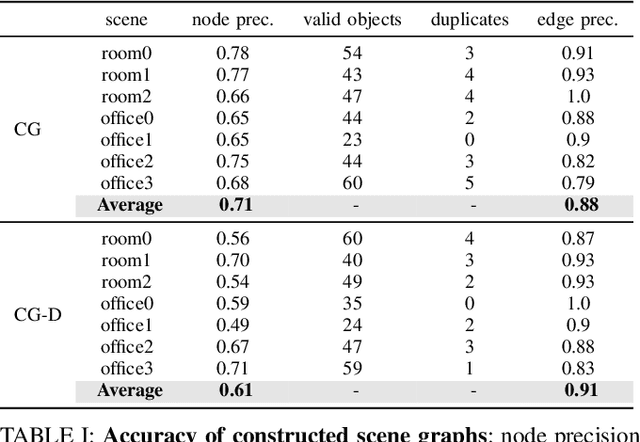
For robots to perform a wide variety of tasks, they require a 3D representation of the world that is semantically rich, yet compact and efficient for task-driven perception and planning. Recent approaches have attempted to leverage features from large vision-language models to encode semantics in 3D representations. However, these approaches tend to produce maps with per-point feature vectors, which do not scale well in larger environments, nor do they contain semantic spatial relationships between entities in the environment, which are useful for downstream planning. In this work, we propose ConceptGraphs, an open-vocabulary graph-structured representation for 3D scenes. ConceptGraphs is built by leveraging 2D foundation models and fusing their output to 3D by multi-view association. The resulting representations generalize to novel semantic classes, without the need to collect large 3D datasets or finetune models. We demonstrate the utility of this representation through a number of downstream planning tasks that are specified through abstract (language) prompts and require complex reasoning over spatial and semantic concepts. (Project page: https://concept-graphs.github.io/ Explainer video: https://youtu.be/mRhNkQwRYnc )
EDMP: Ensemble-of-costs-guided Diffusion for Motion Planning
Sep 20, 2023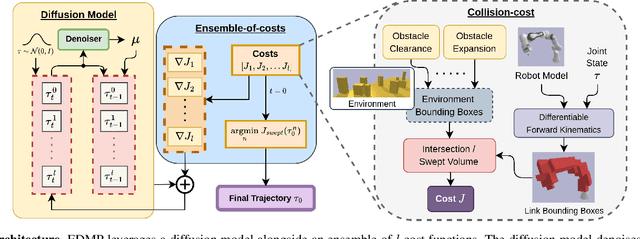
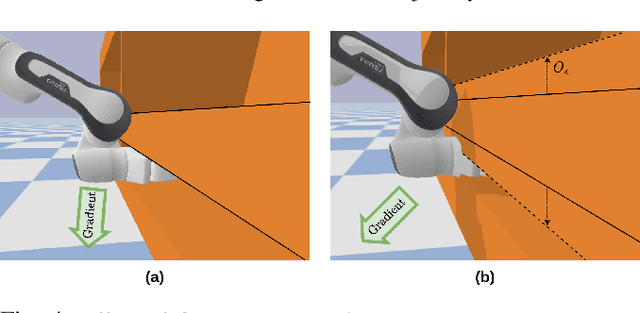
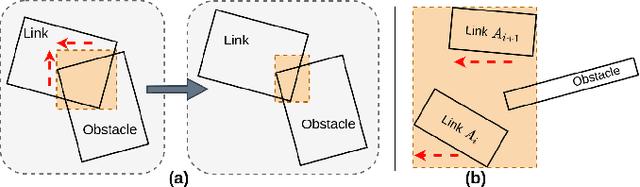
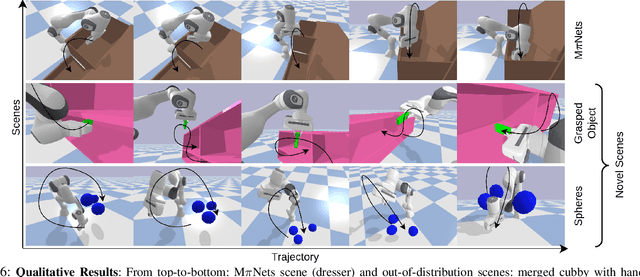
Classical motion planning for robotic manipulation includes a set of general algorithms that aim to minimize a scene-specific cost of executing a given plan. This approach offers remarkable adaptability, as they can be directly used off-the-shelf for any new scene without needing specific training datasets. However, without a prior understanding of what diverse valid trajectories are and without specially designed cost functions for a given scene, the overall solutions tend to have low success rates. While deep-learning-based algorithms tremendously improve success rates, they are much harder to adopt without specialized training datasets. We propose EDMP, an Ensemble-of-costs-guided Diffusion for Motion Planning that aims to combine the strengths of classical and deep-learning-based motion planning. Our diffusion-based network is trained on a set of diverse kinematically valid trajectories. Like classical planning, for any new scene at the time of inference, we compute scene-specific costs such as "collision cost" and guide the diffusion to generate valid trajectories that satisfy the scene-specific constraints. Further, instead of a single cost function that may be insufficient in capturing diversity across scenes, we use an ensemble of costs to guide the diffusion process, significantly improving the success rate compared to classical planners. EDMP performs comparably with SOTA deep-learning-based methods while retaining the generalization capabilities primarily associated with classical planners.
HyP-NeRF: Learning Improved NeRF Priors using a HyperNetwork
Jun 09, 2023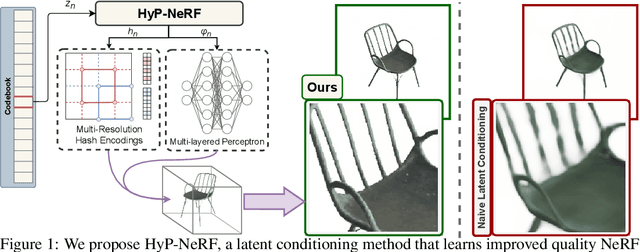

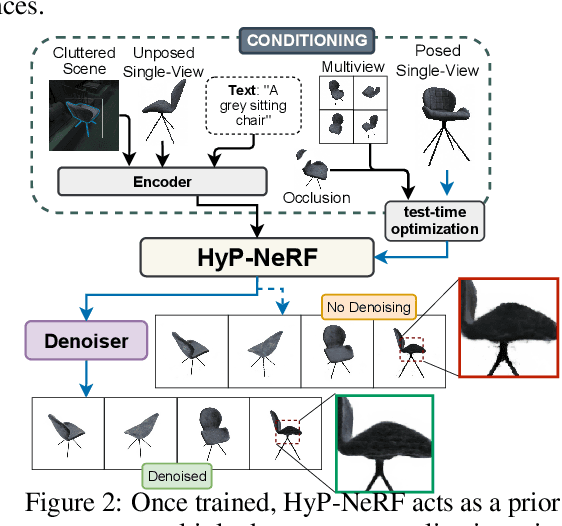

Neural Radiance Fields (NeRF) have become an increasingly popular representation to capture high-quality appearance and shape of scenes and objects. However, learning generalizable NeRF priors over categories of scenes or objects has been challenging due to the high dimensionality of network weight space. To address the limitations of existing work on generalization, multi-view consistency and to improve quality, we propose HyP-NeRF, a latent conditioning method for learning generalizable category-level NeRF priors using hypernetworks. Rather than using hypernetworks to estimate only the weights of a NeRF, we estimate both the weights and the multi-resolution hash encodings resulting in significant quality gains. To improve quality even further, we incorporate a denoise and finetune strategy that denoises images rendered from NeRFs estimated by the hypernetwork and finetunes it while retaining multiview consistency. These improvements enable us to use HyP-NeRF as a generalizable prior for multiple downstream tasks including NeRF reconstruction from single-view or cluttered scenes and text-to-NeRF. We provide qualitative comparisons and evaluate HyP-NeRF on three tasks: generalization, compression, and retrieval, demonstrating our state-of-the-art results.
SCARP: 3D Shape Completion in ARbitrary Poses for Improved Grasping
Jan 17, 2023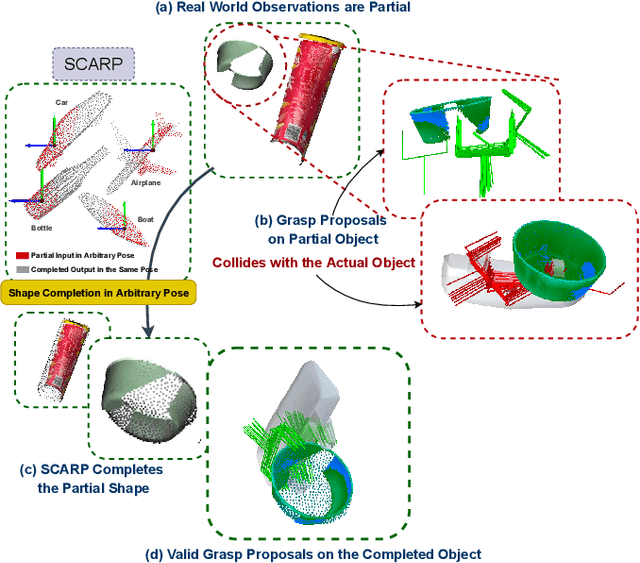
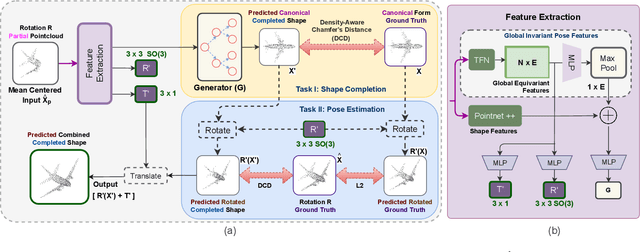


Recovering full 3D shapes from partial observations is a challenging task that has been extensively addressed in the computer vision community. Many deep learning methods tackle this problem by training 3D shape generation networks to learn a prior over the full 3D shapes. In this training regime, the methods expect the inputs to be in a fixed canonical form, without which they fail to learn a valid prior over the 3D shapes. We propose SCARP, a model that performs Shape Completion in ARbitrary Poses. Given a partial pointcloud of an object, SCARP learns a disentangled feature representation of pose and shape by relying on rotationally equivariant pose features and geometric shape features trained using a multi-tasking objective. Unlike existing methods that depend on an external canonicalization, SCARP performs canonicalization, pose estimation, and shape completion in a single network, improving the performance by 45% over the existing baselines. In this work, we use SCARP for improving grasp proposals on tabletop objects. By completing partial tabletop objects directly in their observed poses, SCARP enables a SOTA grasp proposal network improve their proposals by 71.2% on partial shapes. Project page: https://bipashasen.github.io/scarp
INR-V: A Continuous Representation Space for Video-based Generative Tasks
Oct 29, 2022

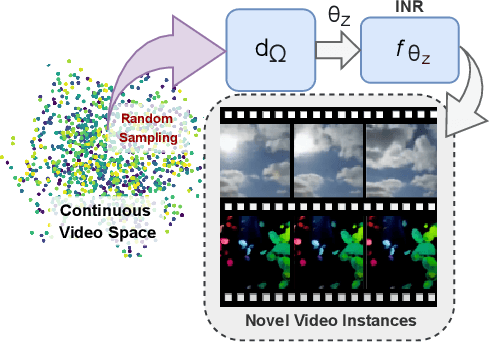
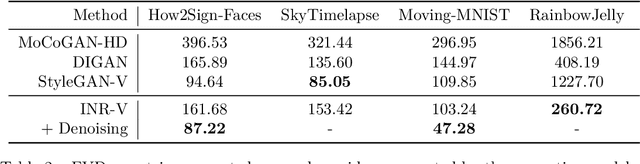
Generating videos is a complex task that is accomplished by generating a set of temporally coherent images frame-by-frame. This limits the expressivity of videos to only image-based operations on the individual video frames needing network designs to obtain temporally coherent trajectories in the underlying image space. We propose INR-V, a video representation network that learns a continuous space for video-based generative tasks. INR-V parameterizes videos using implicit neural representations (INRs), a multi-layered perceptron that predicts an RGB value for each input pixel location of the video. The INR is predicted using a meta-network which is a hypernetwork trained on neural representations of multiple video instances. Later, the meta-network can be sampled to generate diverse novel videos enabling many downstream video-based generative tasks. Interestingly, we find that conditional regularization and progressive weight initialization play a crucial role in obtaining INR-V. The representation space learned by INR-V is more expressive than an image space showcasing many interesting properties not possible with the existing works. For instance, INR-V can smoothly interpolate intermediate videos between known video instances (such as intermediate identities, expressions, and poses in face videos). It can also in-paint missing portions in videos to recover temporally coherent full videos. In this work, we evaluate the space learned by INR-V on diverse generative tasks such as video interpolation, novel video generation, video inversion, and video inpainting against the existing baselines. INR-V significantly outperforms the baselines on several of these demonstrated tasks, clearly showcasing the potential of the proposed representation space.
Towards MOOCs for Lip Reading: Using Synthetic Talking Heads to Train Humans in Lipreading at Scale
Aug 21, 2022
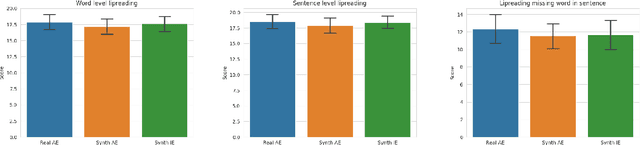
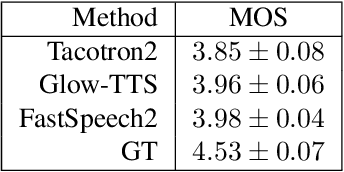

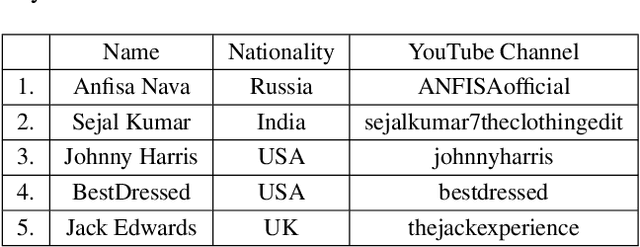
Many people with some form of hearing loss consider lipreading as their primary mode of day-to-day communication. However, finding resources to learn or improve one's lipreading skills can be challenging. This is further exacerbated in COVID$19$ pandemic due to restrictions on direct interactions with peers and speech therapists. Today, online MOOCs platforms like Coursera and Udemy have become the most effective form of training for many kinds of skill development. However, online lipreading resources are scarce as creating such resources is an extensive process needing months of manual effort to record hired actors. Because of the manual pipeline, such platforms are also limited in the vocabulary, supported languages, accents, and speakers, and have a high usage cost. In this work, we investigate the possibility of replacing real human talking videos with synthetically generated videos. Synthetic data can be used to easily incorporate larger vocabularies, variations in accent, and even local languages, and many speakers. We propose an end-to-end automated pipeline to develop such a platform using state-of-the-art talking heading video generator networks, text-to-speech models, and computer vision techniques. We then perform an extensive human evaluation using carefully thought out lipreading exercises to validate the quality of our designed platform against the existing lipreading platforms. Our studies concretely point towards the potential of our approach for the development of a large-scale lipreading MOOCs platform that can impact millions of people with hearing loss.
FaceOff: A Video-to-Video Face Swapping System
Aug 21, 2022

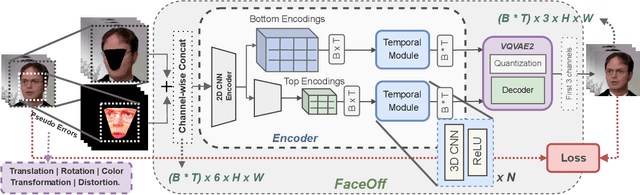
Doubles play an indispensable role in the movie industry. They take the place of the actors in dangerous stunt scenes or in scenes where the same actor plays multiple characters. The double's face is later replaced with the actor's face and expressions manually using expensive CGI technology, costing millions of dollars and taking months to complete. An automated, inexpensive, and fast way can be to use face-swapping techniques that aim to swap an identity from a source face video (or an image) to a target face video. However, such methods can not preserve the source expressions of the actor important for the scene's context. % essential for the scene. % that are essential in cinemas. To tackle this challenge, we introduce video-to-video (V2V) face-swapping, a novel task of face-swapping that can preserve (1) the identity and expressions of the source (actor) face video and (2) the background and pose of the target (double) video. We propose FaceOff, a V2V face-swapping system that operates by learning a robust blending operation to merge two face videos following the constraints above. It first reduces the videos to a quantized latent space and then blends them in the reduced space. FaceOff is trained in a self-supervised manner and robustly tackles the non-trivial challenges of V2V face-swapping. As shown in the experimental section, FaceOff significantly outperforms alternate approaches qualitatively and quantitatively.