 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiPToP: A Modular Open-Vocabulary Planning System for Robotic Manipulation
Mar 10, 2026We present TiPToP, an extensible modular system that combines pretrained vision foundation models with an existing Task and Motion Planner (TAMP) to solve multi-step manipulation tasks directly from input RGB images and natural-language instructions. Our system aims to be simple and easy-to-use: it can be installed and run on a standard DROID setup in under one hour and adapted to new embodiments with minimal effort. We evaluate TiPToP -- which requires zero robot data -- over 28 tabletop manipulation tasks in simulation and the real world and find it matches or outperforms $π_{0.5}\text{-DROID}$, a vision-language-action (VLA) model fine-tuned on 350 hours of embodiment-specific demonstrations. TiPToP's modular architecture enables us to analyze the system's failure modes at the component level. We analyze results from an evaluation of 173 trials and identify directions for improvement. We release TiPToP open-source to further research on modular manipulation systems and tighter integration between learning and planning. Project website and code: https://tiptop-robot.github.io
Rational Inverse Reasoning
Aug 12, 2025



Humans can observe a single, imperfect demonstration and immediately generalize to very different problem settings. Robots, in contrast, often require hundreds of examples and still struggle to generalize beyond the training conditions. We argue that this limitation arises from the inability to recover the latent explanations that underpin intelligent behavior, and that these explanations can take the form of structured programs consisting of high-level goals, sub-task decomposition, and execution constraints. In this work, we introduce Rational Inverse Reasoning (RIR), a framework for inferring these latent programs through a hierarchical generative model of behavior. RIR frames few-shot imitation as Bayesian program induction: a vision-language model iteratively proposes structured symbolic task hypotheses, while a planner-in-the-loop inference scheme scores each by the likelihood of the observed demonstration under that hypothesis. This loop yields a posterior over concise, executable programs. We evaluate RIR on a suite of continuous manipulation tasks designed to test one-shot and few-shot generalization across variations in object pose, count, geometry, and layout. With as little as one demonstration, RIR infers the intended task structure and generalizes to novel settings, outperforming state-of-the-art vision-language model baselines.
Streaming Flow Policy: Simplifying diffusion$/$flow-matching policies by treating action trajectories as flow trajectories
May 28, 2025Recent advances in diffusion$/$flow-matching policies have enabled imitation learning of complex, multi-modal action trajectories. However, they are computationally expensive because they sample a trajectory of trajectories: a diffusion$/$flow trajectory of action trajectories. They discard intermediate action trajectories, and must wait for the sampling process to complete before any actions can be executed on the robot. We simplify diffusion$/$flow policies by treating action trajectories as flow trajectories. Instead of starting from pure noise, our algorithm samples from a narrow Gaussian around the last action. Then, it incrementally integrates a velocity field learned via flow matching to produce a sequence of actions that constitute a single trajectory. This enables actions to be streamed to the robot on-the-fly during the flow sampling process, and is well-suited for receding horizon policy execution. Despite streaming, our method retains the ability to model multi-modal behavior. We train flows that stabilize around demonstration trajectories to reduce distribution shift and improve imitation learning performance. Streaming flow policy outperforms prior methods while enabling faster policy execution and tighter sensorimotor loops for learning-based robot control. Project website: https://streaming-flow-policy.github.io/
LLM-Guided Probabilistic Program Induction for POMDP Model Estimation
May 04, 2025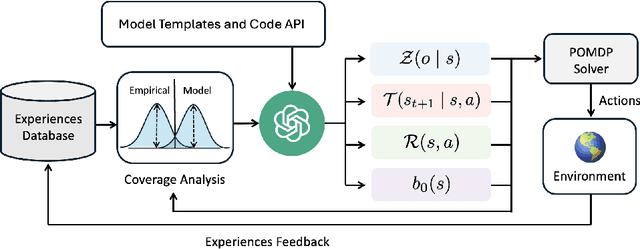



Partially Observable Markov Decision Processes (POMDPs) model decision making under uncertainty. While there are many approaches to approximately solving POMDPs, we aim to address the problem of learning such models. In particular, we are interested in a subclass of POMDPs wherein the components of the model, including the observation function, reward function, transition function, and initial state distribution function, can be modeled as low-complexity probabilistic graphical models in the form of a short probabilistic program. Our strategy to learn these programs uses an LLM as a prior, generating candidate probabilistic programs that are then tested against the empirical distribution and adjusted through feedback. We experiment on a number of classical toy POMDP problems, simulated MiniGrid domains, and two real mobile-base robotics search domains involving partial observability. Our results show that using an LLM to guide in the construction of a low-complexity POMDP model can be more effective than tabular POMDP learning, behavior cloning, or direct LLM planning.
Predicate Invention from Pixels via Pretrained Vision-Language Models
Dec 31, 2024



Our aim is to learn to solve long-horizon decision-making problems in highly-variable, combinatorially-complex robotics domains given raw sensor input in the form of images. Previous work has shown that one way to achieve this aim is to learn a structured abstract transition model in the form of symbolic predicates and operators, and then plan within this model to solve novel tasks at test time. However, these learned models do not ground directly into pixels from just a handful of demonstrations. In this work, we propose to invent predicates that operate directly over input images by leveraging the capabilities of pretrained vision-language models (VLMs). Our key idea is that, given a set of demonstrations, a VLM can be used to propose a set of predicates that are potentially relevant for decision-making and then to determine the truth values of these predicates in both the given demonstrations and new image inputs. We build upon an existing framework for predicate invention, which generates feature-based predicates operating on object-centric states, to also generate visual predicates that operate on images. Experimentally, we show that our approach -- pix2pred -- is able to invent semantically meaningful predicates that enable generalization to novel, complex, and long-horizon tasks across two simulated robotic environments.
Functional Risk Minimization
Dec 30, 2024The field of Machine Learning has changed significantly since the 1970s. However, its most basic principle, Empirical Risk Minimization (ERM), remains unchanged. We propose Functional Risk Minimization~(FRM), a general framework where losses compare functions rather than outputs. This results in better performance in supervised, unsupervised, and RL experiments. In the FRM paradigm, for each data point $(x_i,y_i)$ there is function $f_{\theta_i}$ that fits it: $y_i = f_{\theta_i}(x_i)$. This allows FRM to subsume ERM for many common loss functions and to capture more realistic noise processes. We also show that FRM provides an avenue towards understanding generalization in the modern over-parameterized regime, as its objective can be framed as finding the simplest model that fits the training data.
One-Shot Manipulation Strategy Learning by Making Contact Analogies
Nov 14, 2024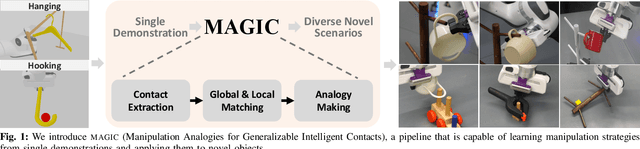

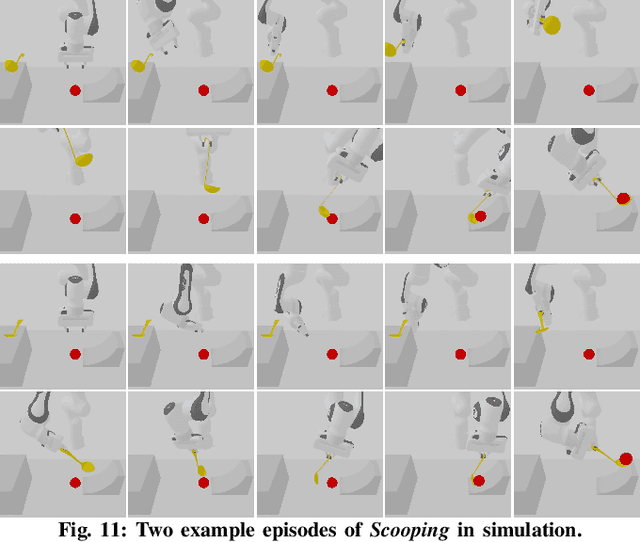
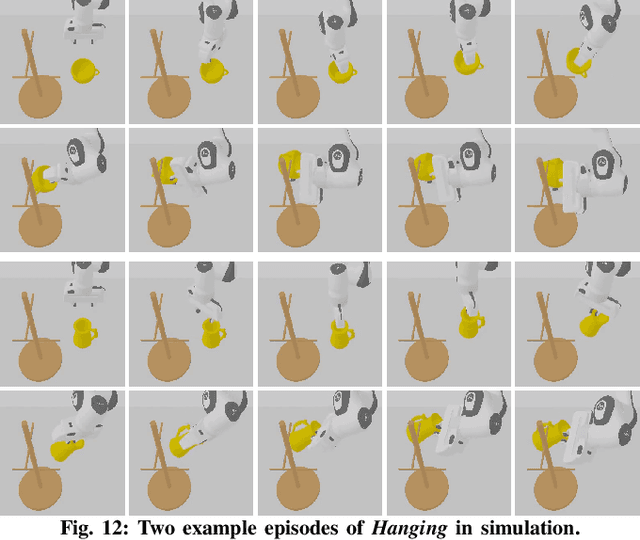
We present a novel approach, MAGIC (manipulation analogies for generalizable intelligent contacts), for one-shot learning of manipulation strategies with fast and extensive generalization to novel objects. By leveraging a reference action trajectory, MAGIC effectively identifies similar contact points and sequences of actions on novel objects to replicate a demonstrated strategy, such as using different hooks to retrieve distant objects of different shapes and sizes. Our method is based on a two-stage contact-point matching process that combines global shape matching using pretrained neural features with local curvature analysis to ensure precise and physically plausible contact points. We experiment with three tasks including scooping, hanging, and hooking objects. MAGIC demonstrates superior performance over existing methods, achieving significant improvements in runtime speed and generalization to different object categories. Website: https://magic-2024.github.io/ .
SceneComplete: Open-World 3D Scene Completion in Complex Real World Environments for Robot Manipulation
Oct 31, 2024



Careful robot manipulation in every-day cluttered environments requires an accurate understanding of the 3D scene, in order to grasp and place objects stably and reliably and to avoid mistakenly colliding with other objects. In general, we must construct such a 3D interpretation of a complex scene based on limited input, such as a single RGB-D image. We describe SceneComplete, a system for constructing a complete, segmented, 3D model of a scene from a single view. It provides a novel pipeline for composing general-purpose pretrained perception modules (vision-language, segmentation, image-inpainting, image-to-3D, and pose-estimation) to obtain high-accuracy results. We demonstrate its accuracy and effectiveness with respect to ground-truth models in a large benchmark dataset and show that its accurate whole-object reconstruction enables robust grasp proposal generation, including for a dexterous hand.
Keypoint Abstraction using Large Models for Object-Relative Imitation Learning
Oct 30, 2024



Generalization to novel object configurations and instances across diverse tasks and environments is a critical challenge in robotics. Keypoint-based representations have been proven effective as a succinct representation for capturing essential object features, and for establishing a reference frame in action prediction, enabling data-efficient learning of robot skills. However, their manual design nature and reliance on additional human labels limit their scalability. In this paper, we propose KALM, a framework that leverages large pre-trained vision-language models (LMs) to automatically generate task-relevant and cross-instance consistent keypoints. KALM distills robust and consistent keypoints across views and objects by generating proposals using LMs and verifies them against a small set of robot demonstration data. Based on the generated keypoints, we can train keypoint-conditioned policy models that predict actions in keypoint-centric frames, enabling robots to generalize effectively across varying object poses, camera views, and object instances with similar functional shapes. Our method demonstrates strong performance in the real world, adapting to different tasks and environments from only a handful of demonstrations while requiring no additional labels. Website: https://kalm-il.github.io/
Combining Planning and Diffusion for Mobility with Unknown Dynamics
Oct 09, 2024



Manipulation of large objects over long horizons (such as carts in a warehouse) is an essential skill for deployable robotic systems. Large objects require mobile manipulation which involves simultaneous manipulation, navigation, and movement with the object in tow. In many real-world situations, object dynamics are incredibly complex, such as the interaction of an office chair (with a rotating base and five caster wheels) and the ground. We present a hierarchical algorithm for long-horizon robot manipulation problems in which the dynamics are partially unknown. We observe that diffusion-based behavior cloning is highly effective for short-horizon problems with unknown dynamics, so we decompose the problem into an abstract high-level, obstacle-aware motion-planning problem that produces a waypoint sequence. We use a short-horizon, relative-motion diffusion policy to achieve the waypoints in sequence. We train mobile manipulation policies on a Spot robot that has to push and pull an office chair. Our hierarchical manipulation policy performs consistently better, especially when the horizon increases, compared to a diffusion policy trained on long-horizon demonstrations or motion planning assuming a rigidly-attached object (success rate of 8 (versus 0 and 5 respectively) out of 10 runs). Importantly, our learned policy generalizes to new layouts, grasps, chairs, and flooring that induces more friction, without any further training, showing promise for other complex mobile manipulation problems. Project Page: https://yravan.github.io/plannerorderedpolicy/