 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforceGen: Hybrid Skill Policies with Automated Data Generation and Reinforcement Learning
Dec 18, 2025Long-horizon manipulation has been a long-standing challenge in the robotics community. We propose ReinforceGen, a system that combines task decomposition, data generation, imitation learning, and motion planning to form an initial solution, and improves each component through reinforcement-learning-based fine-tuning. ReinforceGen first segments the task into multiple localized skills, which are connected through motion planning. The skills and motion planning targets are trained with imitation learning on a dataset generated from 10 human demonstrations, and then fine-tuned through online adaptation and reinforcement learning. When benchmarked on the Robosuite dataset, ReinforceGen reaches 80% success rate on all tasks with visuomotor controls in the highest reset range setting. Additional ablation studies show that our fine-tuning approaches contributes to an 89% average performance increase. More results and videos available in https://reinforcegen.github.io/
ScheduleStream: Temporal Planning with Samplers for GPU-Accelerated Multi-Arm Task and Motion Planning & Scheduling
Nov 06, 2025



Bimanual and humanoid robots are appealing because of their human-like ability to leverage multiple arms to efficiently complete tasks. However, controlling multiple arms at once is computationally challenging due to the growth in the hybrid discrete-continuous action space. Task and Motion Planning (TAMP) algorithms can efficiently plan in hybrid spaces but generally produce plans, where only one arm is moving at a time, rather than schedules that allow for parallel arm motion. In order to extend TAMP to produce schedules, we present ScheduleStream, the first general-purpose framework for planning & scheduling with sampling operations. ScheduleStream models temporal dynamics using hybrid durative actions, which can be started asynchronously and persist for a duration that's a function of their parameters. We propose domain-independent algorithms that solve ScheduleStream problems without any application-specific mechanisms. We apply ScheduleStream to Task and Motion Planning & Scheduling (TAMPAS), where we use GPU acceleration within samplers to expedite planning. We compare ScheduleStream algorithms to several ablations in simulation and find that they produce more efficient solutions. We demonstrate ScheduleStream on several real-world bimanual robot tasks at https://schedulestream.github.io.
Differentiable GPU-Parallelized Task and Motion Planning
Nov 18, 2024


We present a differentiable optimization-based framework for Task and Motion Planning (TAMP) that is massively parallelizable on GPUs, enabling thousands of sampled seeds to be optimized simultaneously. Existing sampling-based approaches inherently disconnect the parameters by generating samples for each independently and combining them through composition and rejection, while optimization-based methods struggle with highly non-convex constraints and local optima. Our method treats TAMP constraint satisfaction as optimizing a batch of particles, each representing an assignment to a plan skeleton's continuous parameters. We represent the plan skeleton's constraints using differentiable cost functions, enabling us to compute the gradient of each particle and update it toward satisfying solutions. Our use of GPU parallelism better covers the parameter space through scale, increasing the likelihood of finding the global optima by exploring multiple basins through global sampling. We demonstrate that our algorithm can effectively solve a highly constrained Tetris packing problem using a Franka arm in simulation and deploy our planner on a real robot arm. Website: https://williamshen-nz.github.io/gpu-tamp
SkillMimicGen: Automated Demonstration Generation for Efficient Skill Learning and Deployment
Oct 24, 2024



Imitation learning from human demonstrations is an effective paradigm for robot manipulation, but acquiring large datasets is costly and resource-intensive, especially for long-horizon tasks. To address this issue, we propose SkillMimicGen (SkillGen), an automated system for generating demonstration datasets from a few human demos. SkillGen segments human demos into manipulation skills, adapts these skills to new contexts, and stitches them together through free-space transit and transfer motion. We also propose a Hybrid Skill Policy (HSP) framework for learning skill initiation, control, and termination components from SkillGen datasets, enabling skills to be sequenced using motion planning at test-time. We demonstrate that SkillGen greatly improves data generation and policy learning performance over a state-of-the-art data generation framework, resulting in the capability to produce data for large scene variations, including clutter, and agents that are on average 24% more successful. We demonstrate the efficacy of SkillGen by generating over 24K demonstrations across 18 task variants in simulation from just 60 human demonstrations, and training proficient, often near-perfect, HSP agents. Finally, we apply SkillGen to 3 real-world manipulation tasks and also demonstrate zero-shot sim-to-real transfer on a long-horizon assembly task. Videos, and more at https://skillgen.github.io.
SPIRE: Synergistic Planning, Imitation, and Reinforcement Learning for Long-Horizon Manipulation
Oct 23, 2024



Robot learning has proven to be a general and effective technique for programming manipulators. Imitation learning is able to teach robots solely from human demonstrations but is bottlenecked by the capabilities of the demonstrations. Reinforcement learning uses exploration to discover better behaviors; however, the space of possible improvements can be too large to start from scratch. And for both techniques, the learning difficulty increases proportional to the length of the manipulation task. Accounting for this, we propose SPIRE, a system that first uses Task and Motion Planning (TAMP) to decompose tasks into smaller learning subproblems and second combines imitation and reinforcement learning to maximize their strengths. We develop novel strategies to train learning agents when deployed in the context of a planning system. We evaluate SPIRE on a suite of long-horizon and contact-rich robot manipulation problems. We find that SPIRE outperforms prior approaches that integrate imitation learning, reinforcement learning, and planning by 35% to 50% in average task performance, is 6 times more data efficient in the number of human demonstrations needed to train proficient agents, and learns to complete tasks nearly twice as efficiently. View https://sites.google.com/view/spire-corl-2024 for more details.
Guiding Long-Horizon Task and Motion Planning with Vision Language Models
Oct 03, 2024



Vision-Language Models (VLM) can generate plausible high-level plans when prompted with a goal, the context, an image of the scene, and any planning constraints. However, there is no guarantee that the predicted actions are geometrically and kinematically feasible for a particular robot embodiment. As a result, many prerequisite steps such as opening drawers to access objects are often omitted in their plans. Robot task and motion planners can generate motion trajectories that respect the geometric feasibility of actions and insert physically necessary actions, but do not scale to everyday problems that require common-sense knowledge and involve large state spaces comprised of many variables. We propose VLM-TAMP, a hierarchical planning algorithm that leverages a VLM to generate goth semantically-meaningful and horizon-reducing intermediate subgoals that guide a task and motion planner. When a subgoal or action cannot be refined, the VLM is queried again for replanning. We evaluate VLM- TAMP on kitchen tasks where a robot must accomplish cooking goals that require performing 30-50 actions in sequence and interacting with up to 21 objects. VLM-TAMP substantially outperforms baselines that rigidly and independently execute VLM-generated action sequences, both in terms of success rates (50 to 100% versus 0%) and average task completion percentage (72 to 100% versus 15 to 45%). See project site https://zt-yang.github.io/vlm-tamp-robot/ for more information.
IntervenGen: Interventional Data Generation for Robust and Data-Efficient Robot Imitation Learning
May 02, 2024Imitation learning is a promising paradigm for training robot control policies, but these policies can suffer from distribution shift, where the conditions at evaluation time differ from those in the training data. A popular approach for increasing policy robustness to distribution shift is interactive imitation learning (i.e., DAgger and variants), where a human operator provides corrective interventions during policy rollouts. However, collecting a sufficient amount of interventions to cover the distribution of policy mistakes can be burdensome for human operators. We propose IntervenGen (I-Gen), a novel data generation system that can autonomously produce a large set of corrective interventions with rich coverage of the state space from a small number of human interventions. We apply I-Gen to 4 simulated environments and 1 physical environment with object pose estimation error and show that it can increase policy robustness by up to 39x with only 10 human interventions. Videos and more results are available at https://sites.google.com/view/intervengen2024.
cuRobo: Parallelized Collision-Free Minimum-Jerk Robot Motion Generation
Nov 03, 2023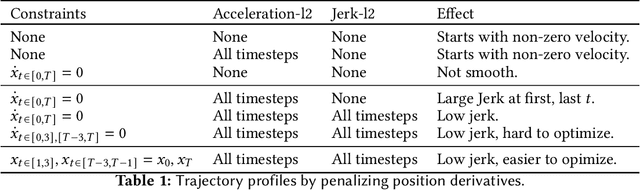
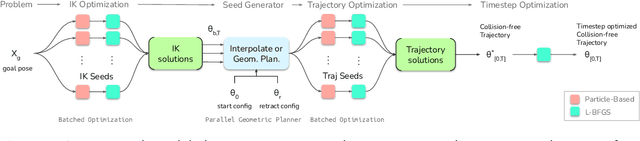
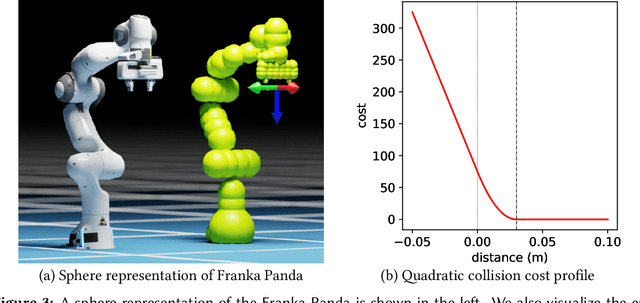
This paper explores the problem of collision-free motion generation for manipulators by formulating it as a global motion optimization problem. We develop a parallel optimization technique to solve this problem and demonstrate its effectiveness on massively parallel GPUs. We show that combining simple optimization techniques with many parallel seeds leads to solving difficult motion generation problems within 50ms on average, 60x faster than state-of-the-art (SOTA) trajectory optimization methods. We achieve SOTA performance by combining L-BFGS step direction estimation with a novel parallel noisy line search scheme and a particle-based optimization solver. To further aid trajectory optimization, we develop a parallel geometric planner that plans within 20ms and also introduce a collision-free IK solver that can solve over 7000 queries/s. We package our contributions into a state of the art GPU accelerated motion generation library, cuRobo and release it to enrich the robotics community. Additional details are available at https://curobo.org
NOD-TAMP: Multi-Step Manipulation Planning with Neural Object Descriptors
Nov 02, 2023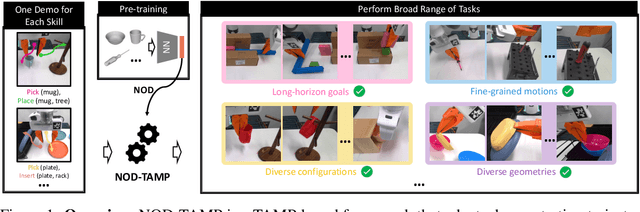
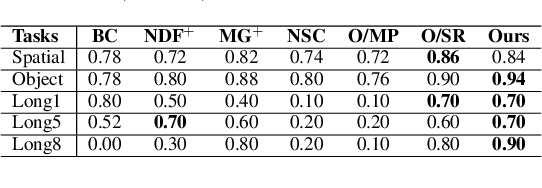
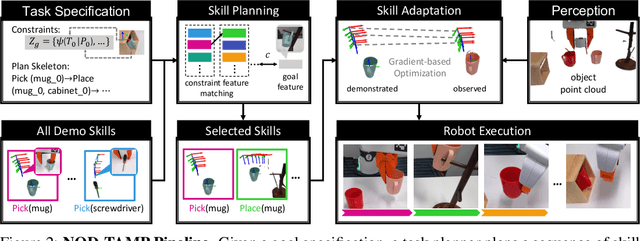
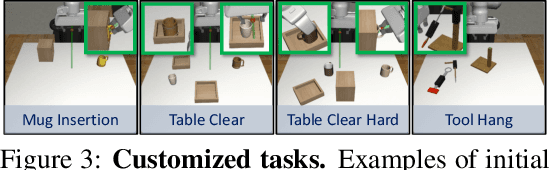
Developing intelligent robots for complex manipulation tasks in household and factory settings remains challenging due to long-horizon tasks, contact-rich manipulation, and the need to generalize across a wide variety of object shapes and scene layouts. While Task and Motion Planning (TAMP) offers a promising solution, its assumptions such as kinodynamic models limit applicability in novel contexts. Neural object descriptors (NODs) have shown promise in object and scene generalization but face limitations in addressing broader tasks. Our proposed TAMP-based framework, NOD-TAMP, extracts short manipulation trajectories from a handful of human demonstrations, adapts these trajectories using NOD features, and composes them to solve broad long-horizon tasks. Validated in a simulation environment, NOD-TAMP effectively tackles varied challenges and outperforms existing methods, establishing a cohesive framework for manipulation planning. For videos and other supplemental material, see the project website: https://sites.google.com/view/nod-tamp/.
Human-in-the-Loop Task and Motion Planning for Imitation Learning
Oct 24, 2023



Imitation learning from human demonstrations can teach robots complex manipulation skills, but is time-consuming and labor intensive. In contrast, Task and Motion Planning (TAMP) systems are automated and excel at solving long-horizon tasks, but they are difficult to apply to contact-rich tasks. In this paper, we present Human-in-the-Loop Task and Motion Planning (HITL-TAMP), a novel system that leverages the benefits of both approaches. The system employs a TAMP-gated control mechanism, which selectively gives and takes control to and from a human teleoperator. This enables the human teleoperator to manage a fleet of robots, maximizing data collection efficiency. The collected human data is then combined with an imitation learning framework to train a TAMP-gated policy, leading to superior performance compared to training on full task demonstrations. We compared HITL-TAMP to a conventional teleoperation system -- users gathered more than 3x the number of demos given the same time budget. Furthermore, proficient agents (75\%+ success) could be trained from just 10 minutes of non-expert teleoperation data. Finally, we collected 2.1K demos with HITL-TAMP across 12 contact-rich, long-horizon tasks and show that the system often produces near-perfect agents. Videos and additional results at https://hitltamp.github.io .