 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiPToP: A Modular Open-Vocabulary Planning System for Robotic Manipulation
Mar 10, 2026We present TiPToP, an extensible modular system that combines pretrained vision foundation models with an existing Task and Motion Planner (TAMP) to solve multi-step manipulation tasks directly from input RGB images and natural-language instructions. Our system aims to be simple and easy-to-use: it can be installed and run on a standard DROID setup in under one hour and adapted to new embodiments with minimal effort. We evaluate TiPToP -- which requires zero robot data -- over 28 tabletop manipulation tasks in simulation and the real world and find it matches or outperforms $π_{0.5}\text{-DROID}$, a vision-language-action (VLA) model fine-tuned on 350 hours of embodiment-specific demonstrations. TiPToP's modular architecture enables us to analyze the system's failure modes at the component level. We analyze results from an evaluation of 173 trials and identify directions for improvement. We release TiPToP open-source to further research on modular manipulation systems and tighter integration between learning and planning. Project website and code: https://tiptop-robot.github.io
Differentiable GPU-Parallelized Task and Motion Planning
Nov 18, 2024


We present a differentiable optimization-based framework for Task and Motion Planning (TAMP) that is massively parallelizable on GPUs, enabling thousands of sampled seeds to be optimized simultaneously. Existing sampling-based approaches inherently disconnect the parameters by generating samples for each independently and combining them through composition and rejection, while optimization-based methods struggle with highly non-convex constraints and local optima. Our method treats TAMP constraint satisfaction as optimizing a batch of particles, each representing an assignment to a plan skeleton's continuous parameters. We represent the plan skeleton's constraints using differentiable cost functions, enabling us to compute the gradient of each particle and update it toward satisfying solutions. Our use of GPU parallelism better covers the parameter space through scale, increasing the likelihood of finding the global optima by exploring multiple basins through global sampling. We demonstrate that our algorithm can effectively solve a highly constrained Tetris packing problem using a Franka arm in simulation and deploy our planner on a real robot arm. Website: https://williamshen-nz.github.io/gpu-tamp
Searching for Optimal Runtime Assurance via Reachability and Reinforcement Learning
Oct 06, 2023A runtime assurance system (RTA) for a given plant enables the exercise of an untrusted or experimental controller while assuring safety with a backup (or safety) controller. The relevant computational design problem is to create a logic that assures safety by switching to the safety controller as needed, while maximizing some performance criteria, such as the utilization of the untrusted controller. Existing RTA design strategies are well-known to be overly conservative and, in principle, can lead to safety violations. In this paper, we formulate the optimal RTA design problem and present a new approach for solving it. Our approach relies on reward shaping and reinforcement learning. It can guarantee safety and leverage machine learning technologies for scalability. We have implemented this algorithm and present experimental results comparing our approach with state-of-the-art reachability and simulation-based RTA approaches in a number of scenarios using aircraft models in 3D space with complex safety requirements. Our approach can guarantee safety while increasing utilization of the experimental controller over existing approaches.
Distilled Feature Fields Enable Few-Shot Language-Guided Manipulation
Jul 27, 2023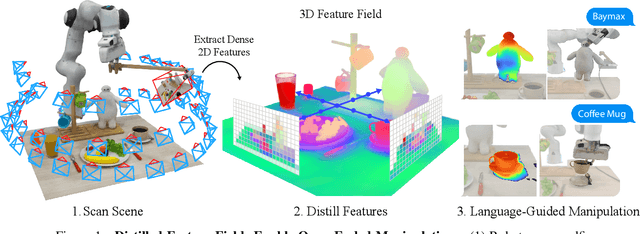
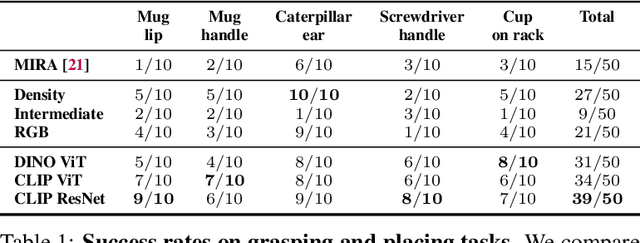
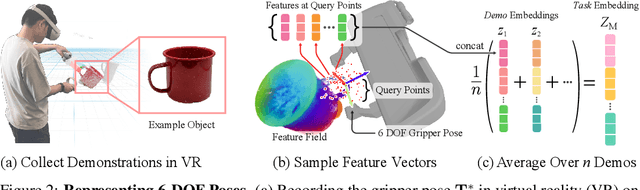
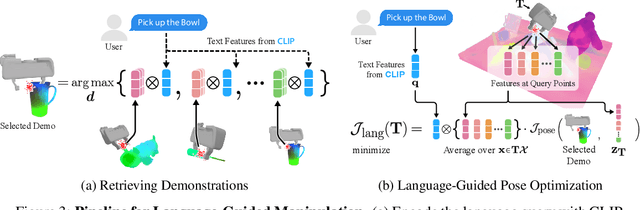
Self-supervised and language-supervised image models contain rich knowledge of the world that is important for generalization. Many robotic tasks, however, require a detailed understanding of 3D geometry, which is often lacking in 2D image features. This work bridges this 2D-to-3D gap for robotic manipulation by leveraging distilled feature fields to combine accurate 3D geometry with rich semantics from 2D foundation models. We present a few-shot learning method for 6-DOF grasping and placing that harnesses these strong spatial and semantic priors to achieve in-the-wild generalization to unseen objects. Using features distilled from a vision-language model, CLIP, we present a way to designate novel objects for manipulation via free-text natural language, and demonstrate its ability to generalize to unseen expressions and novel categories of objects.
Learning Domain-Independent Planning Heuristics with Hypergraph Networks
Nov 29, 2019
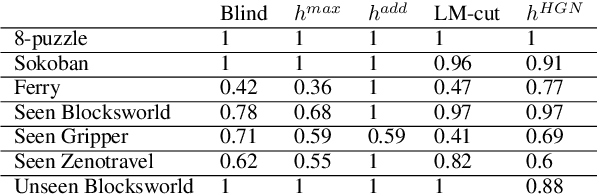
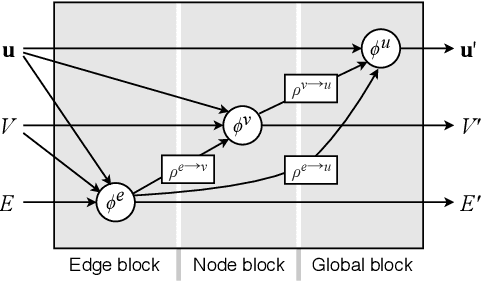

We present the first approach capable of learning domain-independent planning heuristics entirely from scratch. The heuristics we learn map the hypergraph representation of the delete-relaxation of the planning problem at hand, to a cost estimate that approximates that of the least-cost path from the current state to the goal through the hypergraph. We generalise Graph Networks to obtain a new framework for learning over hypergraphs, which we specialise to learn planning heuristics by training over state/value pairs obtained from optimal cost plans. Our experiments show that the resulting architecture, STRIPS-HGNs, is capable of learning heuristics that are competitive with existing delete-relaxation heuristics including LM-cut. We show that the heuristics we learn are able to generalise across different problems and domains, including to domains that were not seen during training.
Taskonomy: Disentangling Task Transfer Learning
Apr 23, 2018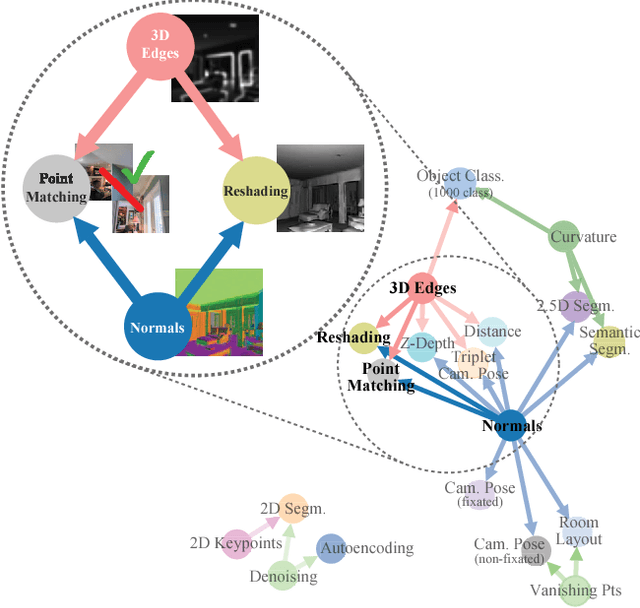
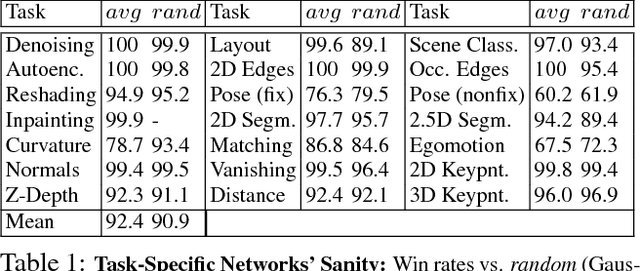


Do visual tasks have a relationship, or are they unrelated? For instance, could having surface normals simplify estimating the depth of an image? Intuition answers these questions positively, implying existence of a structure among visual tasks. Knowing this structure has notable values; it is the concept underlying transfer learning and provides a principled way for identifying redundancies across tasks, e.g., to seamlessly reuse supervision among related tasks or solve many tasks in one system without piling up the complexity. We proposes a fully computational approach for modeling the structure of space of visual tasks. This is done via finding (first and higher-order) transfer learning dependencies across a dictionary of twenty six 2D, 2.5D, 3D, and semantic tasks in a latent space. The product is a computational taxonomic map for task transfer learning. We study the consequences of this structure, e.g. nontrivial emerged relationships, and exploit them to reduce the demand for labeled data. For example, we show that the total number of labeled datapoints needed for solving a set of 10 tasks can be reduced by roughly 2/3 (compared to training independently) while keeping the performance nearly the same. We provide a set of tools for computing and probing this taxonomical structure including a solver that users can employ to devise efficient supervision policies for their use cases.
Feedback Networks
Aug 20, 2017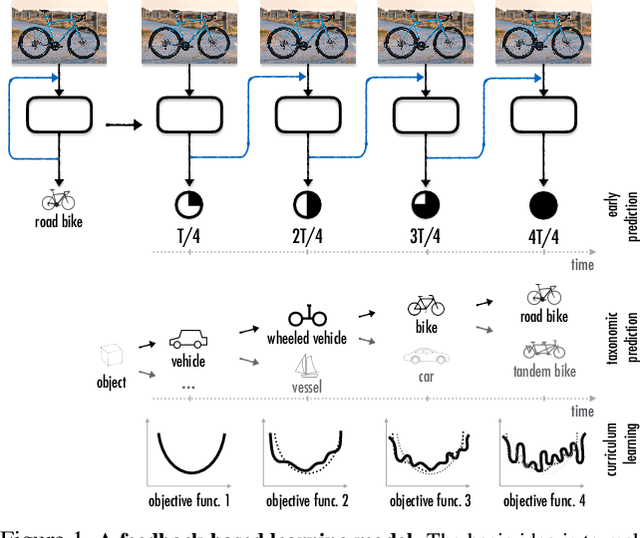
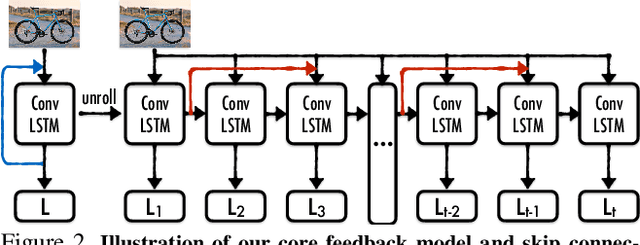
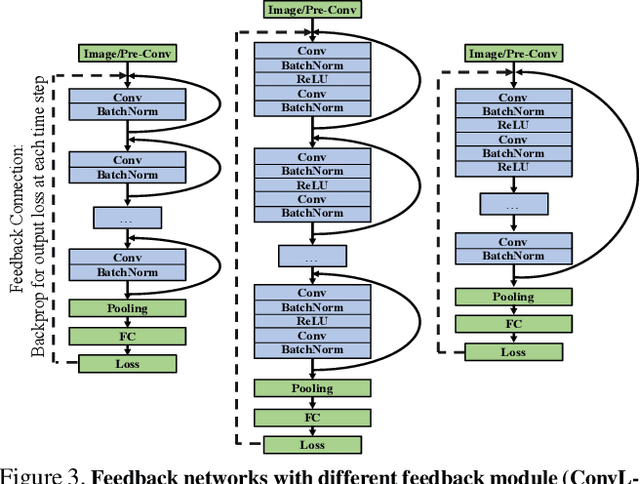
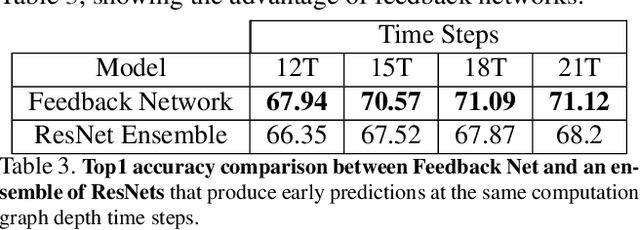
Currently, the most successful learning models in computer vision are based on learning successive representations followed by a decision layer. This is usually actualized through feedforward multilayer neural networks, e.g. ConvNets, where each layer forms one of such successive representations. However, an alternative that can achieve the same goal is a feedback based approach in which the representation is formed in an iterative manner based on a feedback received from previous iteration's output. We establish that a feedback based approach has several fundamental advantages over feedforward: it enables making early predictions at the query time, its output naturally conforms to a hierarchical structure in the label space (e.g. a taxonomy), and it provides a new basis for Curriculum Learning. We observe that feedback networks develop a considerably different representation compared to feedforward counterparts, in line with the aforementioned advantages. We put forth a general feedback based learning architecture with the endpoint results on par or better than existing feedforward networks with the addition of the above advantages. We also investigate several mechanisms in feedback architectures (e.g. skip connections in time) and design choices (e.g. feedback length). We hope this study offers new perspectives in quest for more natural and practical learning models.